 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSound Scene Synthesis at the DCASE 2024 Challenge
Jan 15, 2025This paper presents Task 7 at the DCASE 2024 Challenge: sound scene synthesis. Recent advances in sound synthesis and generative models have enabled the creation of realistic and diverse audio content. We introduce a standardized evaluation framework for comparing different sound scene synthesis systems, incorporating both objective and subjective metrics. The challenge attracted four submissions, which are evaluated using the Fr\'echet Audio Distance (FAD) and human perceptual ratings. Our analysis reveals significant insights into the current capabilities and limitations of sound scene synthesis systems, while also highlighting areas for future improvement in this rapidly evolving field.
Vision Language Models Are Few-Shot Audio Spectrogram Classifiers
Nov 18, 2024We demonstrate that vision language models (VLMs) are capable of recognizing the content in audio recordings when given corresponding spectrogram images. Specifically, we instruct VLMs to perform audio classification tasks in a few-shot setting by prompting them to classify a spectrogram image given example spectrogram images of each class. By carefully designing the spectrogram image representation and selecting good few-shot examples, we show that GPT-4o can achieve 59.00% cross-validated accuracy on the ESC-10 environmental sound classification dataset. Moreover, we demonstrate that VLMs currently outperform the only available commercial audio language model with audio understanding capabilities (Gemini-1.5) on the equivalent audio classification task (59.00% vs. 49.62%), and even perform slightly better than human experts on visual spectrogram classification (73.75% vs. 72.50% on first fold). We envision two potential use cases for these findings: (1) combining the spectrogram and language understanding capabilities of VLMs for audio caption augmentation, and (2) posing visual spectrogram classification as a challenge task for VLMs.
Challenge on Sound Scene Synthesis: Evaluating Text-to-Audio Generation
Oct 23, 2024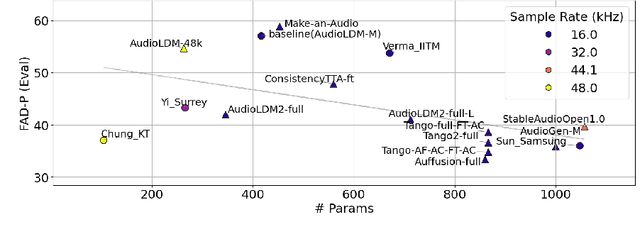
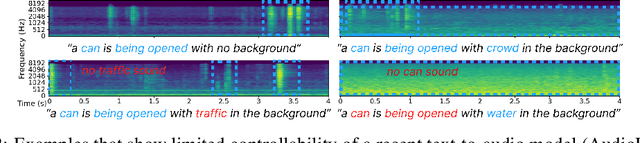
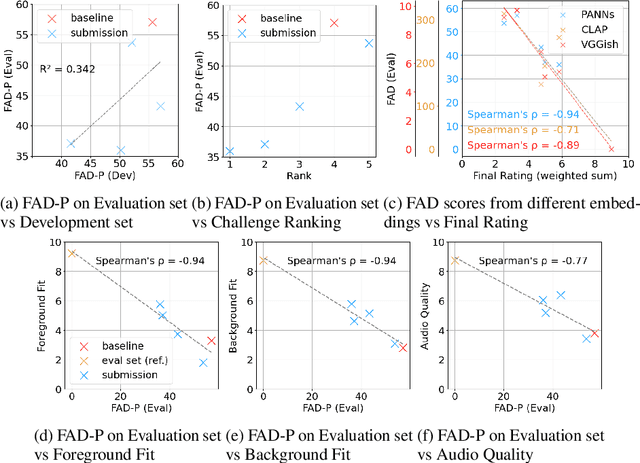
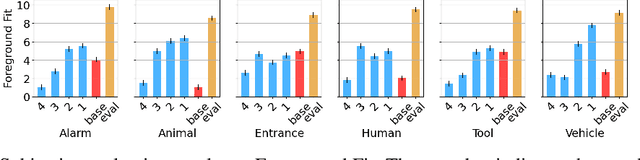
Despite significant advancements in neural text-to-audio generation, challenges persist in controllability and evaluation. This paper addresses these issues through the Sound Scene Synthesis challenge held as part of the Detection and Classification of Acoustic Scenes and Events 2024. We present an evaluation protocol combining objective metric, namely Fr\'echet Audio Distance, with perceptual assessments, utilizing a structured prompt format to enable diverse captions and effective evaluation. Our analysis reveals varying performance across sound categories and model architectures, with larger models generally excelling but innovative lightweight approaches also showing promise. The strong correlation between objective metrics and human ratings validates our evaluation approach. We discuss outcomes in terms of audio quality, controllability, and architectural considerations for text-to-audio synthesizers, providing direction for future research.
Detection of Deepfake Environmental Audio
Mar 26, 2024


With the ever-rising quality of deep generative models, it is increasingly important to be able to discern whether the audio data at hand have been recorded or synthesized. Although the detection of fake speech signals has been studied extensively, this is not the case for the detection of fake environmental audio. We propose a simple and efficient pipeline for detecting fake environmental sounds based on the CLAP audio embedding. We evaluate this detector using audio data from the 2023 DCASE challenge task on Foley sound synthesis. Our experiments show that fake sounds generated by 44 state-of-the-art synthesizers can be detected on average with 98% accuracy. We show that using an audio embedding learned on environmental audio is beneficial over a standard VGGish one as it provides a 10% increase in detection performance. Informal listening to Incorrect Negative examples demonstrates audible features of fake sounds missed by the detector such as distortion and implausible background noise.
Correlation of Fréchet Audio Distance With Human Perception of Environmental Audio Is Embedding Dependant
Mar 26, 2024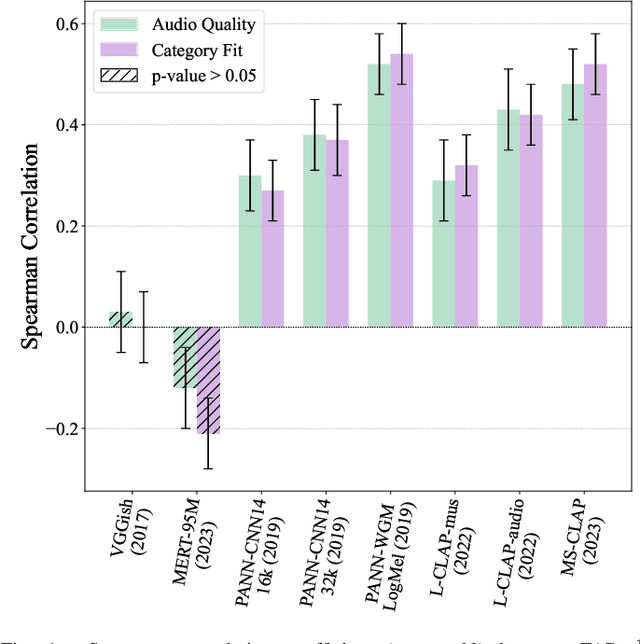
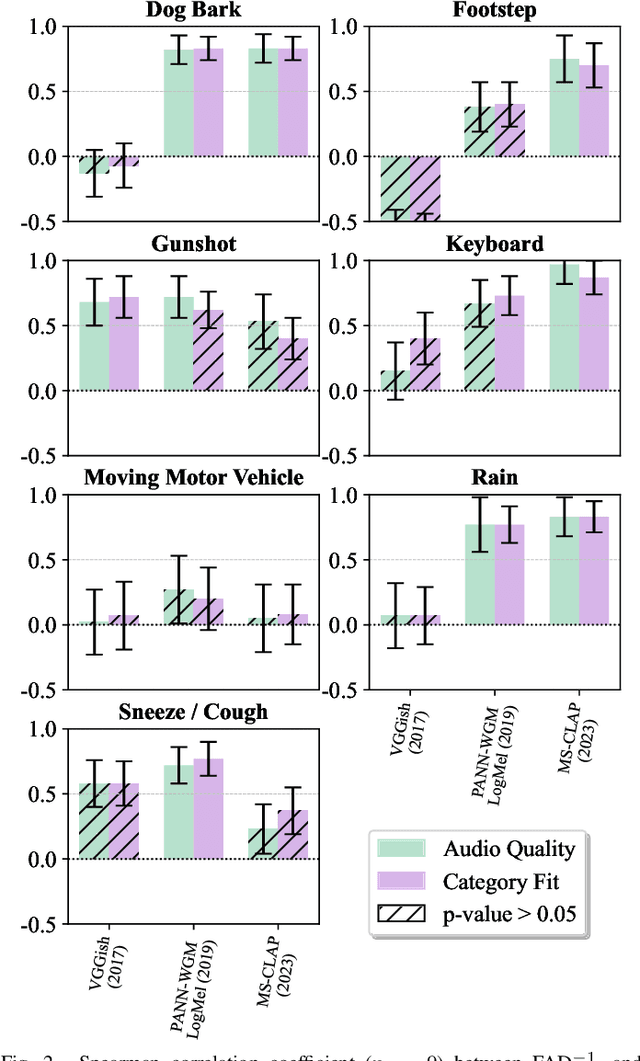
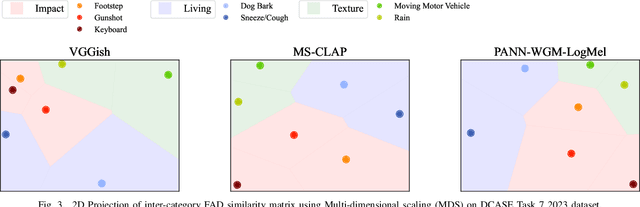
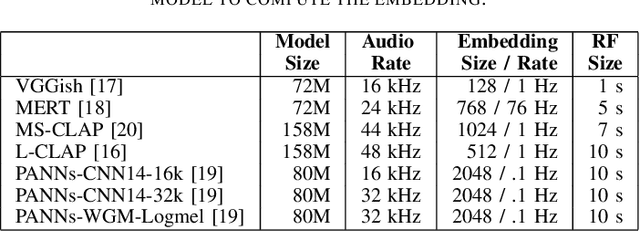
This paper explores whether considering alternative domain-specific embeddings to calculate the Fr\'echet Audio Distance (FAD) metric can help the FAD to correlate better with perceptual ratings of environmental sounds. We used embeddings from VGGish, PANNs, MS-CLAP, L-CLAP, and MERT, which are tailored for either music or environmental sound evaluation. The FAD scores were calculated for sounds from the DCASE 2023 Task 7 dataset. Using perceptual data from the same task, we find that PANNs-WGM-LogMel produces the best correlation between FAD scores and perceptual ratings of both audio quality and perceived fit with a Spearman correlation higher than 0.5. We also find that music-specific embeddings resulted in significantly lower results. Interestingly, VGGish, the embedding used for the original Fr\'echet calculation, yielded a correlation below 0.1. These results underscore the critical importance of the choice of embedding for the FAD metric design.
Synergy between human and machine approaches to sound/scene recognition and processing: An overview of ICASSP special session
Feb 24, 2023Machine Listening, as usually formalized, attempts to perform a task that is, from our perspective, fundamentally human-performable, and performed by humans. Current automated models of Machine Listening vary from purely data-driven approaches to approaches imitating human systems. In recent years, the most promising approaches have been hybrid in that they have used data-driven approaches informed by models of the perceptual, cognitive, and semantic processes of the human system. Not only does the guidance provided by models of human perception and domain knowledge enable better, and more generalizable Machine Listening, in the converse, the lessons learned from these models may be used to verify or improve our models of human perception themselves. This paper summarizes advances in the development of such hybrid approaches, ranging from Machine Listening models that are informed by models of peripheral (human) auditory processes, to those that employ or derive semantic information encoded in relations between sounds. The research described herein was presented in a special session on "Synergy between human and machine approaches to sound/scene recognition and processing" at the 2023 ICASSP meeting.
Identifying Actions for Sound Event Classification
Apr 26, 2021
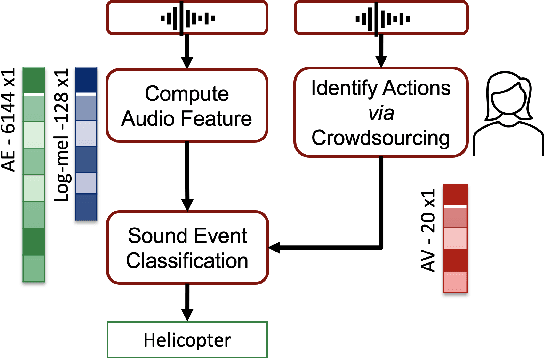
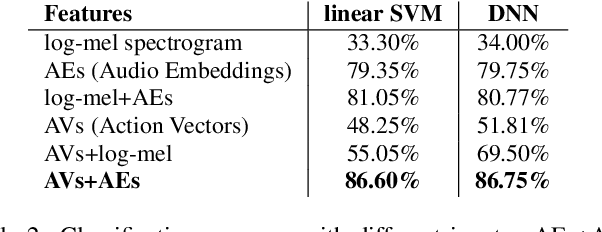

In Psychology, actions are paramount for humans to perceive and separate sound events. In Machine Learning (ML), action recognition achieves high accuracy; however, it has not been asked if identifying actions can benefit Sound Event Classification (SEC), as opposed to mapping the audio directly to a sound event. Therefore, we propose a new Psychology-inspired approach for SEC that includes identification of actions via human listeners. To achieve this goal, we used crowdsourcing to have listeners identify 20 actions that in isolation or in combination may have produced any of the 50 sound events in the well-studied dataset ESC-50. The resulting annotations for each audio recording relate actions to a database of sound events for the first time~\footnote{Annotations will be released after revision.}. The annotations were used to create semantic representations called Action Vectors (AVs). We evaluated SEC by comparing the AVs with two types of audio features -- log-mel spectrograms and state of the art audio embeddings. Because audio features and AVs capture different abstractions of the acoustic content, we combined them and achieved one of the highest reported accuracies (86.75%) in ESC-50, showing that Psychology-inspired approaches can improve SEC.