 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProSLM : A Prolog Synergized Language Model for explainable Domain Specific Knowledge Based Question Answering
Sep 17, 2024Neurosymbolic approaches can add robustness to opaque neural systems by incorporating explainable symbolic representations. However, previous approaches have not used formal logic to contextualize queries to and validate outputs of large language models (LLMs). We propose \systemname{}, a novel neurosymbolic framework, to improve the robustness and reliability of LLMs in question-answering tasks. We provide \systemname{} with a domain-specific knowledge base, a logical reasoning system, and an integration to an existing LLM. This framework has two capabilities (1) context gathering: generating explainable and relevant context for a given query, and (2) validation: confirming and validating the factual accuracy of a statement in accordance with a knowledge base (KB). Our work opens a new area of neurosymbolic generative AI text validation and user personalization.
* Accepted at NeSy 2024
Don't Believe Everything You Read: Enhancing Summarization Interpretability through Automatic Identification of Hallucinations in Large Language Models
Dec 22, 2023

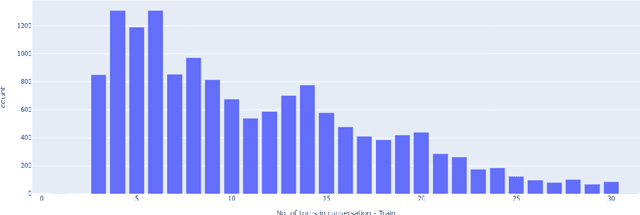

Large Language Models (LLMs) are adept at text manipulation -- tasks such as machine translation and text summarization. However, these models can also be prone to hallucination, which can be detrimental to the faithfulness of any answers that the model provides. Recent works in combating hallucinations in LLMs deal with identifying hallucinated sentences and categorizing the different ways in which models hallucinate. This paper takes a deep dive into LLM behavior with respect to hallucinations, defines a token-level approach to identifying different kinds of hallucinations, and further utilizes this token-level tagging to improve the interpretability and faithfulness of LLMs in dialogue summarization tasks. Through this, the paper presents a new, enhanced dataset and a new training paradigm.