 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopViT: Scaling Visual ARC with Looped Transformers
Feb 02, 2026Recent advances in visual reasoning have leveraged vision transformers to tackle the ARC-AGI benchmark. However, we argue that the feed-forward architecture, where computational depth is strictly bound to parameter size, falls short of capturing the iterative, algorithmic nature of human induction. In this work, we propose a recursive architecture called Loop-ViT, which decouples reasoning depth from model capacity through weight-tied recurrence. Loop-ViT iterates a weight-tied Hybrid Block, combining local convolutions and global attention, to form a latent chain of thought. Crucially, we introduce a parameter-free Dynamic Exit mechanism based on predictive entropy: the model halts inference when its internal state ``crystallizes" into a low-uncertainty attractor. Empirical results on the ARC-AGI-1 benchmark validate this perspective: our 18M model achieves 65.8% accuracy, outperforming massive 73M-parameter ensembles. These findings demonstrate that adaptive iterative computation offers a far more efficient scaling axis for visual reasoning than simply increasing network width. The code is available at https://github.com/WenjieShu/LoopViT.
Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space
Dec 31, 2025Large Language Models (LLMs) apply uniform computation to all tokens, despite language exhibiting highly non-uniform information density. This token-uniform regime wastes capacity on locally predictable spans while under-allocating computation to semantically critical transitions. We propose $\textbf{Dynamic Large Concept Models (DLCM)}$, a hierarchical language modeling framework that learns semantic boundaries from latent representations and shifts computation from tokens to a compressed concept space where reasoning is more efficient. DLCM discovers variable-length concepts end-to-end without relying on predefined linguistic units. Hierarchical compression fundamentally changes scaling behavior. We introduce the first $\textbf{compression-aware scaling law}$, which disentangles token-level capacity, concept-level reasoning capacity, and compression ratio, enabling principled compute allocation under fixed FLOPs. To stably train this heterogeneous architecture, we further develop a $\textbf{decoupled $μ$P parametrization}$ that supports zero-shot hyperparameter transfer across widths and compression regimes. At a practical setting ($R=4$, corresponding to an average of four tokens per concept), DLCM reallocates roughly one-third of inference compute into a higher-capacity reasoning backbone, achieving a $\textbf{+2.69$\%$ average improvement}$ across 12 zero-shot benchmarks under matched inference FLOPs.
Scaling Latent Reasoning via Looped Language Models
Oct 29, 2025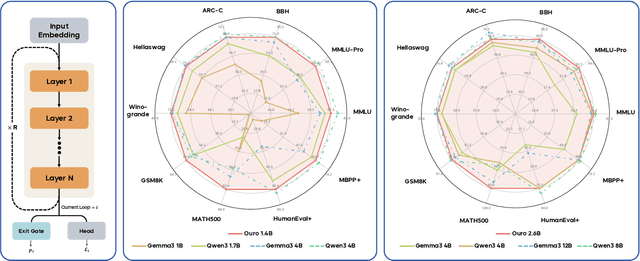
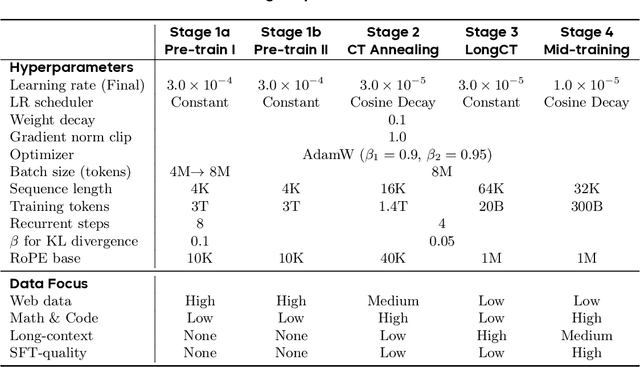
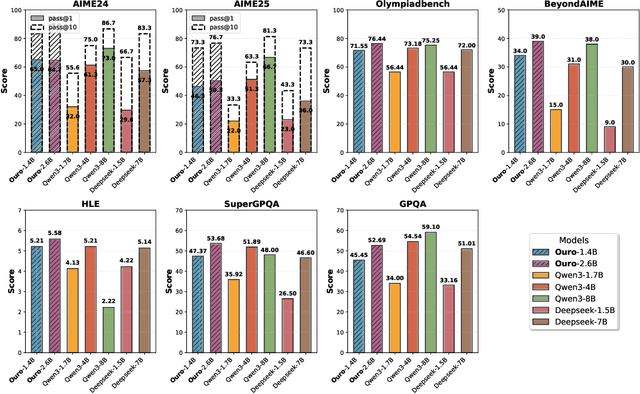

Modern LLMs are trained to "think" primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era. Our model could be found in: http://ouro-llm.github.io.
A Systematic Analysis of Hybrid Linear Attention
Jul 08, 2025Transformers face quadratic complexity and memory issues with long sequences, prompting the adoption of linear attention mechanisms using fixed-size hidden states. However, linear models often suffer from limited recall performance, leading to hybrid architectures that combine linear and full attention layers. Despite extensive hybrid architecture research, the choice of linear attention component has not been deeply explored. We systematically evaluate various linear attention models across generations - vector recurrences to advanced gating mechanisms - both standalone and hybridized. To enable this comprehensive analysis, we trained and open-sourced 72 models: 36 at 340M parameters (20B tokens) and 36 at 1.3B parameters (100B tokens), covering six linear attention variants across five hybridization ratios. Benchmarking on standard language modeling and recall tasks reveals that superior standalone linear models do not necessarily excel in hybrids. While language modeling remains stable across linear-to-full attention ratios, recall significantly improves with increased full attention layers, particularly below a 3:1 ratio. Our study highlights selective gating, hierarchical recurrence, and controlled forgetting as critical for effective hybrid models. We recommend architectures such as HGRN-2 or GatedDeltaNet with a linear-to-full ratio between 3:1 and 6:1 to achieve Transformer-level recall efficiently. Our models are open-sourced at https://huggingface.co/collections/m-a-p/hybrid-linear-attention-research-686c488a63d609d2f20e2b1e.
A Survey on Latent Reasoning
Jul 08, 2025



Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, especially when guided by explicit chain-of-thought (CoT) reasoning that verbalizes intermediate steps. While CoT improves both interpretability and accuracy, its dependence on natural language reasoning limits the model's expressive bandwidth. Latent reasoning tackles this bottleneck by performing multi-step inference entirely in the model's continuous hidden state, eliminating token-level supervision. To advance latent reasoning research, this survey provides a comprehensive overview of the emerging field of latent reasoning. We begin by examining the foundational role of neural network layers as the computational substrate for reasoning, highlighting how hierarchical representations support complex transformations. Next, we explore diverse latent reasoning methodologies, including activation-based recurrence, hidden state propagation, and fine-tuning strategies that compress or internalize explicit reasoning traces. Finally, we discuss advanced paradigms such as infinite-depth latent reasoning via masked diffusion models, which enable globally consistent and reversible reasoning processes. By unifying these perspectives, we aim to clarify the conceptual landscape of latent reasoning and chart future directions for research at the frontier of LLM cognition. An associated GitHub repository collecting the latest papers and repos is available at: https://github.com/multimodal-art-projection/LatentCoT-Horizon/.
ARFlow: Autogressive Flow with Hybrid Linear Attention
Jan 27, 2025



Flow models are effective at progressively generating realistic images, but they generally struggle to capture long-range dependencies during the generation process as they compress all the information from previous time steps into a single corrupted image. To address this limitation, we propose integrating autoregressive modeling -- known for its excellence in modeling complex, high-dimensional joint probability distributions -- into flow models. During training, at each step, we construct causally-ordered sequences by sampling multiple images from the same semantic category and applying different levels of noise, where images with higher noise levels serve as causal predecessors to those with lower noise levels. This design enables the model to learn broader category-level variations while maintaining proper causal relationships in the flow process. During generation, the model autoregressively conditions the previously generated images from earlier denoising steps, forming a contextual and coherent generation trajectory. Additionally, we design a customized hybrid linear attention mechanism tailored to our modeling approach to enhance computational efficiency. Our approach, termed ARFlow, under 400k training steps, achieves 14.08 FID scores on ImageNet at 128 * 128 without classifier-free guidance, reaching 4.34 FID with classifier-free guidance 1.5, significantly outperforming the previous flow-based model SiT's 9.17 FID. Extensive ablation studies demonstrate the effectiveness of our modeling strategy and chunk-wise attention design.
Future-Guided Learning: A Predictive Approach To Enhance Time-Series Forecasting
Oct 19, 2024



Accurate time-series forecasting is essential across a multitude of scientific and industrial domains, yet deep learning models often struggle with challenges such as capturing long-term dependencies and adapting to drift in data distributions over time. We introduce Future-Guided Learning, an approach that enhances time-series event forecasting through a dynamic feedback mechanism inspired by predictive coding. Our approach involves two models: a detection model that analyzes future data to identify critical events and a forecasting model that predicts these events based on present data. When discrepancies arise between the forecasting and detection models, the forecasting model undergoes more substantial updates, effectively minimizing surprise and adapting to shifts in the data distribution by aligning its predictions with actual future outcomes. This feedback loop, drawing upon principles of predictive coding, enables the forecasting model to dynamically adjust its parameters, improving accuracy by focusing on features that remain relevant despite changes in the underlying data. We validate our method on a variety of tasks such as seizure prediction in biomedical signal analysis and forecasting in dynamical systems, achieving a 40\% increase in the area under the receiver operating characteristic curve (AUC-ROC) and a 10\% reduction in mean absolute error (MAE), respectively. By incorporating a predictive feedback mechanism that adapts to data distribution drift, Future-Guided Learning offers a promising avenue for advancing time-series forecasting with deep learning.
Reducing Data Bottlenecks in Distributed, Heterogeneous Neural Networks
Oct 12, 2024
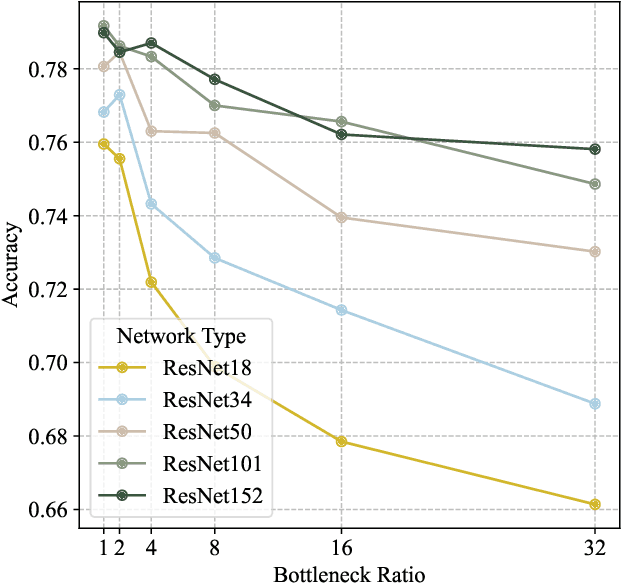
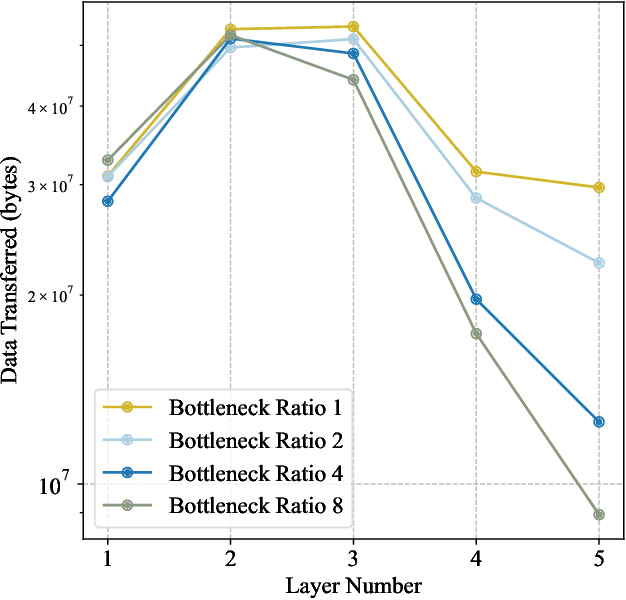
The rapid advancement of embedded multicore and many-core systems has revolutionized computing, enabling the development of high-performance, energy-efficient solutions for a wide range of applications. As models scale up in size, data movement is increasingly the bottleneck to performance. This movement of data can exist between processor and memory, or between cores and chips. This paper investigates the impact of bottleneck size, in terms of inter-chip data traffic, on the performance of deep learning models in embedded multicore and many-core systems. We conduct a systematic analysis of the relationship between bottleneck size, computational resource utilization, and model accuracy. We apply a hardware-software co-design methodology where data bottlenecks are replaced with extremely narrow layers to reduce the amount of data traffic. In effect, time-multiplexing of signals is replaced by learnable embeddings that reduce the demands on chip IOs. Our experiments on the CIFAR100 dataset demonstrate that the classification accuracy generally decreases as the bottleneck ratio increases, with shallower models experiencing a more significant drop compared to deeper models. Hardware-side evaluation reveals that higher bottleneck ratios lead to substantial reductions in data transfer volume across the layers of the neural network. Through this research, we can determine the trade-off between data transfer volume and model performance, enabling the identification of a balanced point that achieves good performance while minimizing data transfer volume. This characteristic allows for the development of efficient models that are well-suited for resource-constrained environments.
CopyLens: Dynamically Flagging Copyrighted Sub-Dataset Contributions to LLM Outputs
Oct 06, 2024



Large Language Models (LLMs) have become pervasive due to their knowledge absorption and text-generation capabilities. Concurrently, the copyright issue for pretraining datasets has been a pressing concern, particularly when generation includes specific styles. Previous methods either focus on the defense of identical copyrighted outputs or find interpretability by individual tokens with computational burdens. However, the gap between them exists, where direct assessments of how dataset contributions impact LLM outputs are missing. Once the model providers ensure copyright protection for data holders, a more mature LLM community can be established. To address these limitations, we introduce CopyLens, a new framework to analyze how copyrighted datasets may influence LLM responses. Specifically, a two-stage approach is employed: First, based on the uniqueness of pretraining data in the embedding space, token representations are initially fused for potential copyrighted texts, followed by a lightweight LSTM-based network to analyze dataset contributions. With such a prior, a contrastive-learning-based non-copyright OOD detector is designed. Our framework can dynamically face different situations and bridge the gap between current copyright detection methods. Experiments show that CopyLens improves efficiency and accuracy by 15.2% over our proposed baseline, 58.7% over prompt engineering methods, and 0.21 AUC over OOD detection baselines.
When Spiking neural networks meet temporal attention image decoding and adaptive spiking neuron
Jun 05, 2024



Spiking Neural Networks (SNNs) are capable of encoding and processing temporal information in a biologically plausible way. However, most existing SNN-based methods for image tasks do not fully exploit this feature. Moreover, they often overlook the role of adaptive threshold in spiking neurons, which can enhance their dynamic behavior and learning ability. To address these issues, we propose a novel method for image decoding based on temporal attention (TAID) and an adaptive Leaky-Integrate-and-Fire (ALIF) neuron model. Our method leverages the temporal information of SNN outputs to generate high-quality images that surpass the state-of-the-art (SOTA) in terms of Inception score, Fr\'echet Inception Distance, and Fr\'echet Autoencoder Distance. Furthermore, our ALIF neuron model achieves remarkable classification accuracy on MNIST (99.78\%) and CIFAR-10 (93.89\%) datasets, demonstrating the effectiveness of learning adaptive thresholds for spiking neurons. The code is available at https://github.com/bollossom/ICLR_TINY_SNN.