 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeployment Pipeline from Rockpool to Xylo for Edge Computing
Dec 15, 2024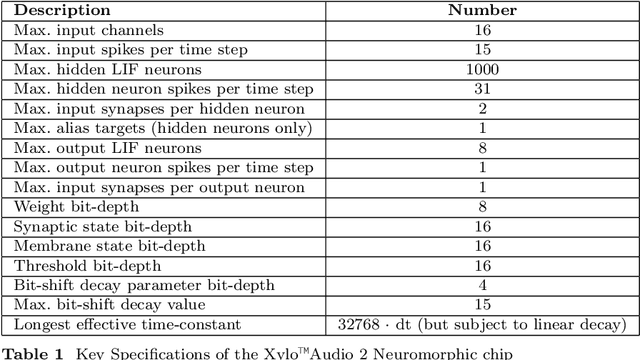
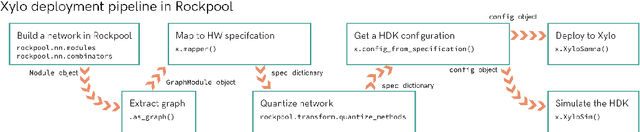
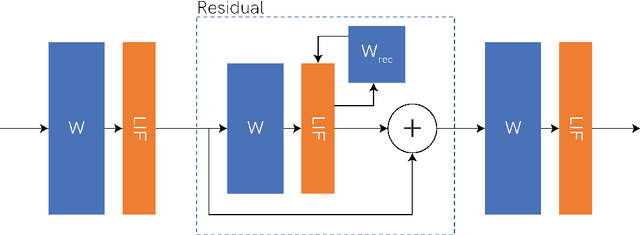
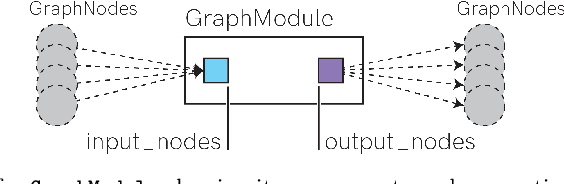
Deploying Spiking Neural Networks (SNNs) on the Xylo neuromorphic chip via the Rockpool framework represents a significant advancement in achieving ultra-low-power consumption and high computational efficiency for edge applications. This paper details a novel deployment pipeline, emphasizing the integration of Rockpool's capabilities with Xylo's architecture, and evaluates the system's performance in terms of energy efficiency and accuracy. The unique advantages of the Xylo chip, including its digital spiking architecture and event-driven processing model, are highlighted to demonstrate its suitability for real-time, power-sensitive applications.
Micro-power spoken keyword spotting on Xylo Audio 2
Jun 21, 2024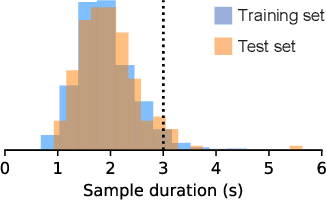
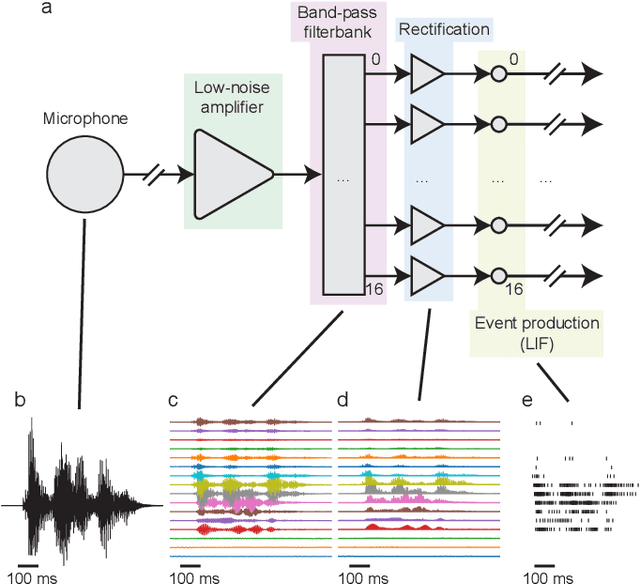
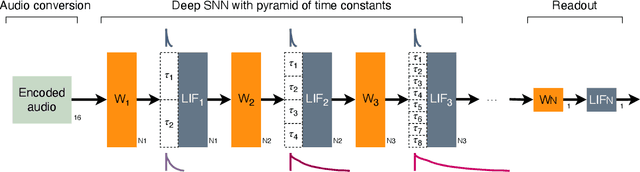
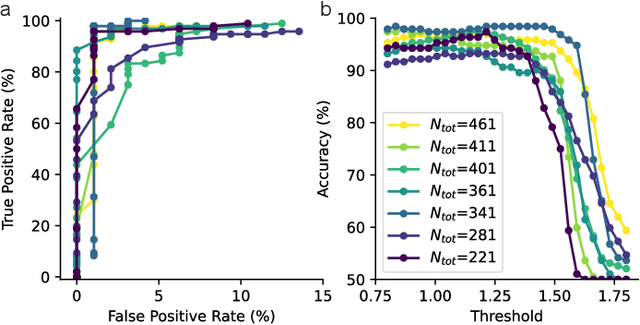
For many years, designs for "Neuromorphic" or brain-like processors have been motivated by achieving extreme energy efficiency, compared with von-Neumann and tensor processor devices. As part of their design language, Neuromorphic processors take advantage of weight, parameter, state and activity sparsity. In the extreme case, neural networks based on these principles mimic the sparse activity oof biological nervous systems, in ``Spiking Neural Networks'' (SNNs). Few benchmarks are available for Neuromorphic processors, that have been implemented for a range of Neuromorphic and non-Neuromorphic platforms, which can therefore demonstrate the energy benefits of Neuromorphic processor designs. Here we describes the implementation of a spoken audio keyword-spotting (KWS) benchmark "Aloha" on the Xylo Audio 2 (SYNS61210) Neuromorphic processor device. We obtained high deployed quantized task accuracy, (95%), exceeding the benchmark task accuracy. We measured real continuous power of the deployed application on Xylo. We obtained best-in-class dynamic inference power ($291\mu$W) and best-in-class inference efficiency ($6.6\mu$J / Inf). Xylo sets a new minimum power for the Aloha KWS benchmark, and highlights the extreme energy efficiency achievable with Neuromorphic processor designs. Our results show that Neuromorphic designs are well-suited for real-time near- and in-sensor processing on edge devices.
Neuromorphic Intermediate Representation: A Unified Instruction Set for Interoperable Brain-Inspired Computing
Nov 24, 2023Spiking neural networks and neuromorphic hardware platforms that emulate neural dynamics are slowly gaining momentum and entering main-stream usage. Despite a well-established mathematical foundation for neural dynamics, the implementation details vary greatly across different platforms. Correspondingly, there are a plethora of software and hardware implementations with their own unique technology stacks. Consequently, neuromorphic systems typically diverge from the expected computational model, which challenges the reproducibility and reliability across platforms. Additionally, most neuromorphic hardware is limited by its access via a single software frameworks with a limited set of training procedures. Here, we establish a common reference-frame for computations in neuromorphic systems, dubbed the Neuromorphic Intermediate Representation (NIR). NIR defines a set of computational primitives as idealized continuous-time hybrid systems that can be composed into graphs and mapped to and from various neuromorphic technology stacks. By abstracting away assumptions around discretization and hardware constraints, NIR faithfully captures the fundamental computation, while simultaneously exposing the exact differences between the evaluated implementation and the idealized mathematical formalism. We reproduce three NIR graphs across 7 neuromorphic simulators and 4 hardware platforms, demonstrating support for an unprecedented number of neuromorphic systems. With NIR, we decouple the evolution of neuromorphic hardware and software, ultimately increasing the interoperability between platforms and improving accessibility to neuromorphic technologies. We believe that NIR is an important step towards the continued study of brain-inspired hardware and bottom-up approaches aimed at an improved understanding of the computational underpinnings of nervous systems.
Training and Deploying Spiking NN Applications to the Mixed-Signal Neuromorphic Chip Dynap-SE2 with Rockpool
Mar 14, 2023Mixed-signal neuromorphic processors provide extremely low-power operation for edge inference workloads, taking advantage of sparse asynchronous computation within Spiking Neural Networks (SNNs). However, deploying robust applications to these devices is complicated by limited controllability over analog hardware parameters, unintended parameter and dynamics variations of analog circuits due to fabrication non-idealities. Here we demonstrate a novel methodology for offline training and deployment of spiking neural networks (SNNs) to the mixed-signal neuromorphic processor Dynap-SE2. The methodology utilizes an unsupervised weight quantization method to optimize the network's parameters, coupled with adversarial parameter noise injection during training. The optimized network is shown to be robust to the effects of quantization and device mismatch, making the method a promising candidate for real-world applications with hardware constraints. This work extends Rockpool, an open-source deep-learning library for SNNs, with support accurate simulation of mixed-signal SNN dynamics. Our approach simplifies the development and deployment process for the neuromorphic community, making mixed-signal neuromorphic processors more accessible to researchers and developers.
Network insensitivity to parameter noise via adversarial regularization
Jun 22, 2021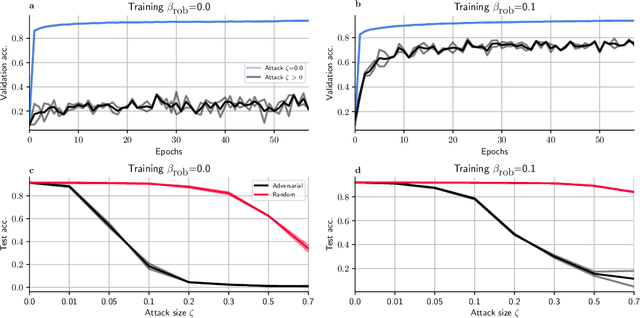
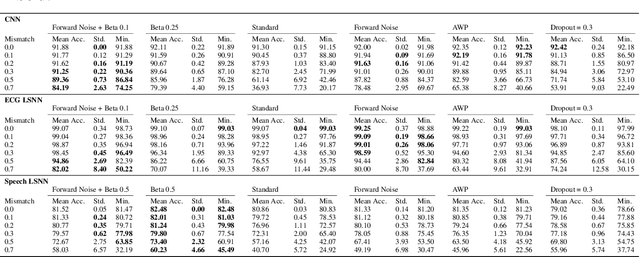

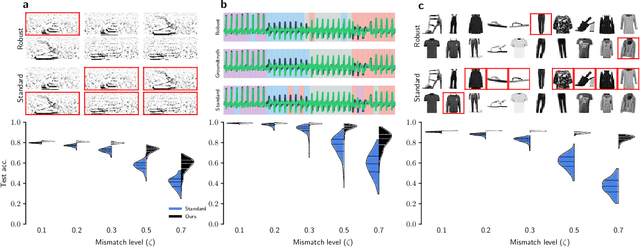
Neuromorphic neural network processors, in the form of compute-in-memory crossbar arrays of memristors, or in the form of subthreshold analog and mixed-signal ASICs, promise enormous advantages in compute density and energy efficiency for NN-based ML tasks. However, these technologies are prone to computational non-idealities, due to process variation and intrinsic device physics. This degrades the task performance of networks deployed to the processor, by introducing parameter noise into the deployed model. While it is possible to calibrate each device, or train networks individually for each processor, these approaches are expensive and impractical for commercial deployment. Alternative methods are therefore needed to train networks that are inherently robust against parameter variation, as a consequence of network architecture and parameters. We present a new adversarial network optimisation algorithm that attacks network parameters during training, and promotes robust performance during inference in the face of parameter variation. Our approach introduces a regularization term penalising the susceptibility of a network to weight perturbation. We compare against previous approaches for producing parameter insensitivity such as dropout, weight smoothing and introducing parameter noise during training. We show that our approach produces models that are more robust to targeted parameter variation, and equally robust to random parameter variation. Our approach finds minima in flatter locations in the weight-loss landscape compared with other approaches, highlighting that the networks found by our technique are less sensitive to parameter perturbation. Our work provides an approach to deploy neural network architectures to inference devices that suffer from computational non-idealities, with minimal loss of performance. ...
Supervised training of spiking neural networks for robust deployment on mixed-signal neuromorphic processors
Feb 17, 2021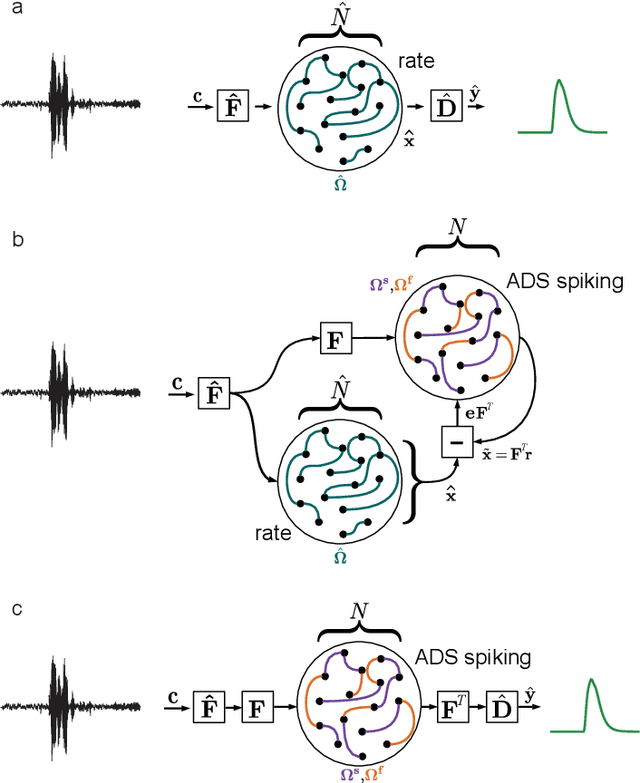
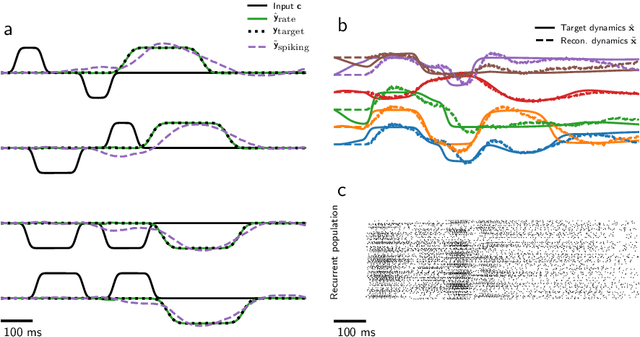
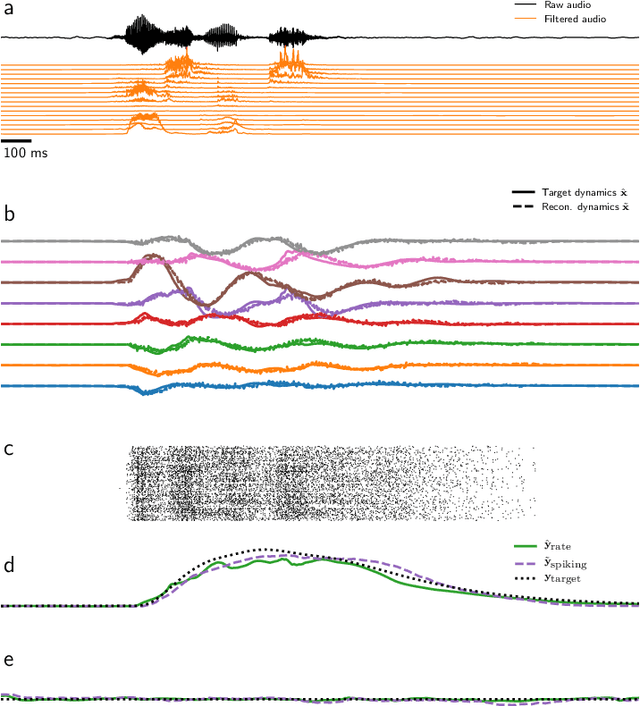
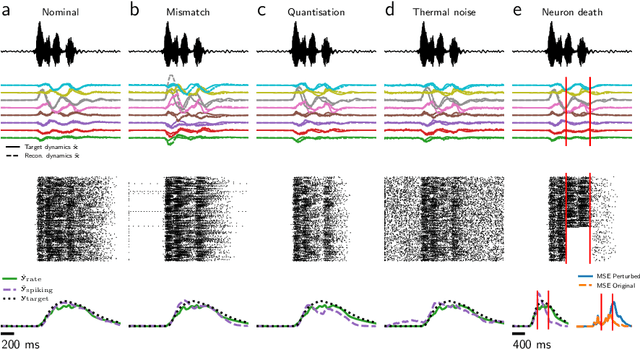
Mixed-signal analog/digital circuits can emulate spiking neurons and synapses with extremely high energy efficiency, an approach known as "neuromorphic engineering". However, analog circuits are sensitive to process-induced variation among transistors in a chip ("device mismatch"). For neuromorphic implementation of Spiking Neural Networks (SNNs), mismatch causes parameter variation between identically-configured neurons and synapses. Each chip therefore exhibits a different distribution of neural parameters, causing deployed networks to respond differently between chips. Current solutions to mitigate mismatch based on per-chip calibration or on-chip learning entail increased design complexity, area and cost, making deployment of neuromorphic devices expensive and difficult. Here we present a supervised learning approach that addresses this challenge by maximizing robustness to mismatch and other common sources of noise. Our method trains SNNs to perform temporal classification tasks by mimicking a pre-trained dynamical system, using a local learning rule adapted from non-linear control theory. We demonstrate our method on two tasks requiring memory, and measure the robustness of our approach to several forms of noise and mismatch. We show that our approach is more robust than several common alternatives for training SNNs. Our method provides a viable way to robustly deploy pre-trained networks on mixed-signal neuromorphic hardware, without requiring per-device training or calibration.