 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeProphecy: A Large-Scale Benchmark for Autoregressive Neural Population Forecasting
May 13, 2026Neural population models, which predict the joint firing of many simultaneously recorded neurons forward in time, are typically evaluated by a single aggregate Pearson correlation $r$ between predicted and actual spike counts, a number that masks critical structure. We argue that how we evaluate spike forecasting matters as much as what we build, and introduce SpikeProphecy, the first large-scale benchmark for causal, autoregressive spike-count forecasting on real electrophysiology recordings. Our core contribution is a population metric decomposition that separates aggregate performance into temporal fidelity, spatial pattern accuracy, and magnitude-invariant alignment. The decomposition surfaces aspects of the underlying data that an aggregate scalar collapses together. We apply the protocol to 105 Neuropixels sessions (Steinmetz 2019 + IBL Repeated Site; ~89,800 neurons) with seven architecture baselines spanning four structural families: four SSMs (three diagonal and one non-diagonal), a Transformer, an LSTM, and a spiking network. The decomposition surfaces a brain-region predictability ranking that reproduces across all seven baselines and survives ANCOVA correction for firing-statistics constraints (region $ΔR^2 = 0.018$ above the firing-statistics covariates). It also exposes a sub-Poisson evaluation floor where rigorous metrics combine with genuine biophysical constraints on regular spike trains, and yields a negative result on KL-on-output-rates distillation for ANN-to-SNN transfer in this Poisson count domain.
NeuroMorse: A Temporally Structured Dataset For Neuromorphic Computing
Feb 28, 2025Neuromorphic engineering aims to advance computing by mimicking the brain's efficient processing, where data is encoded as asynchronous temporal events. This eliminates the need for a synchronisation clock and minimises power consumption when no data is present. However, many benchmarks for neuromorphic algorithms primarily focus on spatial features, neglecting the temporal dynamics that are inherent to most sequence-based tasks. This gap may lead to evaluations that fail to fully capture the unique strengths and characteristics of neuromorphic systems. In this paper, we present NeuroMorse, a temporally structured dataset designed for benchmarking neuromorphic learning systems. NeuroMorse converts the top 50 words in the English language into temporal Morse code spike sequences. Despite using only two input spike channels for Morse dots and dashes, complex information is encoded through temporal patterns in the data. The proposed benchmark contains feature hierarchy at multiple temporal scales that test the capacity of neuromorphic algorithms to decompose input patterns into spatial and temporal hierarchies. We demonstrate that our training set is challenging to categorise using a linear classifier and that identifying keywords in the test set is difficult using conventional methods. The NeuroMorse dataset is available at Zenodo, with our accompanying code on GitHub at https://github.com/Ben-E-Walters/NeuroMorse.
Reducing Data Bottlenecks in Distributed, Heterogeneous Neural Networks
Oct 12, 2024
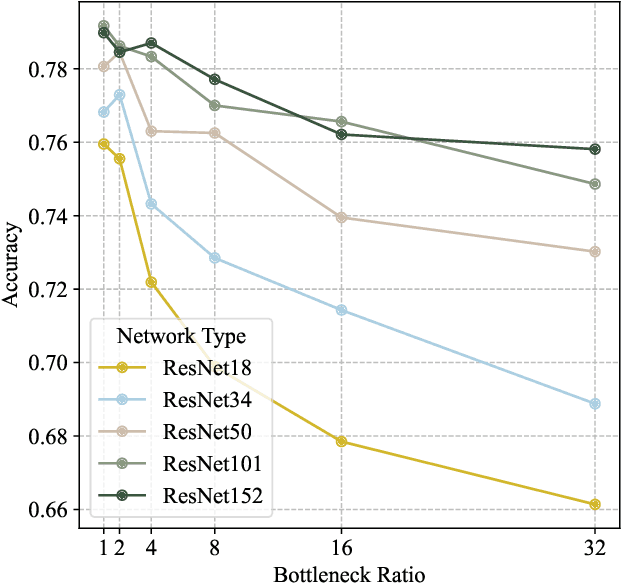
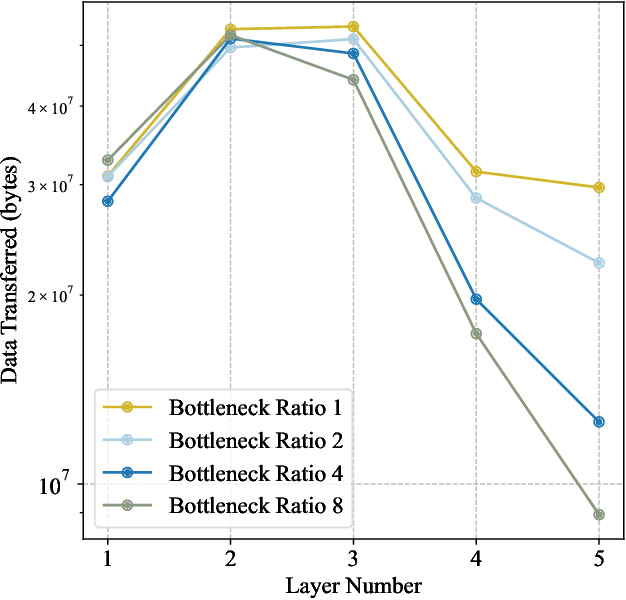
The rapid advancement of embedded multicore and many-core systems has revolutionized computing, enabling the development of high-performance, energy-efficient solutions for a wide range of applications. As models scale up in size, data movement is increasingly the bottleneck to performance. This movement of data can exist between processor and memory, or between cores and chips. This paper investigates the impact of bottleneck size, in terms of inter-chip data traffic, on the performance of deep learning models in embedded multicore and many-core systems. We conduct a systematic analysis of the relationship between bottleneck size, computational resource utilization, and model accuracy. We apply a hardware-software co-design methodology where data bottlenecks are replaced with extremely narrow layers to reduce the amount of data traffic. In effect, time-multiplexing of signals is replaced by learnable embeddings that reduce the demands on chip IOs. Our experiments on the CIFAR100 dataset demonstrate that the classification accuracy generally decreases as the bottleneck ratio increases, with shallower models experiencing a more significant drop compared to deeper models. Hardware-side evaluation reveals that higher bottleneck ratios lead to substantial reductions in data transfer volume across the layers of the neural network. Through this research, we can determine the trade-off between data transfer volume and model performance, enabling the identification of a balanced point that achieves good performance while minimizing data transfer volume. This characteristic allows for the development of efficient models that are well-suited for resource-constrained environments.
Scalable MatMul-free Language Modeling
Jun 04, 2024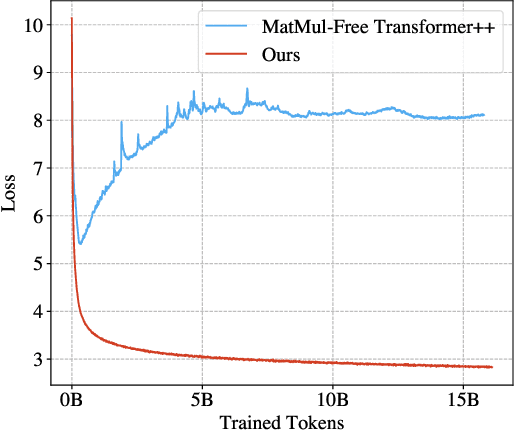
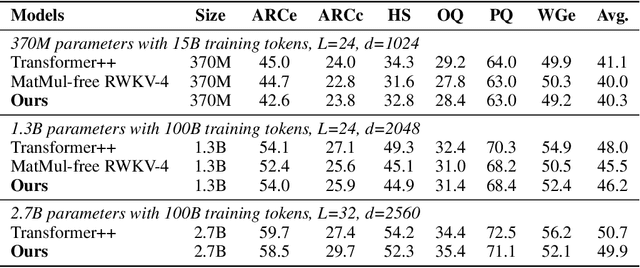
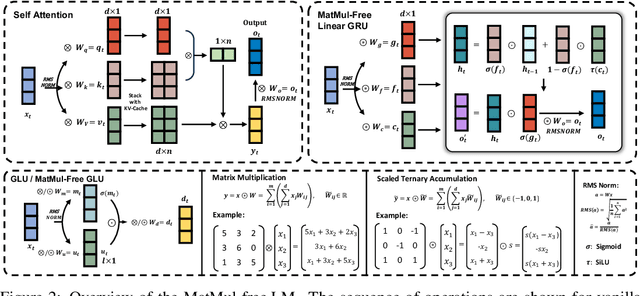
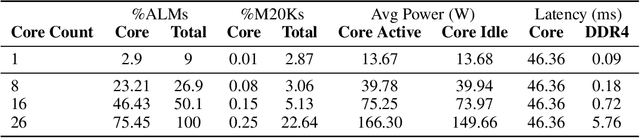
Matrix multiplication (MatMul) typically dominates the overall computational cost of large language models (LLMs). This cost only grows as LLMs scale to larger embedding dimensions and context lengths. In this work, we show that MatMul operations can be completely eliminated from LLMs while maintaining strong performance at billion-parameter scales. Our experiments show that our proposed MatMul-free models achieve performance on-par with state-of-the-art Transformers that require far more memory during inference at a scale up to at least 2.7B parameters. We investigate the scaling laws and find that the performance gap between our MatMul-free models and full precision Transformers narrows as the model size increases. We also provide a GPU-efficient implementation of this model which reduces memory usage by up to 61% over an unoptimized baseline during training. By utilizing an optimized kernel during inference, our model's memory consumption can be reduced by more than 10x compared to unoptimized models. To properly quantify the efficiency of our architecture, we build a custom hardware solution on an FPGA which exploits lightweight operations beyond what GPUs are capable of. We processed billion-parameter scale models at 13W beyond human readable throughput, moving LLMs closer to brain-like efficiency. This work not only shows how far LLMs can be stripped back while still performing effectively, but also points at the types of operations future accelerators should be optimized for in processing the next generation of lightweight LLMs. Our code implementation is available at \url{https://github.com/ridgerchu/matmulfreellm}.
Autonomous Driving with Spiking Neural Networks
May 31, 2024



Autonomous driving demands an integrated approach that encompasses perception, prediction, and planning, all while operating under strict energy constraints to enhance scalability and environmental sustainability. We present Spiking Autonomous Driving (SAD), the first unified Spiking Neural Network (SNN) to address the energy challenges faced by autonomous driving systems through its event-driven and energy-efficient nature. SAD is trained end-to-end and consists of three main modules: perception, which processes inputs from multi-view cameras to construct a spatiotemporal bird's eye view; prediction, which utilizes a novel dual-pathway with spiking neurons to forecast future states; and planning, which generates safe trajectories considering predicted occupancy, traffic rules, and ride comfort. Evaluated on the nuScenes dataset, SAD achieves competitive performance in perception, prediction, and planning tasks, while drawing upon the energy efficiency of SNNs. This work highlights the potential of neuromorphic computing to be applied to energy-efficient autonomous driving, a critical step toward sustainable and safety-critical automotive technology. Our code is available at \url{https://github.com/ridgerchu/SAD}.
Advancing Spiking Neural Networks towards Multiscale Spatiotemporal Interaction Learning
May 22, 2024



Recent advancements in neuroscience research have propelled the development of Spiking Neural Networks (SNNs), which not only have the potential to further advance neuroscience research but also serve as an energy-efficient alternative to Artificial Neural Networks (ANNs) due to their spike-driven characteristics. However, previous studies often neglected the multiscale information and its spatiotemporal correlation between event data, leading SNN models to approximate each frame of input events as static images. We hypothesize that this oversimplification significantly contributes to the performance gap between SNNs and traditional ANNs. To address this issue, we have designed a Spiking Multiscale Attention (SMA) module that captures multiscale spatiotemporal interaction information. Furthermore, we developed a regularization method named Attention ZoneOut (AZO), which utilizes spatiotemporal attention weights to reduce the model's generalization error through pseudo-ensemble training. Our approach has achieved state-of-the-art results on mainstream neural morphology datasets. Additionally, we have reached a performance of 77.1% on the Imagenet-1K dataset using a 104-layer ResNet architecture enhanced with SMA and AZO. This achievement confirms the state-of-the-art performance of SNNs with non-transformer architectures and underscores the effectiveness of our method in bridging the performance gap between SNN models and traditional ANN models.
SQUAT: Stateful Quantization-Aware Training in Recurrent Spiking Neural Networks
Apr 15, 2024



Weight quantization is used to deploy high-performance deep learning models on resource-limited hardware, enabling the use of low-precision integers for storage and computation. Spiking neural networks (SNNs) share the goal of enhancing efficiency, but adopt an 'event-driven' approach to reduce the power consumption of neural network inference. While extensive research has focused on weight quantization, quantization-aware training (QAT), and their application to SNNs, the precision reduction of state variables during training has been largely overlooked, potentially diminishing inference performance. This paper introduces two QAT schemes for stateful neurons: (i) a uniform quantization strategy, an established method for weight quantization, and (ii) threshold-centered quantization, which allocates exponentially more quantization levels near the firing threshold. Our results show that increasing the density of quantization levels around the firing threshold improves accuracy across several benchmark datasets. We provide an ablation analysis of the effects of weight and state quantization, both individually and combined, and how they impact models. Our comprehensive empirical evaluation includes full precision, 8-bit, 4-bit, and 2-bit quantized SNNs, using QAT, stateful QAT (SQUAT), and post-training quantization methods. The findings indicate that the combination of QAT and SQUAT enhance performance the most, but given the choice of one or the other, QAT improves performance by the larger degree. These trends are consistent all datasets. Our methods have been made available in our Python library snnTorch: https://github.com/jeshraghian/snntorch.
Neuromorphic Intermediate Representation: A Unified Instruction Set for Interoperable Brain-Inspired Computing
Nov 24, 2023Spiking neural networks and neuromorphic hardware platforms that emulate neural dynamics are slowly gaining momentum and entering main-stream usage. Despite a well-established mathematical foundation for neural dynamics, the implementation details vary greatly across different platforms. Correspondingly, there are a plethora of software and hardware implementations with their own unique technology stacks. Consequently, neuromorphic systems typically diverge from the expected computational model, which challenges the reproducibility and reliability across platforms. Additionally, most neuromorphic hardware is limited by its access via a single software frameworks with a limited set of training procedures. Here, we establish a common reference-frame for computations in neuromorphic systems, dubbed the Neuromorphic Intermediate Representation (NIR). NIR defines a set of computational primitives as idealized continuous-time hybrid systems that can be composed into graphs and mapped to and from various neuromorphic technology stacks. By abstracting away assumptions around discretization and hardware constraints, NIR faithfully captures the fundamental computation, while simultaneously exposing the exact differences between the evaluated implementation and the idealized mathematical formalism. We reproduce three NIR graphs across 7 neuromorphic simulators and 4 hardware platforms, demonstrating support for an unprecedented number of neuromorphic systems. With NIR, we decouple the evolution of neuromorphic hardware and software, ultimately increasing the interoperability between platforms and improving accessibility to neuromorphic technologies. We believe that NIR is an important step towards the continued study of brain-inspired hardware and bottom-up approaches aimed at an improved understanding of the computational underpinnings of nervous systems.
To Spike or Not To Spike: A Digital Hardware Perspective on Deep Learning Acceleration
Jun 27, 2023



As deep learning models scale, they become increasingly competitive from domains spanning computer vision to natural language processing; however, this happens at the expense of efficiency since they require increasingly more memory and computing power. The power efficiency of the biological brain outperforms the one of any large-scale deep learning (DL) model; thus, neuromorphic computing tries to mimic the brain operations, such as spike-based information processing, to improve the efficiency of DL models. Despite the benefits of the brain, such as efficient information transmission, dense neuronal interconnects, and the co-location of computation and memory, the available biological substrate has severely constrained the evolution of biological brains. Electronic hardware does not have the same constraints; therefore, while modeling spiking neural networks (SNNs) might uncover one piece of the puzzle, the design of efficient hardware backends for SNNs needs further investigation, potentially taking inspiration from the available work done on the artificial neural networks (ANN s) side. As such, when is it wise to look at the brain while designing new hardware, and when should it be ignored? To answer this question, we quantitatively compare the digital hardware acceleration techniques and platforms of ANN s and SNNs.
Memristive Reservoirs Learn to Learn
Jun 22, 2023Memristive reservoirs draw inspiration from a novel class of neuromorphic hardware known as nanowire networks. These systems display emergent brain-like dynamics, with optimal performance demonstrated at dynamical phase transitions. In these networks, a limited number of electrodes are available to modulate system dynamics, in contrast to the global controllability offered by neuromorphic hardware through random access memories. We demonstrate that the learn-to-learn framework can effectively address this challenge in the context of optimization. Using the framework, we successfully identify the optimal hyperparameters for the reservoir. This finding aligns with previous research, which suggests that the optimal performance of a memristive reservoir occurs at the `edge of formation' of a conductive pathway. Furthermore, our results show that these systems can mimic membrane potential behavior observed in spiking neurons, and may serve as an interface between spike-based and continuous processes.