 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDF-HR: Pose Distance Fields for Humanoid Robots
Feb 04, 2026Pose and motion priors play a crucial role in humanoid robotics. Although such priors have been widely studied in human motion recovery (HMR) domain with a range of models, their adoption for humanoid robots remains limited, largely due to the scarcity of high-quality humanoid motion data. In this work, we introduce Pose Distance Fields for Humanoid Robots (PDF-HR), a lightweight prior that represents the robot pose distribution as a continuous and differentiable manifold. Given an arbitrary pose, PDF-HR predicts its distance to a large corpus of retargeted robot poses, yielding a smooth measure of pose plausibility that is well suited for optimization and control. PDF-HR can be integrated as a reward shaping term, a regularizer, or a standalone plausibility scorer across diverse pipelines. We evaluate PDF-HR on various humanoid tasks, including single-trajectory motion tracking, general motion tracking, style-based motion mimicry, and general motion retargeting. Experiments show that this plug-and-play prior consistently and substantially strengthens strong baselines. Code and models will be released.
Diffusion Model-based Reinforcement Learning for Version Age of Information Scheduling: Average and Tail-Risk-Sensitive Control
Jan 26, 2026Ensuring timely and semantically accurate information delivery is critical in real-time wireless systems. While Age of Information (AoI) quantifies temporal freshness, Version Age of Information (VAoI) captures semantic staleness by accounting for version evolution between transmitters and receivers. Existing VAoI scheduling approaches primarily focus on minimizing average VAoI, overlooking rare but severe staleness events that can compromise reliability under stochastic packet arrivals and unreliable channels. This paper investigates both average-oriented and tail-risk-sensitive VAoI scheduling in a multi-user status update system with long-term transmission cost constraints. We first formulate the average VAoI minimization problem as a constrained Markov decision process and introduce a deep diffusion-based Soft Actor-Critic (D2SAC) algorithm. By generating actions through a diffusion-based denoising process, D2SAC enhances policy expressiveness and establishes a strong baseline for mean performance. Building on this foundation, we put forth RS-D3SAC, a risk-sensitive deep distributional diffusion-based Soft Actor-Critic algorithm. RS-D3SAC integrates a diffusion-based actor with a quantile-based distributional critic, explicitly modeling the full VAoI return distribution. This enables principled tail-risk optimization via Conditional Value-at-Risk (CVaR) while satisfying long-term transmission cost constraints. Extensive simulations show that, while D2SAC reduces average VAoI, RS-D3SAC consistently achieves substantial reductions in CVaR without sacrificing mean performance. The dominant gain in tail-risk reduction stems from the distributional critic, with the diffusion-based actor providing complementary refinement to stabilize and enrich policy decisions, highlighting their effectiveness for robust and risk-aware VAoI scheduling in multi-user wireless systems.
Sharpening Your Density Fields: Spiking Neuron Aided Fast Geometry Learning
Dec 13, 2024



Neural Radiance Fields (NeRF) have achieved remarkable progress in neural rendering. Extracting geometry from NeRF typically relies on the Marching Cubes algorithm, which uses a hand-crafted threshold to define the level set. However, this threshold-based approach requires laborious and scenario-specific tuning, limiting its practicality for real-world applications. In this work, we seek to enhance the efficiency of this method during the training time. To this end, we introduce a spiking neuron mechanism that dynamically adjusts the threshold, eliminating the need for manual selection. Despite its promise, directly training with the spiking neuron often results in model collapse and noisy outputs. To overcome these challenges, we propose a round-robin strategy that stabilizes the training process and enables the geometry network to achieve a sharper and more precise density distribution with minimal computational overhead. We validate our approach through extensive experiments on both synthetic and real-world datasets. The results show that our method significantly improves the performance of threshold-based techniques, offering a more robust and efficient solution for NeRF geometry extraction.
Robust SG-NeRF: Robust Scene Graph Aided Neural Surface Reconstruction
Nov 20, 2024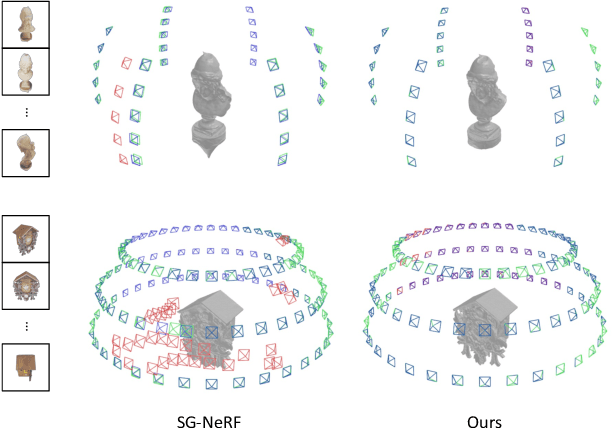
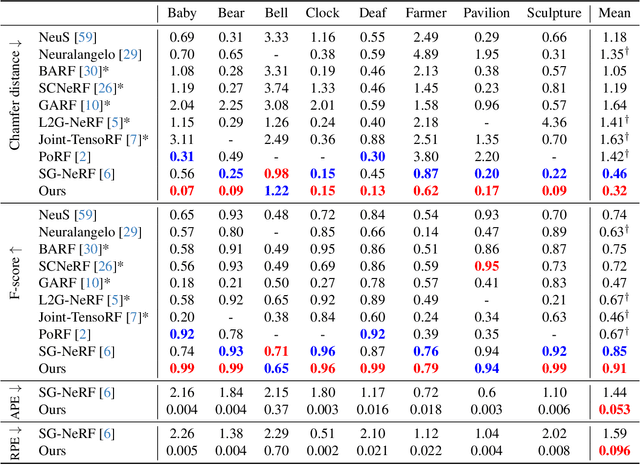
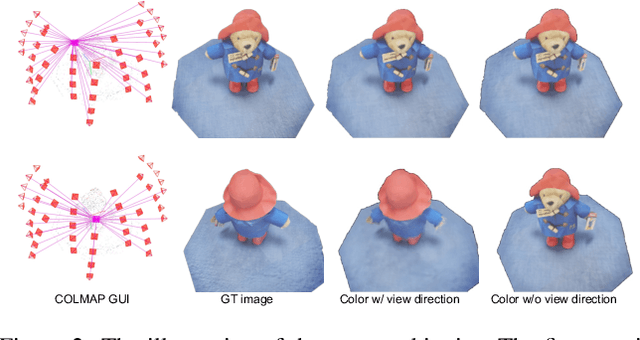

Neural surface reconstruction relies heavily on accurate camera poses as input. Despite utilizing advanced pose estimators like COLMAP or ARKit, camera poses can still be noisy. Existing pose-NeRF joint optimization methods handle poses with small noise (inliers) effectively but struggle with large noise (outliers), such as mirrored poses. In this work, we focus on mitigating the impact of outlier poses. Our method integrates an inlier-outlier confidence estimation scheme, leveraging scene graph information gathered during the data preparation phase. Unlike previous works directly using rendering metrics as the reference, we employ a detached color network that omits the viewing direction as input to minimize the impact caused by shape-radiance ambiguities. This enhanced confidence updating strategy effectively differentiates between inlier and outlier poses, allowing us to sample more rays from inlier poses to construct more reliable radiance fields. Additionally, we introduce a re-projection loss based on the current Signed Distance Function (SDF) and pose estimations, strengthening the constraints between matching image pairs. For outlier poses, we adopt a Monte Carlo re-localization method to find better solutions. We also devise a scene graph updating strategy to provide more accurate information throughout the training process. We validate our approach on the SG-NeRF and DTU datasets. Experimental results on various datasets demonstrate that our methods can consistently improve the reconstruction qualities and pose accuracies.
User Centric Semantic Communications
Nov 05, 2024Current studies on semantic communications mainly focus on efficiently extracting semantic information to reduce bandwidth usage between a transmitter and a user. Although significant process has been made in the semantic communications, a fundamental design problem is that the semantic information is extracted based on certain criteria at the transmitter side along, without considering the user's actual requirements. As a result, critical information that is of primary concern to the user may be lost. In such cases, the semantic transmission becomes meaningless to the user, as all received information is irrelevant to the user's interests. To solve this problem, this paper presents a user centric semantic communication system, where the user sends its request for the desired semantic information to the transmitter at the start of each transmission. Then, the transmitter extracts the required semantic information accordingly. A key challenge is how the transmitter can understand the user's requests for semantic information and extract the required semantic information in a reasonable and robust manner. We solve this challenge by designing a well-structured framework and leveraging off-the-shelf products, such as GPT-4, along with several specialized tools for detection and estimation. Evaluation results demonstrate the feasibility and effectiveness of the proposed user centric semantic communication system.
Finding Defective Elements in Intelligent Reflecting Surface via Over-the-Air Measurements
Aug 01, 2024Due to circuit failures, defective elements that cannot adaptively adjust the phase shifts of their impinging signals in a desired manner may exist on an intelligent reflecting surface (IRS). Traditional way to find these defective IRS elements requires a thorough diagnosis of all the circuits belonging to a huge number of IRS elements, which is practically challenging. In this paper, we will devise a novel approach under which a transmitter sends known pilot signals and a receiver localizes all the defective IRS elements just based on its over-the-air measurements reflected from the IRS. The key lies in the fact that the over-the-air measurements at the receiver side are functions of the set of defective IRS elements. Based on this observation, we propose a bisection based method to localize all the defective IRS elements. Specifically, at each time slot, we properly control the desired phase shifts of all the IRS elements such that half of the considered regime that is not useful to localize the defective elements can be found based on the received signals and removed. Via numerical results, it is shown that our proposed bisection method can exploit the over-the-air measurements to localize all the defective IRS elements quickly and accurately.
When Spiking neural networks meet temporal attention image decoding and adaptive spiking neuron
Jun 05, 2024



Spiking Neural Networks (SNNs) are capable of encoding and processing temporal information in a biologically plausible way. However, most existing SNN-based methods for image tasks do not fully exploit this feature. Moreover, they often overlook the role of adaptive threshold in spiking neurons, which can enhance their dynamic behavior and learning ability. To address these issues, we propose a novel method for image decoding based on temporal attention (TAID) and an adaptive Leaky-Integrate-and-Fire (ALIF) neuron model. Our method leverages the temporal information of SNN outputs to generate high-quality images that surpass the state-of-the-art (SOTA) in terms of Inception score, Fr\'echet Inception Distance, and Fr\'echet Autoencoder Distance. Furthermore, our ALIF neuron model achieves remarkable classification accuracy on MNIST (99.78\%) and CIFAR-10 (93.89\%) datasets, demonstrating the effectiveness of learning adaptive thresholds for spiking neurons. The code is available at https://github.com/bollossom/ICLR_TINY_SNN.
Rethinking Grant-Free Protocol in mMTC
Apr 24, 2024This paper revisits the identity detection problem under the current grant-free protocol in massive machine-type communications (mMTC) by asking the following question: for stable identity detection performance, is it enough to permit active devices to transmit preambles without any handshaking with the base station (BS)? Specifically, in the current grant-free protocol, the BS blindly allocates a fixed length of preamble to devices for identity detection as it lacks the prior information on the number of active devices $K$. However, in practice, $K$ varies dynamically over time, resulting in degraded identity detection performance especially when $K$ is large. Consequently, the current grant-free protocol fails to ensure stable identity detection performance. To address this issue, we propose a two-stage communication protocol which consists of estimation of $K$ in Phase I and detection of identities of active devices in Phase II. The preamble length for identity detection in Phase II is dynamically allocated based on the estimated $K$ in Phase I through a table lookup manner such that the identity detection performance could always be better than a predefined threshold. In addition, we design an algorithm for estimating $K$ in Phase I, and exploit the estimated $K$ to reduce the computational complexity of the identity detector in Phase II. Numerical results demonstrate the effectiveness of the proposed two-stage communication protocol and algorithms.
Combating Multi-path Interference to Improve Chirp-based Underwater Acoustic Communication
Nov 29, 2023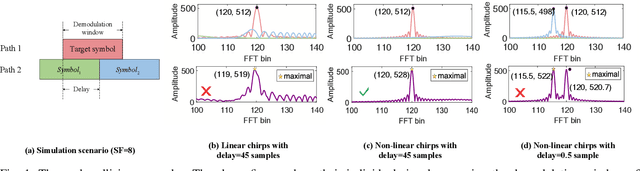
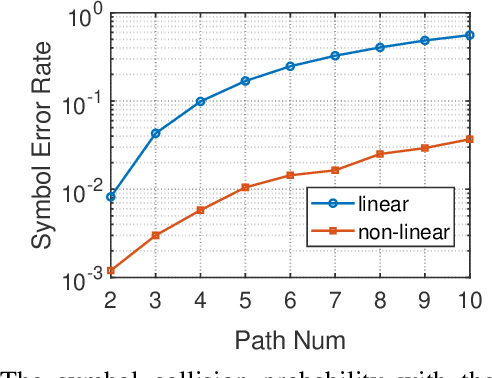
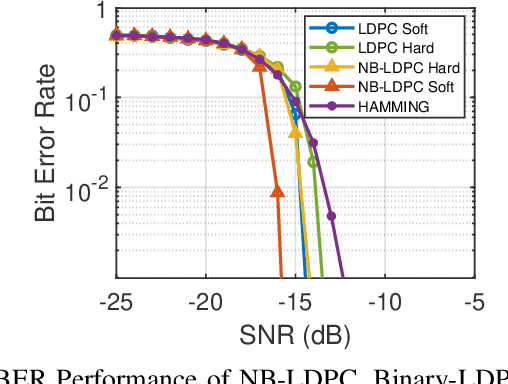
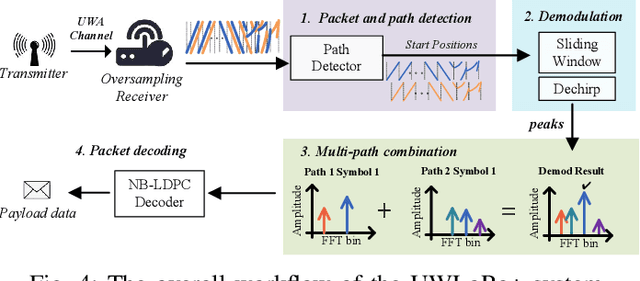
Linear chirp-based underwater acoustic communication has been widely used due to its reliability and long-range transmission capability. However, unlike the counterpart chirp technology in wireless -- LoRa, its throughput is severely limited by the number of modulated chirps in a symbol. The fundamental challenge lies in the underwater multi-path channel, where the delayed copied of one symbol may cause inter-symbol and intra-symbol interfere. In this paper, we present UWLoRa+, a system that realizes the same chirp modulation as LoRa with higher data rate, and enhances LoRa's design to address the multi-path challenge via the following designs: a) we replace the linear chirp used by LoRa with the non-linear chirp to reduce the signal interference range and the collision probability; b) we design an algorithm that first demodulates each path and then combines the demodulation results of detected paths; and c) we replace the Hamming codes used by LoRa with the non-binary LDPC codes to mitigate the impact of the inevitable collision.Experiment results show that the new designs improve the bit error rate (BER) by 3x, and the packet error rate (PER) significantly, compared with the LoRa's naive design. Compared with an state-of-the-art system for decoding underwater LoRa chirp signal, UWLoRa+ improves the throughput by up to 50 times.
Covariance-Based Activity Detection in Cooperative Multi-Cell Massive MIMO: Scaling Law and Efficient Algorithms
Nov 26, 2023


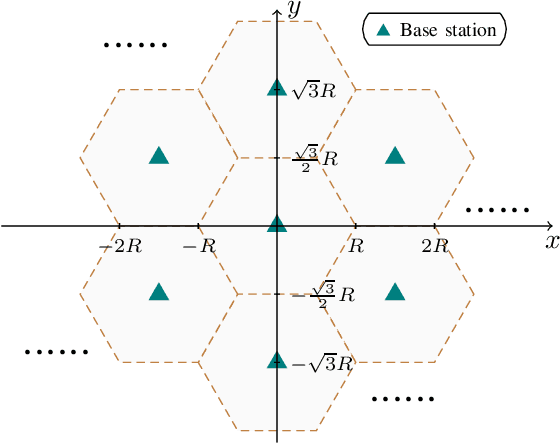
This paper focuses on the covariance-based activity detection problem in a multi-cell massive multiple-input multiple-output (MIMO) system. In this system, active devices transmit their signature sequences to multiple base stations (BSs), and the BSs cooperatively detect the active devices based on the received signals. While the scaling law for the covariance-based activity detection in the single-cell scenario has been extensively analyzed in the literature, this paper aims to analyze the scaling law for the covariance-based activity detection in the multi-cell massive MIMO system. Specifically, this paper demonstrates a quadratic scaling law in the multi-cell system, under the assumption that the exponent in the classical path-loss model is greater than 2. This finding shows that, in the multi-cell MIMO system, the maximum number of active devices that can be detected correctly in each cell increases quadratically with the length of the signature sequence and decreases logarithmically with the number of cells (as the number of antennas tends to infinity). Moreover, in addition to analyzing the scaling law for the signature sequences randomly and uniformly distributed on a sphere, the paper also establishes the scaling law for signature sequences generated from a finite alphabet, which are easier to generate and store. Moreover, this paper proposes two efficient accelerated coordinate descent (CD) algorithms with a convergence guarantee for solving the device activity detection problem. The first algorithm reduces the complexity of CD by using an inexact coordinate update strategy. The second algorithm avoids unnecessary computations of CD by using an active set selection strategy. Simulation results show that the proposed algorithms exhibit excellent performance in terms of computational efficiency and detection error probability.