 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Adapt to Domain Shifts with Few-shot Samples in Anomalous Sound Detection
Apr 05, 2022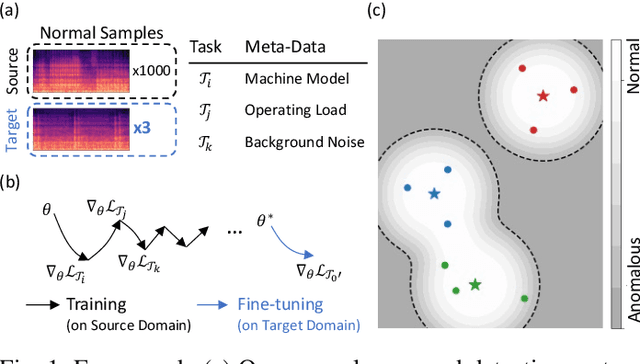


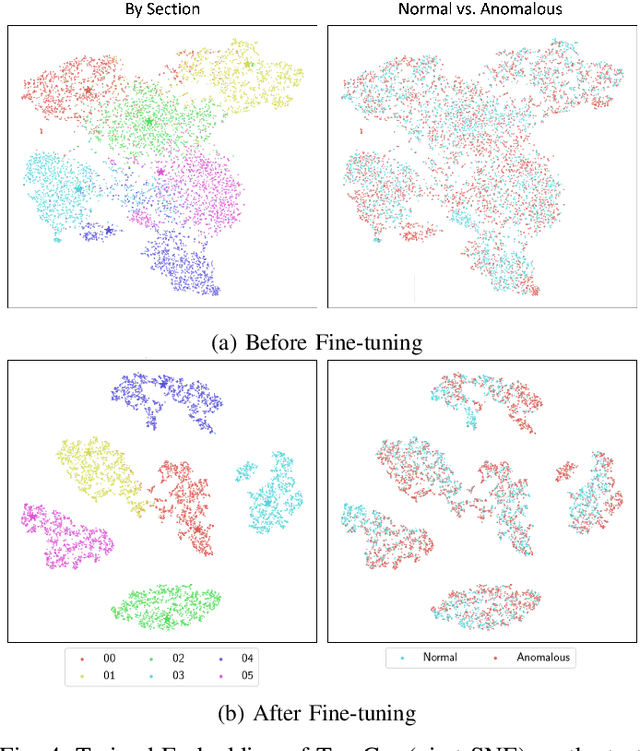
Anomaly detection has many important applications, such as monitoring industrial equipment. Despite recent advances in anomaly detection with deep-learning methods, it is unclear how existing solutions would perform under out-of-distribution scenarios, e.g., due to shifts in machine load or environmental noise. Grounded in the application of machine health monitoring, we propose a framework that adapts to new conditions with few-shot samples. Building upon prior work, we adopt a classification-based approach for anomaly detection and show its equivalence to mixture density estimation of the normal samples. We incorporate an episodic training procedure to match the few-shot setting during inference. We define multiple auxiliary classification tasks based on meta-information and leverage gradient-based meta-learning to improve generalization to different shifts. We evaluate our proposed method on a recently-released dataset of audio measurements from different machine types. It improved upon two baselines by around 10% and is on par with best-performing model reported on the dataset.
Identifying Actions for Sound Event Classification
Apr 26, 2021
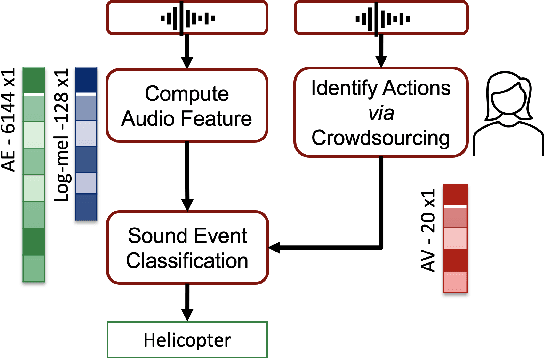
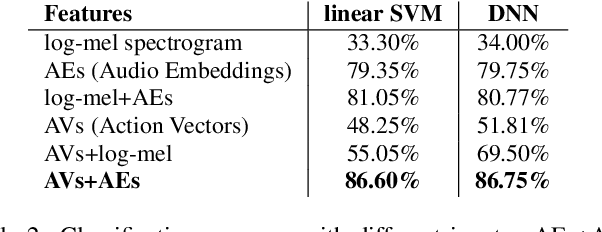

In Psychology, actions are paramount for humans to perceive and separate sound events. In Machine Learning (ML), action recognition achieves high accuracy; however, it has not been asked if identifying actions can benefit Sound Event Classification (SEC), as opposed to mapping the audio directly to a sound event. Therefore, we propose a new Psychology-inspired approach for SEC that includes identification of actions via human listeners. To achieve this goal, we used crowdsourcing to have listeners identify 20 actions that in isolation or in combination may have produced any of the 50 sound events in the well-studied dataset ESC-50. The resulting annotations for each audio recording relate actions to a database of sound events for the first time~\footnote{Annotations will be released after revision.}. The annotations were used to create semantic representations called Action Vectors (AVs). We evaluated SEC by comparing the AVs with two types of audio features -- log-mel spectrograms and state of the art audio embeddings. Because audio features and AVs capture different abstractions of the acoustic content, we combined them and achieved one of the highest reported accuracies (86.75%) in ESC-50, showing that Psychology-inspired approaches can improve SEC.
A Comparison of deep learning methods for environmental sound
Mar 20, 2017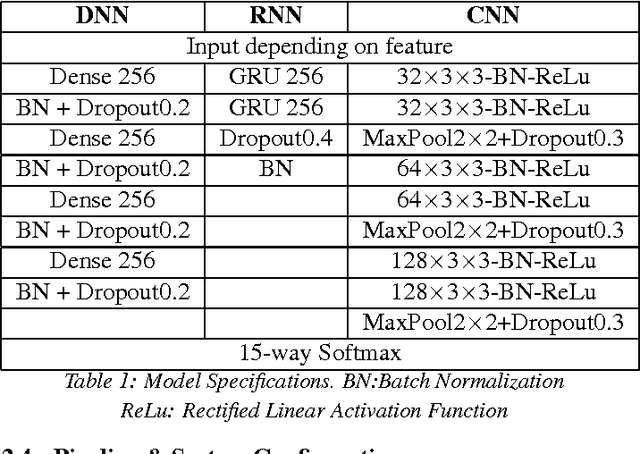
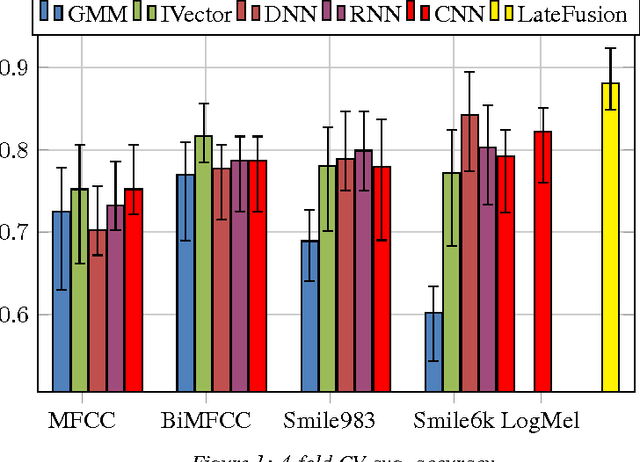
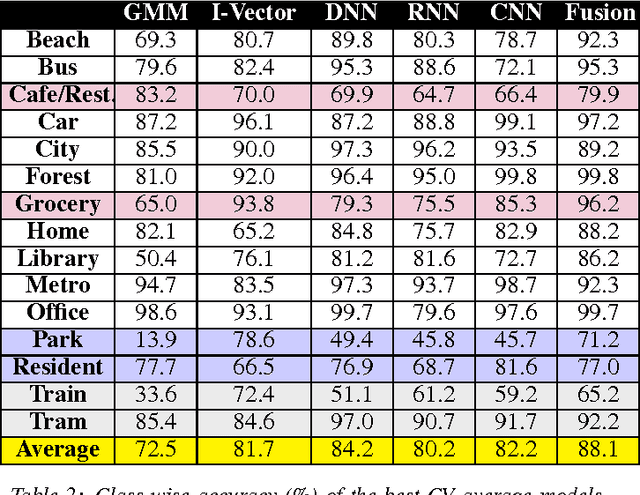
Environmental sound detection is a challenging application of machine learning because of the noisy nature of the signal, and the small amount of (labeled) data that is typically available. This work thus presents a comparison of several state-of-the-art Deep Learning models on the IEEE challenge on Detection and Classification of Acoustic Scenes and Events (DCASE) 2016 challenge task and data, classifying sounds into one of fifteen common indoor and outdoor acoustic scenes, such as bus, cafe, car, city center, forest path, library, train, etc. In total, 13 hours of stereo audio recordings are available, making this one of the largest datasets available. We perform experiments on six sets of features, including standard Mel-frequency cepstral coefficients (MFCC), Binaural MFCC, log Mel-spectrum and two different large- scale temporal pooling features extracted using OpenSMILE. On these features, we apply five models: Gaussian Mixture Model (GMM), Deep Neural Network (DNN), Recurrent Neural Network (RNN), Convolutional Deep Neural Net- work (CNN) and i-vector. Using the late-fusion approach, we improve the performance of the baseline 72.5% by 15.6% in 4-fold Cross Validation (CV) avg. accuracy and 11% in test accuracy, which matches the best result of the DCASE 2016 challenge. With large feature sets, deep neural network models out- perform traditional methods and achieve the best performance among all the studied methods. Consistent with other work, the best performing single model is the non-temporal DNN model, which we take as evidence that sounds in the DCASE challenge do not exhibit strong temporal dynamics.
* 5 pages including reference
Learning Filter Banks Using Deep Learning For Acoustic Signals
Nov 29, 2016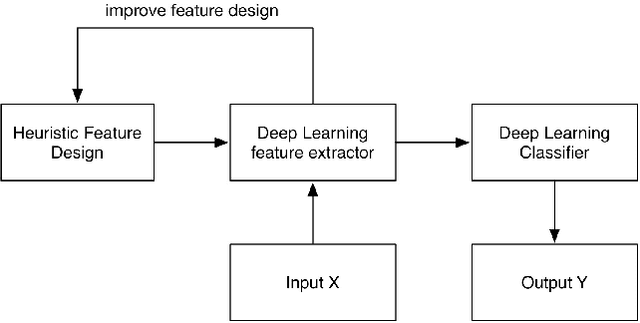
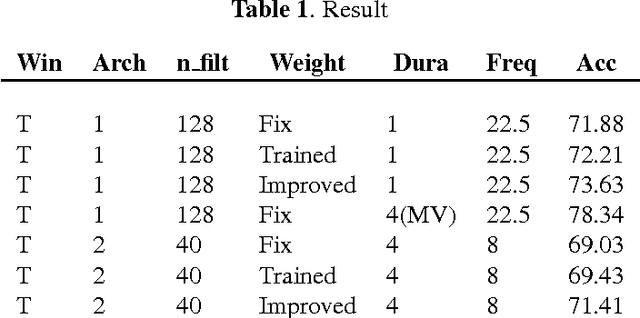
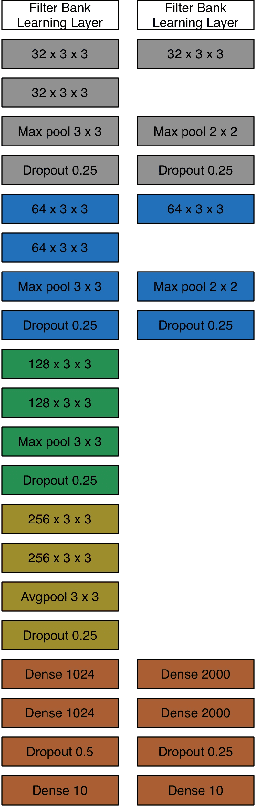

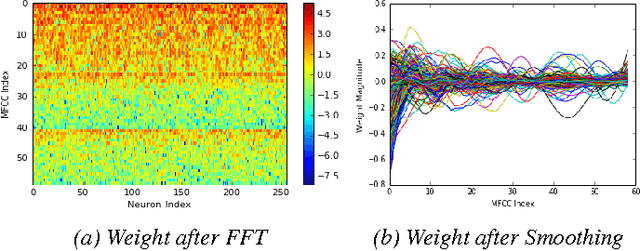
Designing appropriate features for acoustic event recognition tasks is an active field of research. Expressive features should both improve the performance of the tasks and also be interpret-able. Currently, heuristically designed features based on the domain knowledge requires tremendous effort in hand-crafting, while features extracted through deep network are difficult for human to interpret. In this work, we explore the experience guided learning method for designing acoustic features. This is a novel hybrid approach combining both domain knowledge and purely data driven feature designing. Based on the procedure of log Mel-filter banks, we design a filter bank learning layer. We concatenate this layer with a convolutional neural network (CNN) model. After training the network, the weight of the filter bank learning layer is extracted to facilitate the design of acoustic features. We smooth the trained weight of the learning layer and re-initialize it in filter bank learning layer as audio feature extractor. For the environmental sound recognition task based on the Urban- sound8K dataset, the experience guided learning leads to a 2% accuracy improvement compared with the fixed feature extractors (the log Mel-filter bank). The shape of the new filter banks are visualized and explained to prove the effectiveness of the feature design process.
Very Deep Convolutional Neural Networks for Raw Waveforms
Oct 01, 2016
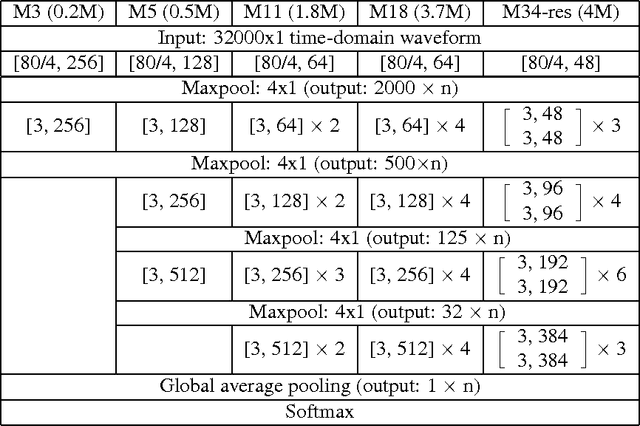
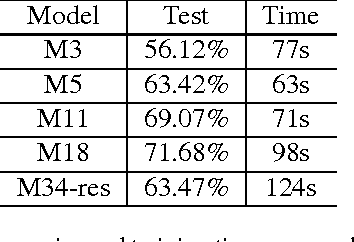
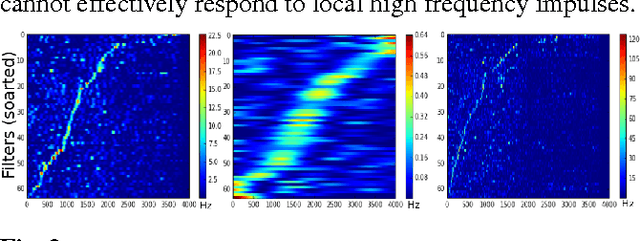
Learning acoustic models directly from the raw waveform data with minimal processing is challenging. Current waveform-based models have generally used very few (~2) convolutional layers, which might be insufficient for building high-level discriminative features. In this work, we propose very deep convolutional neural networks (CNNs) that directly use time-domain waveforms as inputs. Our CNNs, with up to 34 weight layers, are efficient to optimize over very long sequences (e.g., vector of size 32000), necessary for processing acoustic waveforms. This is achieved through batch normalization, residual learning, and a careful design of down-sampling in the initial layers. Our networks are fully convolutional, without the use of fully connected layers and dropout, to maximize representation learning. We use a large receptive field in the first convolutional layer to mimic bandpass filters, but very small receptive fields subsequently to control the model capacity. We demonstrate the performance gains with the deeper models. Our evaluation shows that the CNN with 18 weight layers outperform the CNN with 3 weight layers by over 15% in absolute accuracy for an environmental sound recognition task and matches the performance of models using log-mel features.