 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphe: High-Fidelity Generative Video Streaming with Vision Foundation Model
Feb 03, 2026Video streaming is a fundamental Internet service, while the quality still cannot be guaranteed especially in poor network conditions such as bandwidth-constrained and remote areas. Existing works mainly work towards two directions: traditional pixel-codec streaming nearly approaches its limit and is hard to step further in compression; the emerging neural-enhanced or generative streaming usually fall short in latency and visual fidelity, hindering their practical deployment. Inspired by the recent success of vision foundation model (VFM), we strive to harness the powerful video understanding and processing capacities of VFM to achieve generalization, high fidelity and loss resilience for real-time video streaming with even higher compression rate. We present the first revolutionized paradigm that enables VFM-based end-to-end generative video streaming towards this goal. Specifically, Morphe employs joint training of visual tokenizers and variable-resolution spatiotemporal optimization under simulated network constraints. Additionally, a robust streaming system is constructed that leverages intelligent packet dropping to resist real-world network perturbations. Extensive evaluation demonstrates that Morphe achieves comparable visual quality while saving 62.5\% bandwidth compared to H.265, and accomplishes real-time, loss-resilient video delivery in challenging network environments, representing a milestone in VFM-enabled multimedia streaming solutions.
ViTMAlis: Towards Latency-Critical Mobile Video Analytics with Vision Transformers
Jan 29, 2026Edge-assisted mobile video analytics (MVA) applications are increasingly shifting from using vision models based on convolutional neural networks (CNNs) to those built on vision transformers (ViTs) to leverage their superior global context modeling and generalization capabilities. However, deploying these advanced models in latency-critical MVA scenarios presents significant challenges. Unlike traditional CNN-based offloading paradigms where network transmission is the primary bottleneck, ViT-based systems are constrained by substantial inference delays, particularly for dense prediction tasks where the need for high-resolution inputs exacerbates the inherent quadratic computational complexity of ViTs. To address these challenges, we propose a dynamic mixed-resolution inference strategy tailored for ViT-backboned dense prediction models, enabling flexible runtime trade-offs between speed and accuracy. Building on this, we introduce ViTMAlis, a ViT-native device-to-edge offloading framework that dynamically adapts to network conditions and video content to jointly reduce transmission and inference delays. We implement a fully functional prototype of ViTMAlis on commodity mobile and edge devices. Extensive experiments demonstrate that, compared to state-of-the-art accuracy-centric, content-aware, and latency-adaptive baselines, ViTMAlis significantly reduces end-to-end offloading latency while improving user-perceived rendering accuracy, providing a practical foundation for next-generation mobile intelligence.
OmniSense: Towards Edge-Assisted Online Analytics for 360-Degree Videos
Aug 19, 2025With the reduced hardware costs of omnidirectional cameras and the proliferation of various extended reality applications, more and more $360^\circ$ videos are being captured. To fully unleash their potential, advanced video analytics is expected to extract actionable insights and situational knowledge without blind spots from the videos. In this paper, we present OmniSense, a novel edge-assisted framework for online immersive video analytics. OmniSense achieves both low latency and high accuracy, combating the significant computation and network resource challenges of analyzing $360^\circ$ videos. Motivated by our measurement insights into $360^\circ$ videos, OmniSense introduces a lightweight spherical region of interest (SRoI) prediction algorithm to prune redundant information in $360^\circ$ frames. Incorporating the video content and network dynamics, it then smartly scales vision models to analyze the predicted SRoIs with optimized resource utilization. We implement a prototype of OmniSense with commodity devices and evaluate it on diverse real-world collected $360^\circ$ videos. Extensive evaluation results show that compared to resource-agnostic baselines, it improves the accuracy by $19.8\%$ -- $114.6\%$ with similar end-to-end latencies. Meanwhile, it hits $2.0\times$ -- $2.4\times$ speedups while keeping the accuracy on par with the highest accuracy of baselines.
DeepForm: Reasoning Large Language Model for Communication System Formulation
Jun 11, 2025Communication system formulation is critical for advancing 6G and future wireless technologies, yet it remains a complex, expertise-intensive task. While Large Language Models (LLMs) offer potential, existing general-purpose models often lack the specialized domain knowledge, nuanced reasoning capabilities, and access to high-quality, domain-specific training data required for adapting a general LLM into an LLM specially for communication system formulation. To bridge this gap, we introduce DeepForm, the first reasoning LLM specially for automated communication system formulation. We propose the world-first large-scale, open-source dataset meticulously curated for this domain called Communication System Formulation Reasoning Corpus (CSFRC). Our framework employs a two-stage training strategy: first, Supervised Fine-Tuning (SFT) with Chain-of-Thought (CoT) data to distill domain knowledge; second, a novel rule-based Reinforcement Learning (RL) algorithm, C-ReMax based on ReMax, to cultivate advanced modeling capabilities and elicit sophisticated reasoning patterns like self-correction and verification. Extensive experiments demonstrate that our model achieves state-of-the-art performance, significantly outperforming larger proprietary LLMs on diverse senerios. We will release related resources to foster further research in this area after the paper is accepted.
ExScene: Free-View 3D Scene Reconstruction with Gaussian Splatting from a Single Image
Mar 31, 2025The increasing demand for augmented and virtual reality applications has highlighted the importance of crafting immersive 3D scenes from a simple single-view image. However, due to the partial priors provided by single-view input, existing methods are often limited to reconstruct low-consistency 3D scenes with narrow fields of view from single-view input. These limitations make them less capable of generalizing to reconstruct immersive scenes. To address this problem, we propose ExScene, a two-stage pipeline to reconstruct an immersive 3D scene from any given single-view image. ExScene designs a novel multimodal diffusion model to generate a high-fidelity and globally consistent panoramic image. We then develop a panoramic depth estimation approach to calculate geometric information from panorama, and we combine geometric information with high-fidelity panoramic image to train an initial 3D Gaussian Splatting (3DGS) model. Following this, we introduce a GS refinement technique with 2D stable video diffusion priors. We add camera trajectory consistency and color-geometric priors into the denoising process of diffusion to improve color and spatial consistency across image sequences. These refined sequences are then used to fine-tune the initial 3DGS model, leading to better reconstruction quality. Experimental results demonstrate that our ExScene achieves consistent and immersive scene reconstruction using only single-view input, significantly surpassing state-of-the-art baselines.
Topology-Aware Conformal Prediction for Stream Networks
Mar 06, 2025



Stream networks, a unique class of spatiotemporal graphs, exhibit complex directional flow constraints and evolving dependencies, making uncertainty quantification a critical yet challenging task. Traditional conformal prediction methods struggle in this setting due to the need for joint predictions across multiple interdependent locations and the intricate spatio-temporal dependencies inherent in stream networks. Existing approaches either neglect dependencies, leading to overly conservative predictions, or rely solely on data-driven estimations, failing to capture the rich topological structure of the network. To address these challenges, we propose Spatio-Temporal Adaptive Conformal Inference (\texttt{STACI}), a novel framework that integrates network topology and temporal dynamics into the conformal prediction framework. \texttt{STACI} introduces a topology-aware nonconformity score that respects directional flow constraints and dynamically adjusts prediction sets to account for temporal distributional shifts. We provide theoretical guarantees on the validity of our approach and demonstrate its superior performance on both synthetic and real-world datasets. Our results show that \texttt{STACI} effectively balances prediction efficiency and coverage, outperforming existing conformal prediction methods for stream networks.
Generative Semantic Communication: Architectures, Technologies, and Applications
Dec 11, 2024



This paper delves into the applications of generative artificial intelligence (GAI) in semantic communication (SemCom) and presents a thorough study. Three popular SemCom systems enabled by classical GAI models are first introduced, including variational autoencoders, generative adversarial networks, and diffusion models. For each system, the fundamental concept of the GAI model, the corresponding SemCom architecture, and the associated literature review of recent efforts are elucidated. Then, a novel generative SemCom system is proposed by incorporating the cutting-edge GAI technology-large language models (LLMs). This system features two LLM-based AI agents at both the transmitter and receiver, serving as "brains" to enable powerful information understanding and content regeneration capabilities, respectively. This innovative design allows the receiver to directly generate the desired content, instead of recovering the bit stream, based on the coded semantic information conveyed by the transmitter. Therefore, it shifts the communication mindset from "information recovery" to "information regeneration" and thus ushers in a new era of generative SemCom. A case study on point-to-point video retrieval is presented to demonstrate the superiority of the proposed generative SemCom system, showcasing a 99.98% reduction in communication overhead and a 53% improvement in retrieval accuracy compared to the traditional communication system. Furthermore, four typical application scenarios for generative SemCom are delineated, followed by a discussion of three open issues warranting future investigation. In a nutshell, this paper provides a holistic set of guidelines for applying GAI in SemCom, paving the way for the efficient implementation of generative SemCom in future wireless networks.
Federated In-Context LLM Agent Learning
Dec 11, 2024



Large Language Models (LLMs) have revolutionized intelligent services by enabling logical reasoning, tool use, and interaction with external systems as agents. The advancement of LLMs is frequently hindered by the scarcity of high-quality data, much of which is inherently sensitive. Federated learning (FL) offers a potential solution by facilitating the collaborative training of distributed LLMs while safeguarding private data. However, FL frameworks face significant bandwidth and computational demands, along with challenges from heterogeneous data distributions. The emerging in-context learning capability of LLMs offers a promising approach by aggregating natural language rather than bulky model parameters. Yet, this method risks privacy leakage, as it necessitates the collection and presentation of data samples from various clients during aggregation. In this paper, we propose a novel privacy-preserving Federated In-Context LLM Agent Learning (FICAL) algorithm, which to our best knowledge for the first work unleashes the power of in-context learning to train diverse LLM agents through FL. In our design, knowledge compendiums generated by a novel LLM-enhanced Knowledge Compendiums Generation (KCG) module are transmitted between clients and the server instead of model parameters in previous FL methods. Apart from that, an incredible Retrieval Augmented Generation (RAG) based Tool Learning and Utilizing (TLU) module is designed and we incorporate the aggregated global knowledge compendium as a teacher to teach LLM agents the usage of tools. We conducted extensive experiments and the results show that FICAL has competitive performance compared to other SOTA baselines with a significant communication cost decrease of $\mathbf{3.33\times10^5}$ times.
User Centric Semantic Communications
Nov 05, 2024Current studies on semantic communications mainly focus on efficiently extracting semantic information to reduce bandwidth usage between a transmitter and a user. Although significant process has been made in the semantic communications, a fundamental design problem is that the semantic information is extracted based on certain criteria at the transmitter side along, without considering the user's actual requirements. As a result, critical information that is of primary concern to the user may be lost. In such cases, the semantic transmission becomes meaningless to the user, as all received information is irrelevant to the user's interests. To solve this problem, this paper presents a user centric semantic communication system, where the user sends its request for the desired semantic information to the transmitter at the start of each transmission. Then, the transmitter extracts the required semantic information accordingly. A key challenge is how the transmitter can understand the user's requests for semantic information and extract the required semantic information in a reasonable and robust manner. We solve this challenge by designing a well-structured framework and leveraging off-the-shelf products, such as GPT-4, along with several specialized tools for detection and estimation. Evaluation results demonstrate the feasibility and effectiveness of the proposed user centric semantic communication system.
BANGS: Game-Theoretic Node Selection for Graph Self-Training
Oct 12, 2024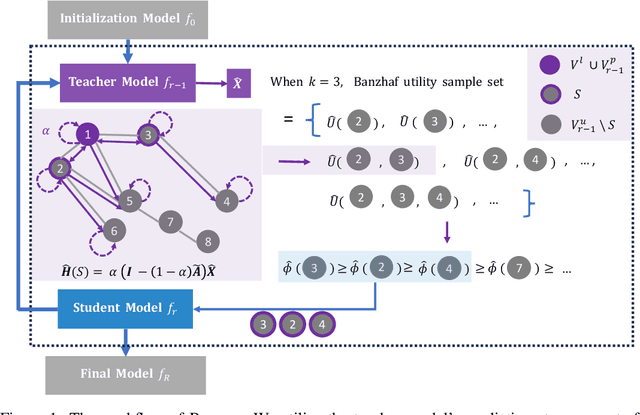
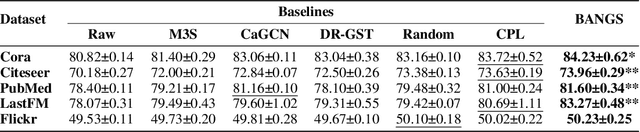

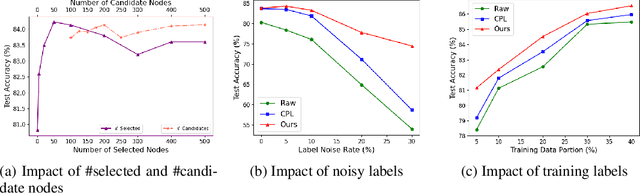
Graph self-training is a semi-supervised learning method that iteratively selects a set of unlabeled data to retrain the underlying graph neural network (GNN) model and improve its prediction performance. While selecting highly confident nodes has proven effective for self-training, this pseudo-labeling strategy ignores the combinatorial dependencies between nodes and suffers from a local view of the distribution. To overcome these issues, we propose BANGS, a novel framework that unifies the labeling strategy with conditional mutual information as the objective of node selection. Our approach -- grounded in game theory -- selects nodes in a combinatorial fashion and provides theoretical guarantees for robustness under noisy objective. More specifically, unlike traditional methods that rank and select nodes independently, BANGS considers nodes as a collective set in the self-training process. Our method demonstrates superior performance and robustness across various datasets, base models, and hyperparameter settings, outperforming existing techniques. The codebase is available on https://github.com/fangxin-wang/BANGS .