 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignal-Driven Observation for Long-Horizon Web Agents
Jun 04, 2026Web agents operating over long horizons ingest raw DOM and accessibility trees -- routinely tens of thousands of tokens -- at every action step, causing progressive context degradation that erodes reasoning well before tasks complete. We argue that this coupling of observation frequency to action frequency is an architectural mistake. Drawing on the insight from Recursive Language Models that querying a document outperforms reading it wholesale, we propose Signal-Driven Observation (SDO): a dedicated sub-call reads the full DOM but returns only task-relevant elements and their selectors, and is re-invoked only when a lightweight signal detector fires -- triggered by URL transitions, newly visible interactive elements, action failures, or exogenous browser events. We outline the open problems SDO introduces and call on the community to treat observation compression as a core architectural decision in web agent design.
UCSC at SemEval-2025 Task 3: Context, Models and Prompt Optimization for Automated Hallucination Detection in LLM Output
May 05, 2025Hallucinations pose a significant challenge for large language models when answering knowledge-intensive queries. As LLMs become more widely adopted, it is crucial not only to detect if hallucinations occur but also to pinpoint exactly where in the LLM output they occur. SemEval 2025 Task 3, Mu-SHROOM: Multilingual Shared-task on Hallucinations and Related Observable Overgeneration Mistakes, is a recent effort in this direction. This paper describes the UCSC system submission to the shared Mu-SHROOM task. We introduce a framework that first retrieves relevant context, next identifies false content from the answer, and finally maps them back to spans in the LLM output. The process is further enhanced by automatically optimizing prompts. Our system achieves the highest overall performance, ranking #1 in average position across all languages. We release our code and experiment results.
ProSLM : A Prolog Synergized Language Model for explainable Domain Specific Knowledge Based Question Answering
Sep 17, 2024Neurosymbolic approaches can add robustness to opaque neural systems by incorporating explainable symbolic representations. However, previous approaches have not used formal logic to contextualize queries to and validate outputs of large language models (LLMs). We propose \systemname{}, a novel neurosymbolic framework, to improve the robustness and reliability of LLMs in question-answering tasks. We provide \systemname{} with a domain-specific knowledge base, a logical reasoning system, and an integration to an existing LLM. This framework has two capabilities (1) context gathering: generating explainable and relevant context for a given query, and (2) validation: confirming and validating the factual accuracy of a statement in accordance with a knowledge base (KB). Our work opens a new area of neurosymbolic generative AI text validation and user personalization.
* Accepted at NeSy 2024
Don't Believe Everything You Read: Enhancing Summarization Interpretability through Automatic Identification of Hallucinations in Large Language Models
Dec 22, 2023


Large Language Models (LLMs) are adept at text manipulation -- tasks such as machine translation and text summarization. However, these models can also be prone to hallucination, which can be detrimental to the faithfulness of any answers that the model provides. Recent works in combating hallucinations in LLMs deal with identifying hallucinated sentences and categorizing the different ways in which models hallucinate. This paper takes a deep dive into LLM behavior with respect to hallucinations, defines a token-level approach to identifying different kinds of hallucinations, and further utilizes this token-level tagging to improve the interpretability and faithfulness of LLMs in dialogue summarization tasks. Through this, the paper presents a new, enhanced dataset and a new training paradigm.
Online Continual Learning of End-to-End Speech Recognition Models
Jul 11, 2022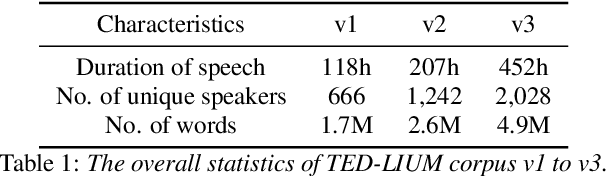
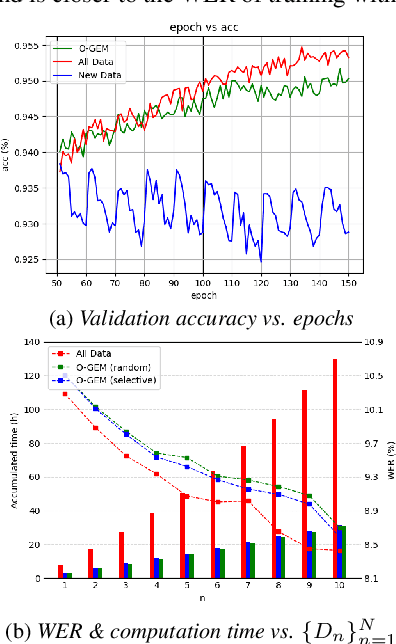
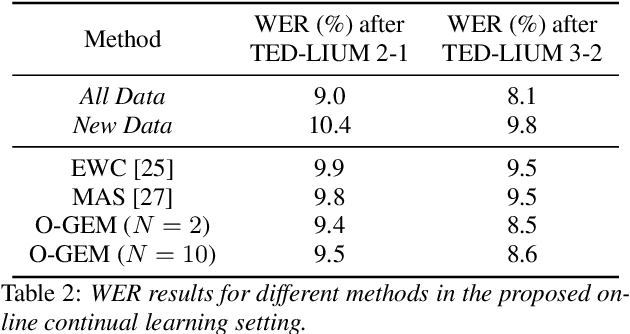
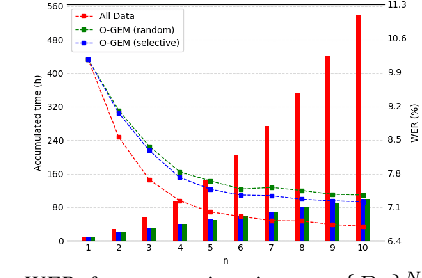
Continual Learning, also known as Lifelong Learning, aims to continually learn from new data as it becomes available. While prior research on continual learning in automatic speech recognition has focused on the adaptation of models across multiple different speech recognition tasks, in this paper we propose an experimental setting for \textit{online continual learning} for automatic speech recognition of a single task. Specifically focusing on the case where additional training data for the same task becomes available incrementally over time, we demonstrate the effectiveness of performing incremental model updates to end-to-end speech recognition models with an online Gradient Episodic Memory (GEM) method. Moreover, we show that with online continual learning and a selective sampling strategy, we can maintain an accuracy that is similar to retraining a model from scratch while requiring significantly lower computation costs. We have also verified our method with self-supervised learning (SSL) features.
Branchformer: Parallel MLP-Attention Architectures to Capture Local and Global Context for Speech Recognition and Understanding
Jul 06, 2022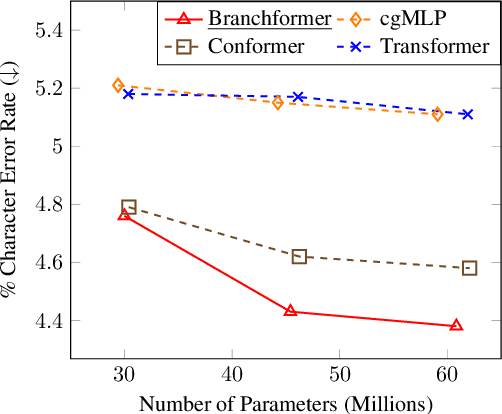
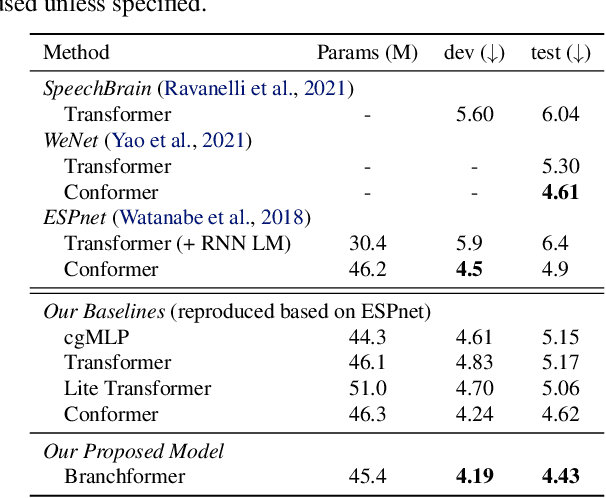
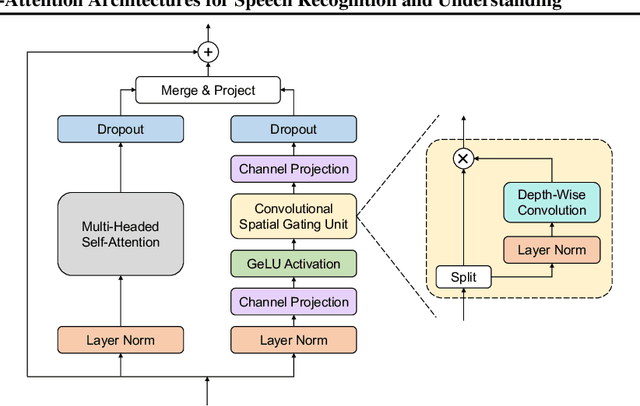
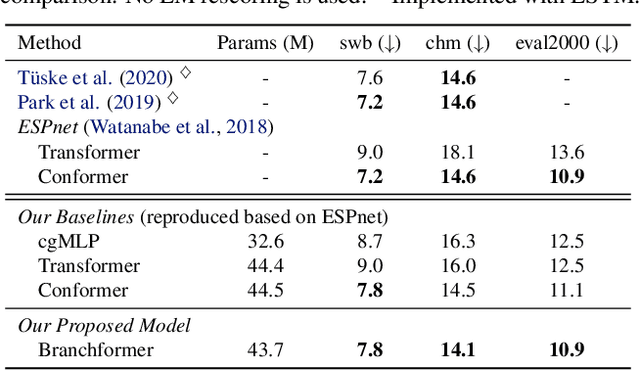
Conformer has proven to be effective in many speech processing tasks. It combines the benefits of extracting local dependencies using convolutions and global dependencies using self-attention. Inspired by this, we propose a more flexible, interpretable and customizable encoder alternative, Branchformer, with parallel branches for modeling various ranged dependencies in end-to-end speech processing. In each encoder layer, one branch employs self-attention or its variant to capture long-range dependencies, while the other branch utilizes an MLP module with convolutional gating (cgMLP) to extract local relationships. We conduct experiments on several speech recognition and spoken language understanding benchmarks. Results show that our model outperforms both Transformer and cgMLP. It also matches with or outperforms state-of-the-art results achieved by Conformer. Furthermore, we show various strategies to reduce computation thanks to the two-branch architecture, including the ability to have variable inference complexity in a single trained model. The weights learned for merging branches indicate how local and global dependencies are utilized in different layers, which benefits model designing.
Identifying Actions for Sound Event Classification
Apr 26, 2021
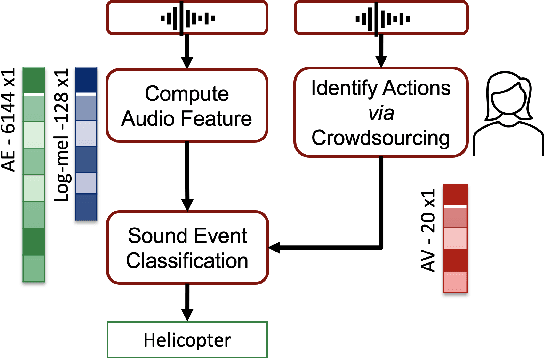
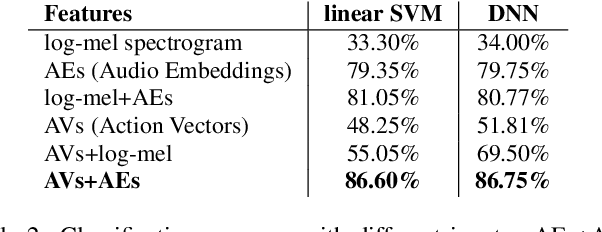

In Psychology, actions are paramount for humans to perceive and separate sound events. In Machine Learning (ML), action recognition achieves high accuracy; however, it has not been asked if identifying actions can benefit Sound Event Classification (SEC), as opposed to mapping the audio directly to a sound event. Therefore, we propose a new Psychology-inspired approach for SEC that includes identification of actions via human listeners. To achieve this goal, we used crowdsourcing to have listeners identify 20 actions that in isolation or in combination may have produced any of the 50 sound events in the well-studied dataset ESC-50. The resulting annotations for each audio recording relate actions to a database of sound events for the first time~\footnote{Annotations will be released after revision.}. The annotations were used to create semantic representations called Action Vectors (AVs). We evaluated SEC by comparing the AVs with two types of audio features -- log-mel spectrograms and state of the art audio embeddings. Because audio features and AVs capture different abstractions of the acoustic content, we combined them and achieved one of the highest reported accuracies (86.75%) in ESC-50, showing that Psychology-inspired approaches can improve SEC.
Learning Question-Guided Video Representation for Multi-Turn Video Question Answering
Jul 31, 2019
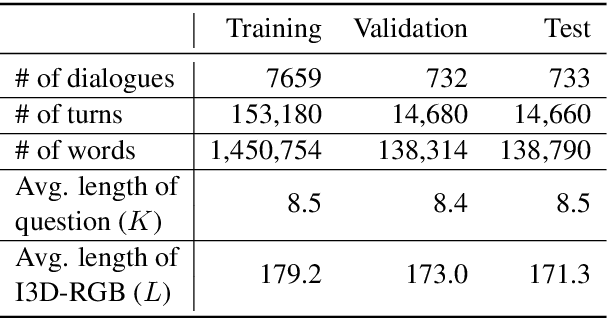
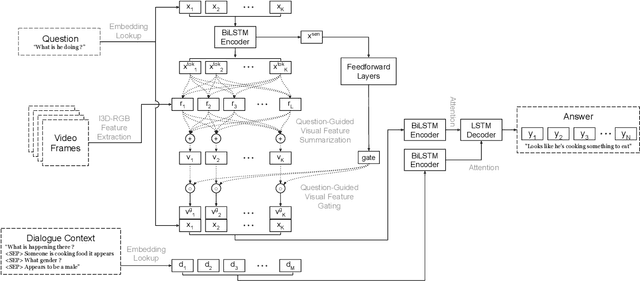
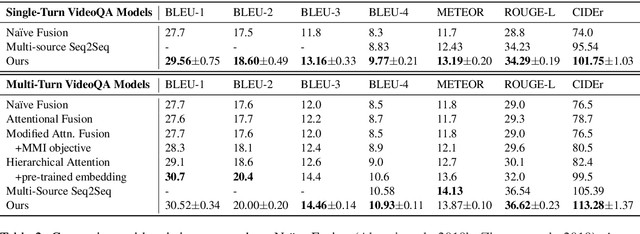
Understanding and conversing about dynamic scenes is one of the key capabilities of AI agents that navigate the environment and convey useful information to humans. Video question answering is a specific scenario of such AI-human interaction where an agent generates a natural language response to a question regarding the video of a dynamic scene. Incorporating features from multiple modalities, which often provide supplementary information, is one of the challenging aspects of video question answering. Furthermore, a question often concerns only a small segment of the video, hence encoding the entire video sequence using a recurrent neural network is not computationally efficient. Our proposed question-guided video representation module efficiently generates the token-level video summary guided by each word in the question. The learned representations are then fused with the question to generate the answer. Through empirical evaluation on the Audio Visual Scene-aware Dialog (AVSD) dataset, our proposed models in single-turn and multi-turn question answering achieve state-of-the-art performance on several automatic natural language generation evaluation metrics.
BERT-DST: Scalable End-to-End Dialogue State Tracking with Bidirectional Encoder Representations from Transformer
Jul 05, 2019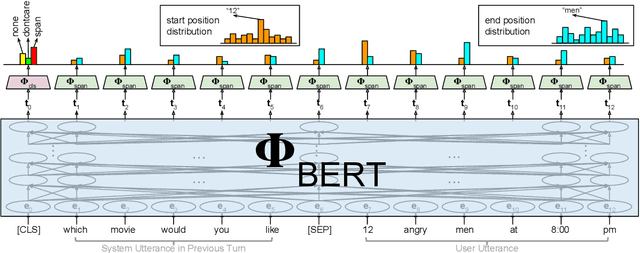

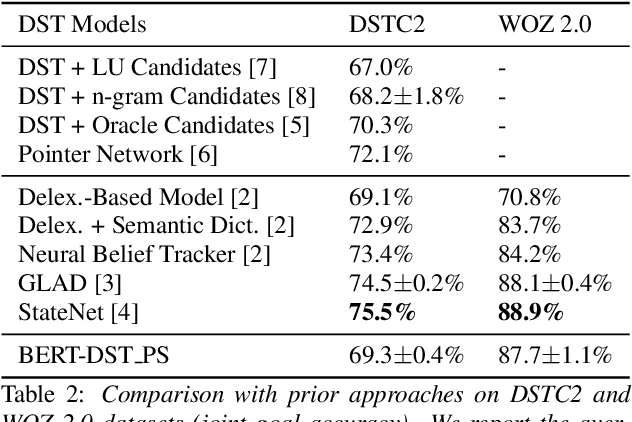
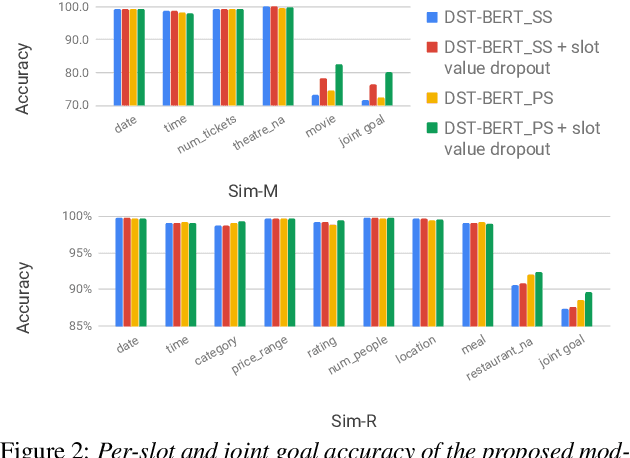
An important yet rarely tackled problem in dialogue state tracking (DST) is scalability for dynamic ontology (e.g., movie, restaurant) and unseen slot values. We focus on a specific condition, where the ontology is unknown to the state tracker, but the target slot value (except for none and dontcare), possibly unseen during training, can be found as word segment in the dialogue context. Prior approaches often rely on candidate generation from n-gram enumeration or slot tagger outputs, which can be inefficient or suffer from error propagation. We propose BERT-DST, an end-to-end dialogue state tracker which directly extracts slot values from the dialogue context. We use BERT as dialogue context encoder whose contextualized language representations are suitable for scalable DST to identify slot values from their semantic context. Furthermore, we employ encoder parameter sharing across all slots with two advantages: (1) Number of parameters does not grow linearly with the ontology. (2) Language representation knowledge can be transferred among slots. Empirical evaluation shows BERT-DST with cross-slot parameter sharing outperforms prior work on the benchmark scalable DST datasets Sim-M and Sim-R, and achieves competitive performance on the standard DSTC2 and WOZ 2.0 datasets.
Speaker-Targeted Audio-Visual Models for Speech Recognition in Cocktail-Party Environments
Jun 13, 2019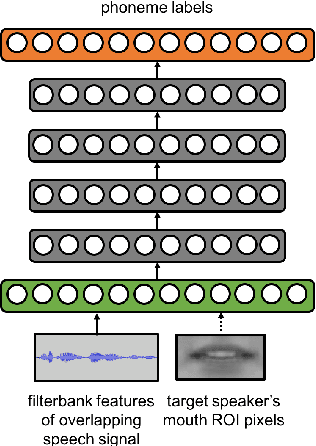
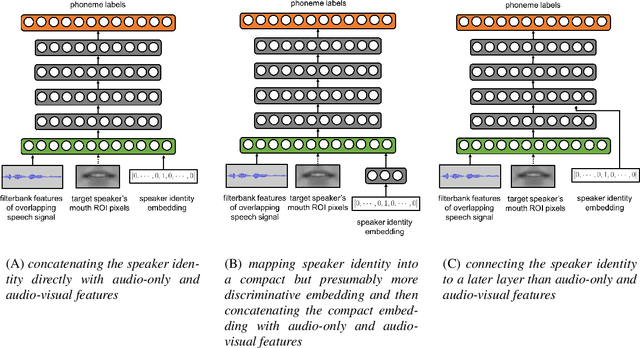
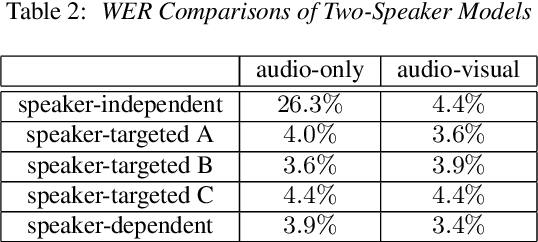
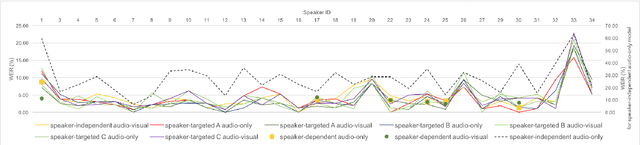
Speech recognition in cocktail-party environments remains a significant challenge for state-of-the-art speech recognition systems, as it is extremely difficult to extract an acoustic signal of an individual speaker from a background of overlapping speech with similar frequency and temporal characteristics. We propose the use of speaker-targeted acoustic and audio-visual models for this task. We complement the acoustic features in a hybrid DNN-HMM model with information of the target speaker's identity as well as visual features from the mouth region of the target speaker. Experimentation was performed using simulated cocktail-party data generated from the GRID audio-visual corpus by overlapping two speakers's speech on a single acoustic channel. Our audio-only baseline achieved a WER of 26.3%. The audio-visual model improved the WER to 4.4%. Introducing speaker identity information had an even more pronounced effect, improving the WER to 3.6%. Combining both approaches, however, did not significantly improve performance further. Our work demonstrates that speaker-targeted models can significantly improve the speech recognition in cocktail party environments.