 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProSLM : A Prolog Synergized Language Model for explainable Domain Specific Knowledge Based Question Answering
Sep 17, 2024Neurosymbolic approaches can add robustness to opaque neural systems by incorporating explainable symbolic representations. However, previous approaches have not used formal logic to contextualize queries to and validate outputs of large language models (LLMs). We propose \systemname{}, a novel neurosymbolic framework, to improve the robustness and reliability of LLMs in question-answering tasks. We provide \systemname{} with a domain-specific knowledge base, a logical reasoning system, and an integration to an existing LLM. This framework has two capabilities (1) context gathering: generating explainable and relevant context for a given query, and (2) validation: confirming and validating the factual accuracy of a statement in accordance with a knowledge base (KB). Our work opens a new area of neurosymbolic generative AI text validation and user personalization.
* Accepted at NeSy 2024
Autonomous Driving with Spiking Neural Networks
May 31, 2024



Autonomous driving demands an integrated approach that encompasses perception, prediction, and planning, all while operating under strict energy constraints to enhance scalability and environmental sustainability. We present Spiking Autonomous Driving (SAD), the first unified Spiking Neural Network (SNN) to address the energy challenges faced by autonomous driving systems through its event-driven and energy-efficient nature. SAD is trained end-to-end and consists of three main modules: perception, which processes inputs from multi-view cameras to construct a spatiotemporal bird's eye view; prediction, which utilizes a novel dual-pathway with spiking neurons to forecast future states; and planning, which generates safe trajectories considering predicted occupancy, traffic rules, and ride comfort. Evaluated on the nuScenes dataset, SAD achieves competitive performance in perception, prediction, and planning tasks, while drawing upon the energy efficiency of SNNs. This work highlights the potential of neuromorphic computing to be applied to energy-efficient autonomous driving, a critical step toward sustainable and safety-critical automotive technology. Our code is available at \url{https://github.com/ridgerchu/SAD}.
A novel post-hoc explanation comparison metric and applications
Nov 17, 2023



Explanatory systems make the behavior of machine learning models more transparent, but are often inconsistent. To quantify the differences between explanatory systems, this paper presents the Shreyan Distance, a novel metric based on the weighted difference between ranked feature importance lists produced by such systems. This paper uses the Shreyan Distance to compare two explanatory systems, SHAP and LIME, for both regression and classification learning tasks. Because we find that the average Shreyan Distance varies significantly between these two tasks, we conclude that consistency between explainers not only depends on inherent properties of the explainers themselves, but also the type of learning task. This paper further contributes the XAISuite library, which integrates the Shreyan distance algorithm into machine learning pipelines.
The XAISuite framework and the implications of explanatory system dissonance
Apr 15, 2023



Explanatory systems make machine learning models more transparent. However, they are often inconsistent. In order to quantify and isolate possible scenarios leading to this discrepancy, this paper compares two explanatory systems, SHAP and LIME, based on the correlation of their respective importance scores using 14 machine learning models (7 regression and 7 classification) and 4 tabular datasets (2 regression and 2 classification). We make two novel findings. Firstly, the magnitude of importance is not significant in explanation consistency. The correlations between SHAP and LIME importance scores for the most important features may or may not be more variable than the correlation between SHAP and LIME importance scores averaged across all features. Secondly, the similarity between SHAP and LIME importance scores cannot predict model accuracy. In the process of our research, we construct an open-source library, XAISuite, that unifies the process of training and explaining models. Finally, this paper contributes a generalized framework to better explain machine learning models and optimize their performance.
Establishing Meta-Decision-Making for AI: An Ontology of Relevance, Representation and Reasoning
Oct 02, 2022We propose an ontology of building decision-making systems, with the aim of establishing Meta-Decision-Making for Artificial Intelligence (AI), improving autonomy, and creating a framework to build metrics and benchmarks upon. To this end, we propose the three parts of Relevance, Representation, and Reasoning, and discuss their value in ensuring safety and mitigating risk in the context of third wave cognitive systems. Our nomenclature reflects the literature on decision-making, and our ontology allows researchers that adopt it to frame their work in relation to one or more of these parts.
A Knowledge Driven Approach to Adaptive Assistance Using Preference Reasoning and Explanation
Dec 05, 2020
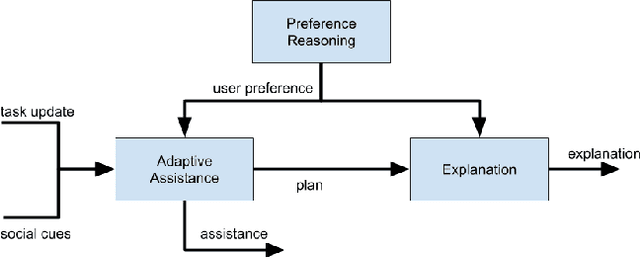
There is a need for socially assistive robots (SARs) to provide transparency in their behavior by explaining their reasoning. Additionally, the reasoning and explanation should represent the user's preferences and goals. To work towards satisfying this need for interpretable reasoning and representations, we propose the robot uses Analogical Theory of Mind to infer what the user is trying to do and uses the Hint Engine to find an appropriate assistance based on what the user is trying to do. If the user is unsure or confused, the robot provides the user with an explanation, generated by the Explanation Synthesizer. The explanation helps the user understand what the robot inferred about the user's preferences and why the robot decided to provide the assistance it gave. A knowledge-driven approach provides transparency to reasoning about preferences, assistance, and explanations, thereby facilitating the incorporation of user feedback and allowing the robot to learn and adapt to the user.