 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Data Bottlenecks in Distributed, Heterogeneous Neural Networks
Oct 12, 2024
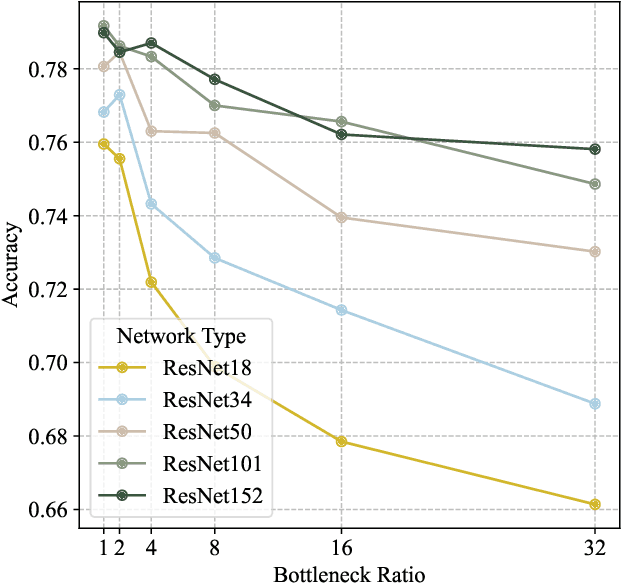
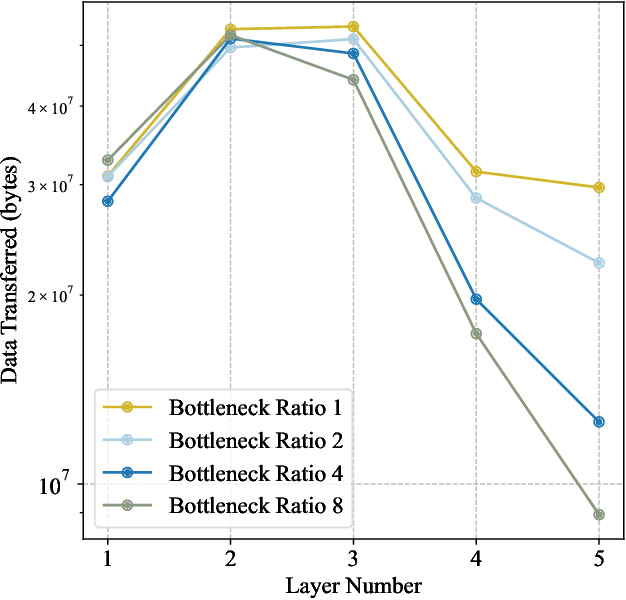
The rapid advancement of embedded multicore and many-core systems has revolutionized computing, enabling the development of high-performance, energy-efficient solutions for a wide range of applications. As models scale up in size, data movement is increasingly the bottleneck to performance. This movement of data can exist between processor and memory, or between cores and chips. This paper investigates the impact of bottleneck size, in terms of inter-chip data traffic, on the performance of deep learning models in embedded multicore and many-core systems. We conduct a systematic analysis of the relationship between bottleneck size, computational resource utilization, and model accuracy. We apply a hardware-software co-design methodology where data bottlenecks are replaced with extremely narrow layers to reduce the amount of data traffic. In effect, time-multiplexing of signals is replaced by learnable embeddings that reduce the demands on chip IOs. Our experiments on the CIFAR100 dataset demonstrate that the classification accuracy generally decreases as the bottleneck ratio increases, with shallower models experiencing a more significant drop compared to deeper models. Hardware-side evaluation reveals that higher bottleneck ratios lead to substantial reductions in data transfer volume across the layers of the neural network. Through this research, we can determine the trade-off between data transfer volume and model performance, enabling the identification of a balanced point that achieves good performance while minimizing data transfer volume. This characteristic allows for the development of efficient models that are well-suited for resource-constrained environments.