 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating Multi-path Interference to Improve Chirp-based Underwater Acoustic Communication
Nov 29, 2023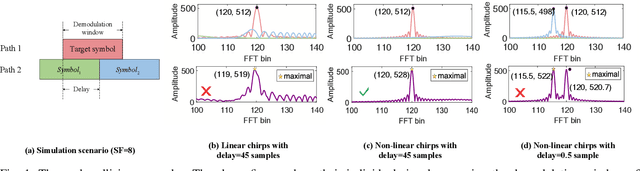
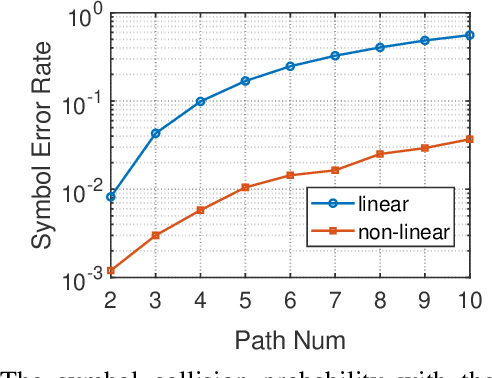
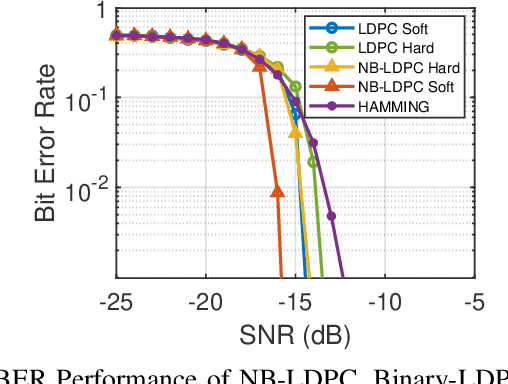
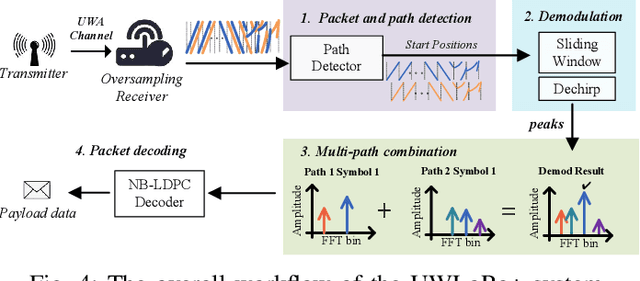
Linear chirp-based underwater acoustic communication has been widely used due to its reliability and long-range transmission capability. However, unlike the counterpart chirp technology in wireless -- LoRa, its throughput is severely limited by the number of modulated chirps in a symbol. The fundamental challenge lies in the underwater multi-path channel, where the delayed copied of one symbol may cause inter-symbol and intra-symbol interfere. In this paper, we present UWLoRa+, a system that realizes the same chirp modulation as LoRa with higher data rate, and enhances LoRa's design to address the multi-path challenge via the following designs: a) we replace the linear chirp used by LoRa with the non-linear chirp to reduce the signal interference range and the collision probability; b) we design an algorithm that first demodulates each path and then combines the demodulation results of detected paths; and c) we replace the Hamming codes used by LoRa with the non-binary LDPC codes to mitigate the impact of the inevitable collision.Experiment results show that the new designs improve the bit error rate (BER) by 3x, and the packet error rate (PER) significantly, compared with the LoRa's naive design. Compared with an state-of-the-art system for decoding underwater LoRa chirp signal, UWLoRa+ improves the throughput by up to 50 times.
GUN: Gradual Upsampling Network for Single Image Super-Resolution
Jul 04, 2018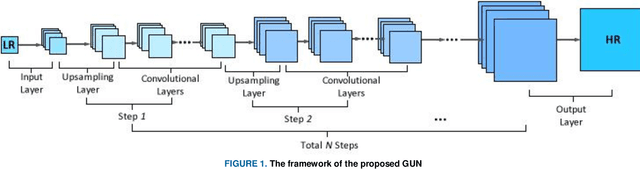

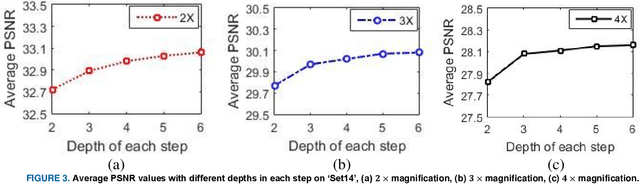
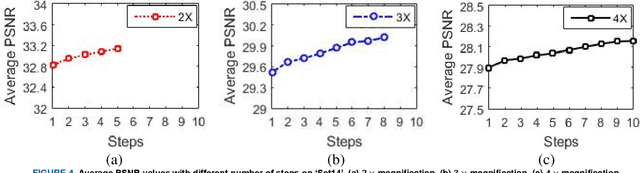
In this paper, an efficient super-resolution (SR) method based on deep convolutional neural network (CNN) is proposed, namely Gradual Upsampling Network (GUN). Recent CNN based SR methods often preliminarily magnify the low resolution (LR) input to high resolution (HR) and then reconstruct the HR input, or directly reconstruct the LR input and then recover the HR result at the last layer. The proposed GUN utilizes a gradual process instead of these two commonly used frameworks. The GUN consists of an input layer, multiple upsampling and convolutional layers, and an output layer. By means of the gradual process, the proposed network can simplify the direct SR problem to multistep easier upsampling tasks with very small magnification factor in each step. Furthermore, a gradual training strategy is presented for the GUN. In the proposed training process, an initial network can be easily trained with edge-like samples, and then the weights are gradually tuned with more complex samples. The GUN can recover fine and vivid results, and is easy to be trained. The experimental results on several image sets demonstrate the effectiveness of the proposed network.