 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenge on Sound Scene Synthesis: Evaluating Text-to-Audio Generation
Paper and Code
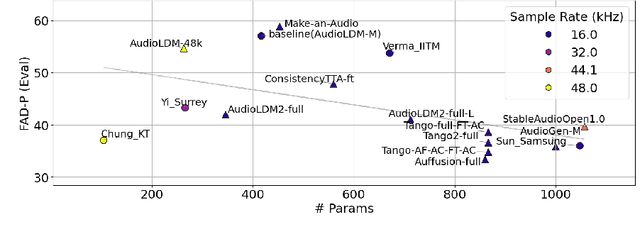
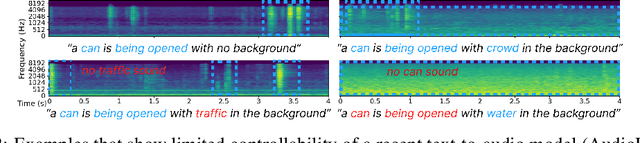
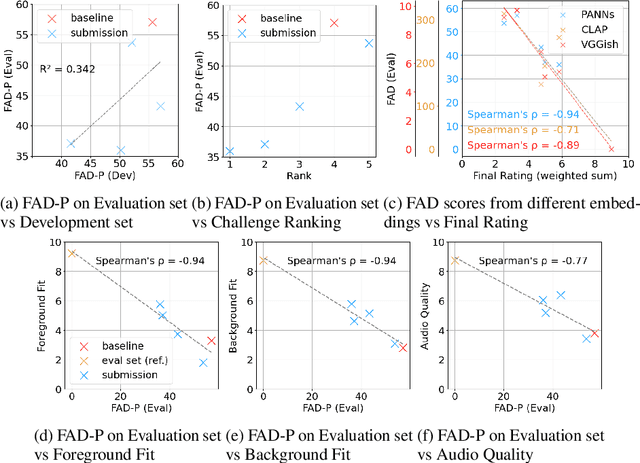
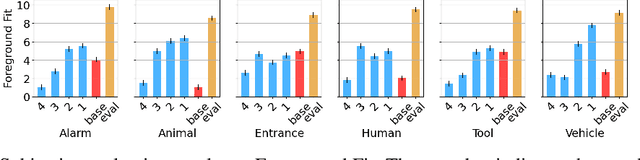
Despite significant advancements in neural text-to-audio generation, challenges persist in controllability and evaluation. This paper addresses these issues through the Sound Scene Synthesis challenge held as part of the Detection and Classification of Acoustic Scenes and Events 2024. We present an evaluation protocol combining objective metric, namely Fr\'echet Audio Distance, with perceptual assessments, utilizing a structured prompt format to enable diverse captions and effective evaluation. Our analysis reveals varying performance across sound categories and model architectures, with larger models generally excelling but innovative lightweight approaches also showing promise. The strong correlation between objective metrics and human ratings validates our evaluation approach. We discuss outcomes in terms of audio quality, controllability, and architectural considerations for text-to-audio synthesizers, providing direction for future research.