 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Splitting Enhanced Communication-Efficient Federated Learning for CSI Feedback
Jun 04, 2025Recent advancements have introduced federated machine learning-based channel state information (CSI) compression before the user equipments (UEs) upload the downlink CSI to the base transceiver station (BTS). However, most existing algorithms impose a high communication overhead due to frequent parameter exchanges between UEs and BTS. In this work, we propose a model splitting approach with a shared model at the BTS and multiple local models at the UEs to reduce communication overhead. Moreover, we implant a pipeline module at the BTS to reduce training time. By limiting exchanges of boundary parameters during forward and backward passes, our algorithm can significantly reduce the exchanged parameters over the benchmarks during federated CSI feedback training.
Fine-Tuning and Deploying Large Language Models Over Edges: Issues and Approaches
Aug 20, 2024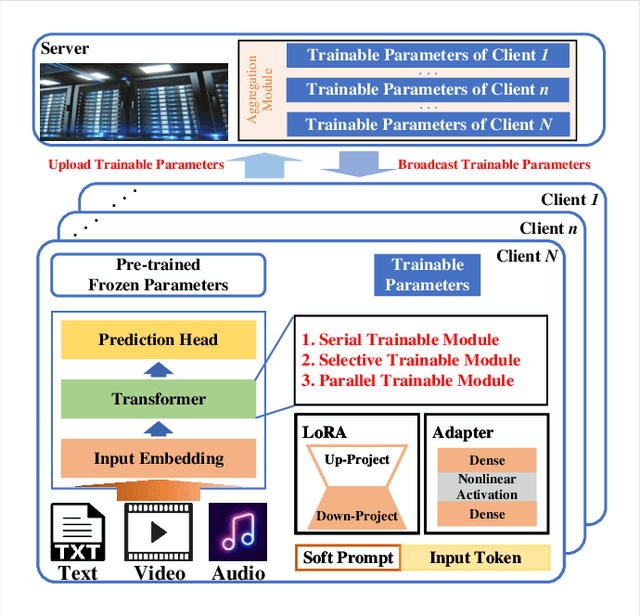
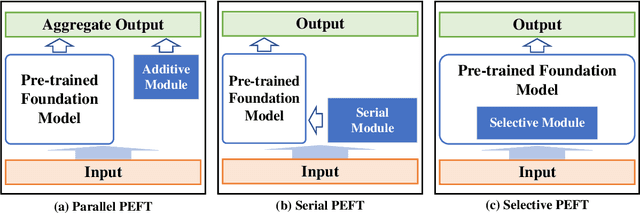
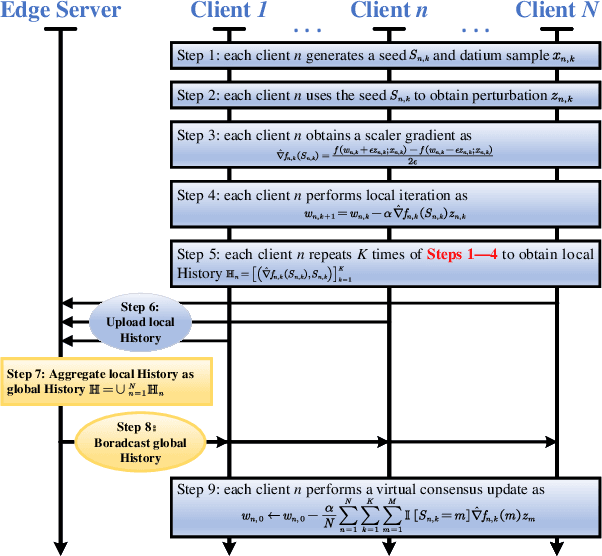
Since the invention of GPT2--1.5B in 2019, large language models (LLMs) have transitioned from specialized models to versatile foundation models. The LLMs exhibit impressive zero-shot ability, however, require fine-tuning on local datasets and significant resources for deployment. Traditional fine-tuning techniques with the first-order optimizers require substantial GPU memory that exceeds mainstream hardware capability. Therefore, memory-efficient methods are motivated to be investigated. Model compression techniques can reduce energy consumption, operational costs, and environmental impact so that to support sustainable artificial intelligence advancements. Additionally, large-scale foundation models have expanded to create images, audio, videos, and multi-modal contents, further emphasizing the need for efficient deployment. Therefore, we are motivated to present a comprehensive overview of the prevalent memory-efficient fine-tuning methods over the network edge. We also review the state-of-the-art literatures on model compression to provide a vision on deploying LLMs over the network edge.
Physics Inspired Criterion for Pruning-Quantization Joint Learning
Dec 01, 2023Pruning-quantization joint learning always facilitates the deployment of deep neural networks (DNNs) on resource-constrained edge devices. However, most existing methods do not jointly learn a global criterion for pruning and quantization in an interpretable way. In this paper, we propose a novel physics inspired criterion for pruning-quantization joint learning (PIC-PQ), which is explored from an analogy we first draw between elasticity dynamics (ED) and model compression (MC). Specifically, derived from Hooke's law in ED, we establish a linear relationship between the filters' importance distribution and the filter property (FP) by a learnable deformation scale in the physics inspired criterion (PIC). Furthermore, we extend PIC with a relative shift variable for a global view. To ensure feasibility and flexibility, available maximum bitwidth and penalty factor are introduced in quantization bitwidth assignment. Experiments on benchmarks of image classification demonstrate that PIC-PQ yields a good trade-off between accuracy and bit-operations (BOPs) compression ratio e.g., 54.96X BOPs compression ratio in ResNet56 on CIFAR10 with 0.10% accuracy drop and 53.24X in ResNet18 on ImageNet with 0.61% accuracy drop). The code will be available at https://github.com/fanxxxxyi/PIC-PQ.