 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Does Machine Identity Matter in Anomalous Sound Detection at Test Time?
Feb 18, 2026Anomalous sound detection (ASD) benchmarks typically assume that the identity of the monitored machine is known at test time and that recordings are evaluated in a machine-wise manner. However, in realistic monitoring scenarios with multiple known machines operating concurrently, test recordings may not be reliably attributable to a specific machine, and requiring machine identity imposes deployment constraints such as dedicated sensors per machine. To reveal performance degradations and method-specific differences in robustness that are hidden under standard machine-wise evaluation, we consider a minimal modification of the ASD evaluation protocol in which test recordings from multiple machines are merged and evaluated jointly without access to machine identity at inference time. Training data and evaluation metrics remain unchanged, and machine identity labels are used only for post hoc evaluation. Experiments with representative ASD methods show that relaxing this assumption reveals performance degradations and method-specific differences in robustness that are hidden under standard machine-wise evaluation, and that these degradations are strongly related to implicit machine identification accuracy.
SONAR: Self-Distilled Continual Pre-training for Domain Adaptive Audio Representation
Sep 19, 2025Self-supervised learning (SSL) on large-scale datasets like AudioSet has become the dominant paradigm for audio representation learning. While the continuous influx of new, unlabeled audio presents an opportunity to enrich these static representations, a naive approach is to retrain the model from scratch using all available data. However, this method is computationally prohibitive and discards the valuable knowledge embedded in the previously trained model weights. To address this inefficiency, we propose SONAR (Self-distilled cONtinual pre-training for domain adaptive Audio Representation), a continual pre-training framework built upon BEATs. SONAR effectively adapts to new domains while mitigating catastrophic forgetting by tackling three key challenges: implementing a joint sampling strategy for new and prior data, applying regularization to balance specificity and generality, and dynamically expanding the tokenizer codebook for novel acoustic patterns. Experiments across four distinct domains demonstrate that our method achieves both high adaptability and robust resistance to forgetting.
Context-Aware Query Refinement for Target Sound Extraction: Handling Partially Matched Queries
Sep 10, 2025



Target sound extraction (TSE) is the task of extracting a target sound specified by a query from an audio mixture. Much prior research has focused on the problem setting under the Fully Matched Query (FMQ) condition, where the query specifies only active sounds present in the mixture. However, in real-world scenarios, queries may include inactive sounds that are not present in the mixture. This leads to scenarios such as the Fully Unmatched Query (FUQ) condition, where only inactive sounds are specified in the query, and the Partially Matched Query (PMQ) condition, where both active and inactive sounds are specified. Among these conditions, the performance degradation under the PMQ condition has been largely overlooked. To achieve robust TSE under the PMQ condition, we propose context-aware query refinement. This method eliminates inactive classes from the query during inference based on the estimated sound class activity. Experimental results demonstrate that while conventional methods suffer from performance degradation under the PMQ condition, the proposed method effectively mitigates this degradation and achieves high robustness under diverse query conditions.
Prosodically Enhanced Foreign Accent Simulation by Discrete Token-based Resynthesis Only with Native Speech Corpora
May 22, 2025Recently, a method for synthesizing foreign-accented speech only with native speech data using discrete tokens obtained from self-supervised learning (SSL) models was proposed. Considering limited availability of accented speech data, this method is expected to make it much easier to simulate foreign accents. By using the synthesized accented speech as listening materials for humans or training data for automatic speech recognition (ASR), both of them will acquire higher robustness against foreign accents. However, the previous method has a fatal flaw that it cannot reproduce duration-related accents. Durational accents are commonly seen when L2 speakers, whose native language has syllable-timed or mora-timed rhythm, speak stress-timed languages, such as English. In this paper, we integrate duration modification to the previous method to simulate foreign accents more accurately. Experiments show that the proposed method successfully replicates durational accents seen in real L2 speech.
Discrete Tokens Exhibit Interlanguage Speech Intelligibility Benefit: an Analytical Study Towards Accent-robust ASR Only with Native Speech Data
May 22, 2025



In this study, we gained insight that contributes to achieving accent-robust ASR using only native speech data. In human perception of non-native speech, the phenomenon known as "interlanguage speech intelligibility benefit" (ISIB) is observed, where non-native listeners who share the native language with the speaker understand the speech better compared even to native listeners. Based on the idea that discrete tokens extracted from self-supervised learning (SSL) models represent the human perception of speech, we conducted an analytical study on the robustness of discrete token-based ASR to non-native speech, varying the language used for training the tokenization, which is viewed as a technical implementation of ISIB. The results showed that ISIB actually occurred in the discrete token-based ASR. Since our approach relies only on native speech data to simulate the behavior of human perception, it is expected to be applicable to a wide range of accents for which speech data is scarce.
Formula-Supervised Sound Event Detection: Pre-Training Without Real Data
Apr 06, 2025In this paper, we propose a novel formula-driven supervised learning (FDSL) framework for pre-training an environmental sound analysis model by leveraging acoustic signals parametrically synthesized through formula-driven methods. Specifically, we outline detailed procedures and evaluate their effectiveness for sound event detection (SED). The SED task, which involves estimating the types and timings of sound events, is particularly challenged by the difficulty of acquiring a sufficient quantity of accurately labeled training data. Moreover, it is well known that manually annotated labels often contain noises and are significantly influenced by the subjective judgment of annotators. To address these challenges, we propose a novel pre-training method that utilizes a synthetic dataset, Formula-SED, where acoustic data are generated solely based on mathematical formulas. The proposed method enables large-scale pre-training by using the synthesis parameters applied at each time step as ground truth labels, thereby eliminating label noise and bias. We demonstrate that large-scale pre-training with Formula-SED significantly enhances model accuracy and accelerates training, as evidenced by our results in the DESED dataset used for DCASE2023 Challenge Task 4. The project page is at https://yutoshibata07.github.io/Formula-SED/
Handling Domain Shifts for Anomalous Sound Detection: A Review of DCASE-Related Work
Mar 13, 2025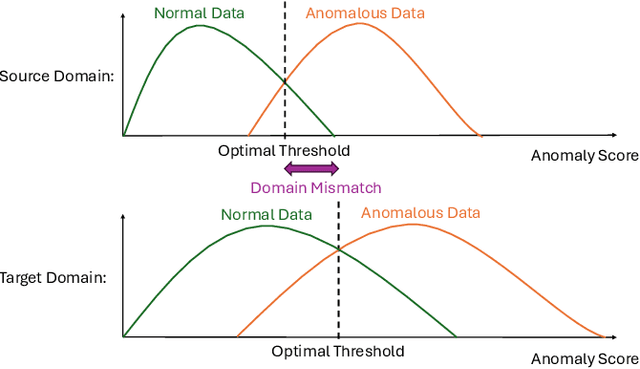
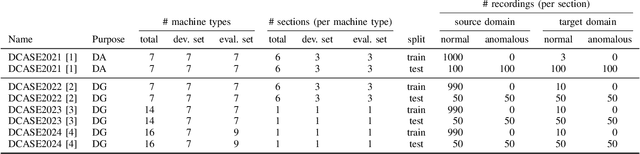
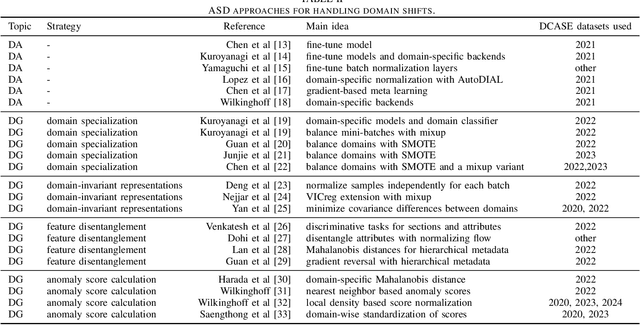
When detecting anomalous sounds in complex environments, one of the main difficulties is that trained models must be sensitive to subtle differences in monitored target signals, while many practical applications also require them to be insensitive to changes in acoustic domains. Examples of such domain shifts include changing the type of microphone or the location of acoustic sensors, which can have a much stronger impact on the acoustic signal than subtle anomalies themselves. Moreover, users typically aim to train a model only on source domain data, which they may have a relatively large collection of, and they hope that such a trained model will be able to generalize well to an unseen target domain by providing only a minimal number of samples to characterize the acoustic signals in that domain. In this work, we review and discuss recent publications focusing on this domain generalization problem for anomalous sound detection in the context of the DCASE challenges on acoustic machine condition monitoring.
Sound Scene Synthesis at the DCASE 2024 Challenge
Jan 15, 2025This paper presents Task 7 at the DCASE 2024 Challenge: sound scene synthesis. Recent advances in sound synthesis and generative models have enabled the creation of realistic and diverse audio content. We introduce a standardized evaluation framework for comparing different sound scene synthesis systems, incorporating both objective and subjective metrics. The challenge attracted four submissions, which are evaluated using the Fr\'echet Audio Distance (FAD) and human perceptual ratings. Our analysis reveals significant insights into the current capabilities and limitations of sound scene synthesis systems, while also highlighting areas for future improvement in this rapidly evolving field.
Trainingless Adaptation of Pretrained Models for Environmental Sound Classification
Dec 23, 2024Deep neural network (DNN)-based models for environmental sound classification are not robust against a domain to which training data do not belong, that is, out-of-distribution or unseen data. To utilize pretrained models for the unseen domain, adaptation methods, such as finetuning and transfer learning, are used with rich computing resources, e.g., the graphical processing unit (GPU). However, it is becoming more difficult to keep up with research trends for those who have poor computing resources because state-of-the-art models are becoming computationally resource-intensive. In this paper, we propose a trainingless adaptation method for pretrained models for environmental sound classification. To introduce the trainingless adaptation method, we first propose an operation of recovering time--frequency-ish (TF-ish) structures in intermediate layers of DNN models. We then propose the trainingless frequency filtering method for domain adaptation, which is not a gradient-based optimization widely used. The experiments conducted using the ESC-50 dataset show that the proposed adaptation method improves the classification accuracy by 20.40 percentage points compared with the conventional method.
DOA-Aware Audio-Visual Self-Supervised Learning for Sound Event Localization and Detection
Oct 30, 2024This paper describes sound event localization and detection (SELD) for spatial audio recordings captured by firstorder ambisonics (FOA) microphones. In this task, one may train a deep neural network (DNN) using FOA data annotated with the classes and directions of arrival (DOAs) of sound events. However, the performance of this approach is severely bounded by the amount of annotated data. To overcome this limitation, we propose a novel method of pretraining the feature extraction part of the DNN in a self-supervised manner. We use spatial audio-visual recordings abundantly available as virtual reality contents. Assuming that sound objects are concurrently observed by the FOA microphones and the omni-directional camera, we jointly train audio and visual encoders with contrastive learning such that the audio and visual embeddings of the same recording and DOA are made close. A key feature of our method is that the DOA-wise audio embeddings are jointly extracted from the raw audio data, while the DOA-wise visual embeddings are separately extracted from the local visual crops centered on the corresponding DOA. This encourages the latent features of the audio encoder to represent both the classes and DOAs of sound events. The experiment using the DCASE2022 Task 3 dataset of 20 hours shows non-annotated audio-visual recordings of 100 hours reduced the error score of SELD from 36.4 pts to 34.9 pts.