 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZOTTA: Test-Time Adaptation with Gradient-Free Zeroth-Order Optimization
Mar 15, 2026Test-time adaptation (TTA) aims to improve model robustness under distribution shifts by adapting to unlabeled test data, but most existing methods rely on backpropagation (BP), which is computationally costly and incompatible with non-differentiable models such as quantized models, limiting practical deployment on numerous edge devices. Recent BP-free approaches alleviate overhead but remain either architecture-specific or limited in optimization capacity to handle high-dimensional models. We propose ZOTTA, a fully BP-free TTA framework that performs efficient adaptation using only forward passes via Zeroth-Order Optimization (ZOO). While ZOO is theoretically appealing, naive application leads to slow convergence under high-dimensional parameter spaces and unstable optimization due to the lack of labels. ZOTTA overcomes these challenges through 1) Distribution-Robust Layer Selection, which automatically identifies and freezes layers that already extract distribution-invariant features, updating only domain-sensitive layers to reduce the optimization dimensionality and accelerate convergence; 2) Spatial Feature Aggregation Alignment, which stabilizes ZOO by aligning globally aggregated spatial features between source and target to reduce gradient variance. Together, these components enable architecture-agnostic and stable BP-free adaptation. Extensive experiments on ImageNet-C/R/Sketch/A show that ZOTTA outperforms or matches BP-based methods, e.g., it reduces memory usage by 84% and improves accuracy by 3.9% over SAR on ImageNet-C.
FedSM: Robust Semantics-Guided Feature Mixup for Bias Reduction in Federated Learning with Long-Tail Data
Oct 31, 2025Federated Learning (FL) enables collaborative model training across decentralized clients without sharing private data. However, FL suffers from biased global models due to non-IID and long-tail data distributions. We propose \textbf{FedSM}, a novel client-centric framework that mitigates this bias through semantics-guided feature mixup and lightweight classifier retraining. FedSM uses a pretrained image-text-aligned model to compute category-level semantic relevance, guiding the category selection of local features to mix-up with global prototypes to generate class-consistent pseudo-features. These features correct classifier bias, especially when data are heavily skewed. To address the concern of potential domain shift between the pretrained model and the data, we propose probabilistic category selection, enhancing feature diversity to effectively mitigate biases. All computations are performed locally, requiring minimal server overhead. Extensive experiments on long-tail datasets with various imbalanced levels demonstrate that FedSM consistently outperforms state-of-the-art methods in accuracy, with high robustness to domain shift and computational efficiency.
An All-Reduce Compatible Top-K Compressor for Communication-Efficient Distributed Learning
Oct 30, 2025Communication remains a central bottleneck in large-scale distributed machine learning, and gradient sparsification has emerged as a promising strategy to alleviate this challenge. However, existing gradient compressors face notable limitations: Rand-$K$\ discards structural information and performs poorly in practice, while Top-$K$\ preserves informative entries but loses the contraction property and requires costly All-Gather operations. In this paper, we propose ARC-Top-$K$, an {All-Reduce}-Compatible Top-$K$ compressor that aligns sparsity patterns across nodes using a lightweight sketch of the gradient, enabling index-free All-Reduce while preserving globally significant information. ARC-Top-$K$\ is provably contractive and, when combined with momentum error feedback (EF21M), achieves linear speedup and sharper convergence rates than the original EF21M under standard assumptions. Empirically, ARC-Top-$K$\ matches the accuracy of Top-$K$\ while reducing wall-clock training time by up to 60.7\%, offering an efficient and scalable solution that combines the robustness of Rand-$K$\ with the strong performance of Top-$K$.
Model Splitting Enhanced Communication-Efficient Federated Learning for CSI Feedback
Jun 04, 2025Recent advancements have introduced federated machine learning-based channel state information (CSI) compression before the user equipments (UEs) upload the downlink CSI to the base transceiver station (BTS). However, most existing algorithms impose a high communication overhead due to frequent parameter exchanges between UEs and BTS. In this work, we propose a model splitting approach with a shared model at the BTS and multiple local models at the UEs to reduce communication overhead. Moreover, we implant a pipeline module at the BTS to reduce training time. By limiting exchanges of boundary parameters during forward and backward passes, our algorithm can significantly reduce the exchanged parameters over the benchmarks during federated CSI feedback training.
Facial Expression Analysis and Its Potentials in IoT Systems: A Contemporary Survey
Dec 23, 2024
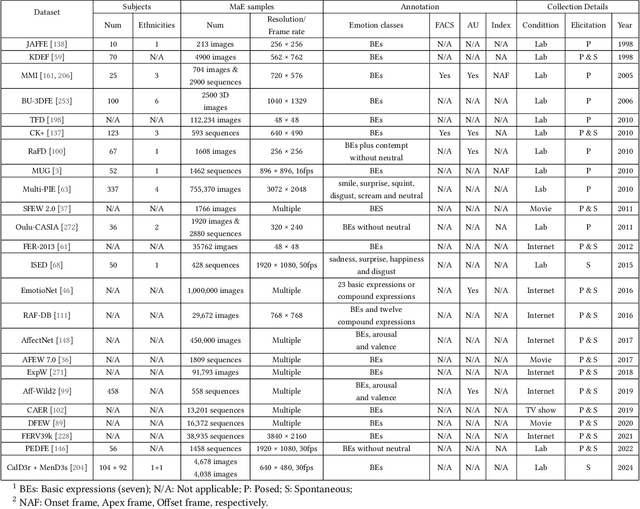

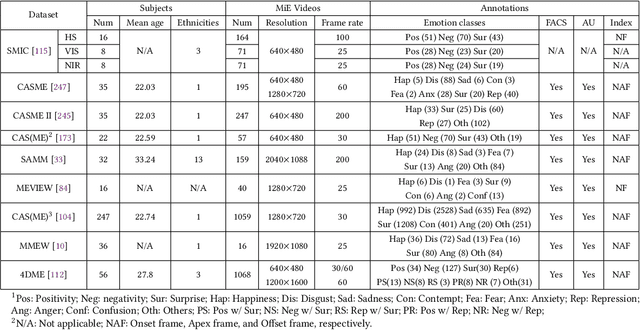
Facial expressions convey human emotions and can be categorized into macro-expressions (MaEs) and micro-expressions (MiEs) based on duration and intensity. While MaEs are voluntary and easily recognized, MiEs are involuntary, rapid, and can reveal concealed emotions. The integration of facial expression analysis with Internet-of-Thing (IoT) systems has significant potential across diverse scenarios. IoT-enhanced MaE analysis enables real-time monitoring of patient emotions, facilitating improved mental health care in smart healthcare. Similarly, IoT-based MiE detection enhances surveillance accuracy and threat detection in smart security. This work aims at providing a comprehensive overview of research progress in facial expression analysis and explores its integration with IoT systems. We discuss the distinctions between our work and existing surveys, elaborate on advancements in MaE and MiE techniques across various learning paradigms, and examine their potential applications in IoT. We highlight challenges and future directions for the convergence of facial expression-based technologies and IoT systems, aiming to foster innovation in this domain. By presenting recent developments and practical applications, this study offers a systematic understanding of how facial expression analysis can enhance IoT systems in healthcare, security, and beyond.
Fine-Tuning and Deploying Large Language Models Over Edges: Issues and Approaches
Aug 20, 2024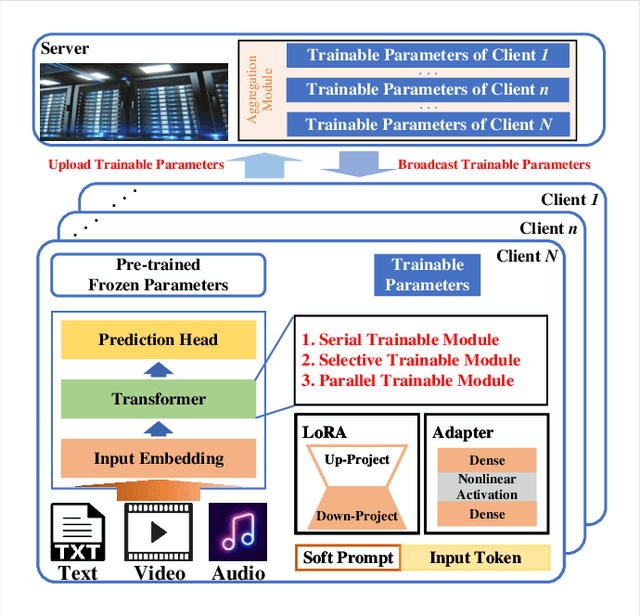
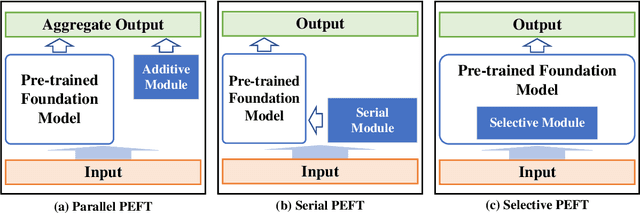
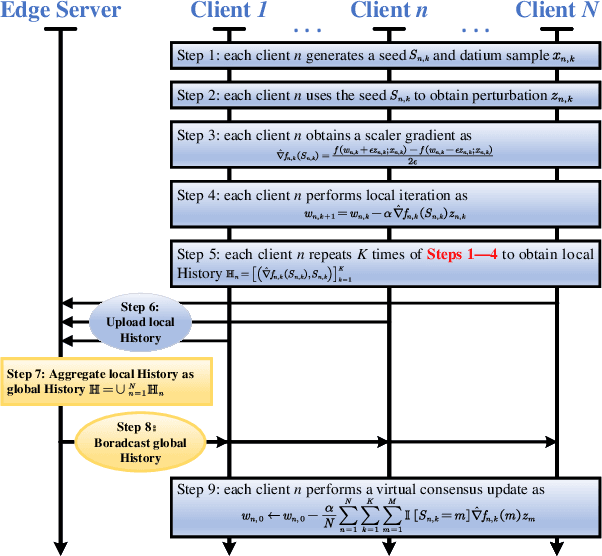
Since the invention of GPT2--1.5B in 2019, large language models (LLMs) have transitioned from specialized models to versatile foundation models. The LLMs exhibit impressive zero-shot ability, however, require fine-tuning on local datasets and significant resources for deployment. Traditional fine-tuning techniques with the first-order optimizers require substantial GPU memory that exceeds mainstream hardware capability. Therefore, memory-efficient methods are motivated to be investigated. Model compression techniques can reduce energy consumption, operational costs, and environmental impact so that to support sustainable artificial intelligence advancements. Additionally, large-scale foundation models have expanded to create images, audio, videos, and multi-modal contents, further emphasizing the need for efficient deployment. Therefore, we are motivated to present a comprehensive overview of the prevalent memory-efficient fine-tuning methods over the network edge. We also review the state-of-the-art literatures on model compression to provide a vision on deploying LLMs over the network edge.
Heavy-Ball Momentum Accelerated Actor-Critic With Function Approximation
Aug 13, 2024By using an parametric value function to replace the Monte-Carlo rollouts for value estimation, the actor-critic (AC) algorithms can reduce the variance of stochastic policy gradient so that to improve the convergence rate. While existing works mainly focus on analyzing convergence rate of AC algorithms under Markovian noise, the impacts of momentum on AC algorithms remain largely unexplored. In this work, we first propose a heavy-ball momentum based advantage actor-critic (\mbox{HB-A2C}) algorithm by integrating the heavy-ball momentum into the critic recursion that is parameterized by a linear function. When the sample trajectory follows a Markov decision process, we quantitatively certify the acceleration capability of the proposed HB-A2C algorithm. Our theoretical results demonstrate that the proposed HB-A2C finds an $\epsilon$-approximate stationary point with $\oo{\epsilon^{-2}}$ iterations for reinforcement learning tasks with Markovian noise. Moreover, we also reveal the dependence of learning rates on the length of the sample trajectory. By carefully selecting the momentum factor of the critic recursion, the proposed HB-A2C can balance the errors introduced by the initialization and the stoschastic approximation.
LMaaS: Exploring Pricing Strategy of Large Model as a Service for Communication
Jan 05, 2024



The next generation of communication is envisioned to be intelligent communication, that can replace traditional symbolic communication, where highly condensed semantic information considering both source and channel will be extracted and transmitted with high efficiency. The recent popular large models such as GPT4 and the boosting learning techniques lay a solid foundation for the intelligent communication, and prompt the practical deployment of it in the near future. Given the characteristics of "training once and widely use" of those multimodal large language models, we argue that a pay-as-you-go service mode will be suitable in this context, referred to as Large Model as a Service (LMaaS). However, the trading and pricing problem is quite complex with heterogeneous and dynamic customer environments, making the pricing optimization problem challenging in seeking on-hand solutions. In this paper, we aim to fill this gap and formulate the LMaaS market trading as a Stackelberg game with two steps. In the first step, we optimize the seller's pricing decision and propose an Iterative Model Pricing (IMP) algorithm that optimizes the prices of large models iteratively by reasoning customers' future rental decisions, which is able to achieve a near-optimal pricing solution. In the second step, we optimize customers' selection decisions by designing a robust selecting and renting (RSR) algorithm, which is guaranteed to be optimal with rigorous theoretical proof. Extensive experiments confirm the effectiveness and robustness of our algorithms.
Accelerating Wireless Federated Learning via Nesterov's Momentum and Distributed Principle Component Analysis
Mar 31, 2023
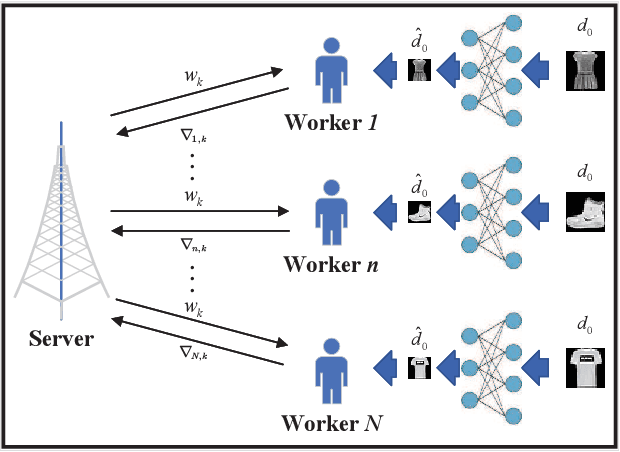
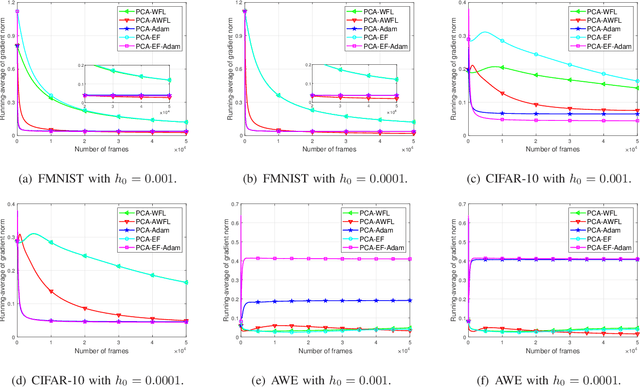
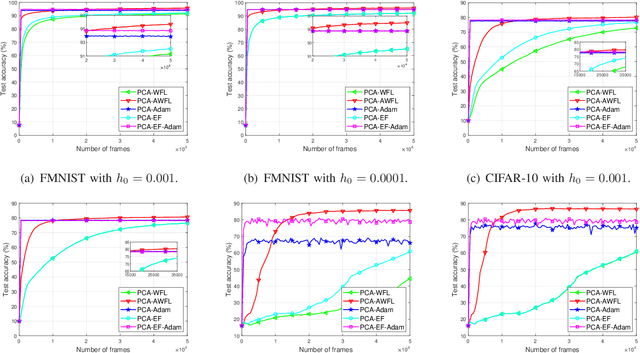
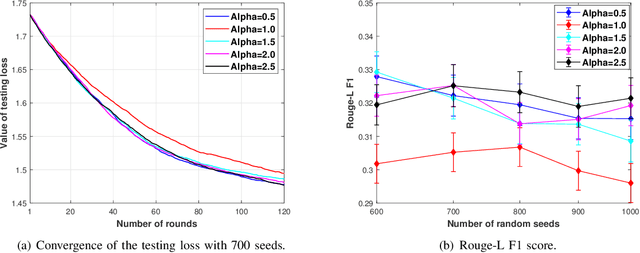
A wireless federated learning system is investigated by allowing a server and workers to exchange uncoded information via orthogonal wireless channels. Since the workers frequently upload local gradients to the server via bandwidth-limited channels, the uplink transmission from the workers to the server becomes a communication bottleneck. Therefore, a one-shot distributed principle component analysis (PCA) is leveraged to reduce the dimension of uploaded gradients such that the communication bottleneck is relieved. A PCA-based wireless federated learning (PCA-WFL) algorithm and its accelerated version (i.e., PCA-AWFL) are proposed based on the low-dimensional gradients and the Nesterov's momentum. For the non-convex loss functions, a finite-time analysis is performed to quantify the impacts of system hyper-parameters on the convergence of the PCA-WFL and PCA-AWFL algorithms. The PCA-AWFL algorithm is theoretically certified to converge faster than the PCA-WFL algorithm. Besides, the convergence rates of PCA-WFL and PCA-AWFL algorithms quantitatively reveal the linear speedup with respect to the number of workers over the vanilla gradient descent algorithm. Numerical results are used to demonstrate the improved convergence rates of the proposed PCA-WFL and PCA-AWFL algorithms over the benchmarks.
FedFair: Training Fair Models In Cross-Silo Federated Learning
Sep 13, 2021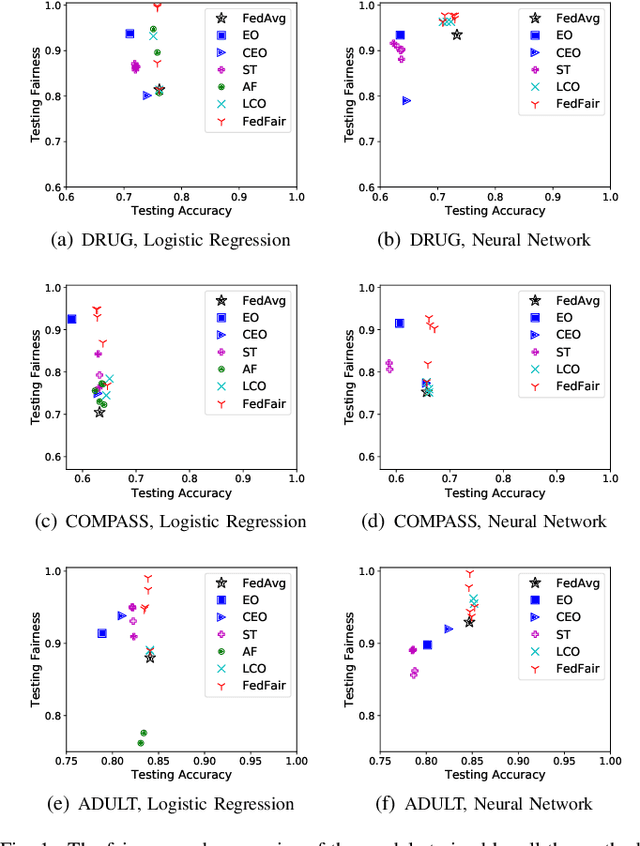
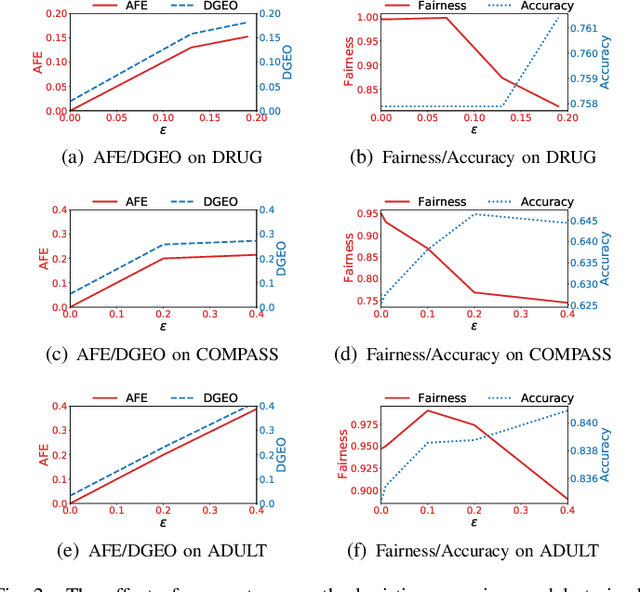
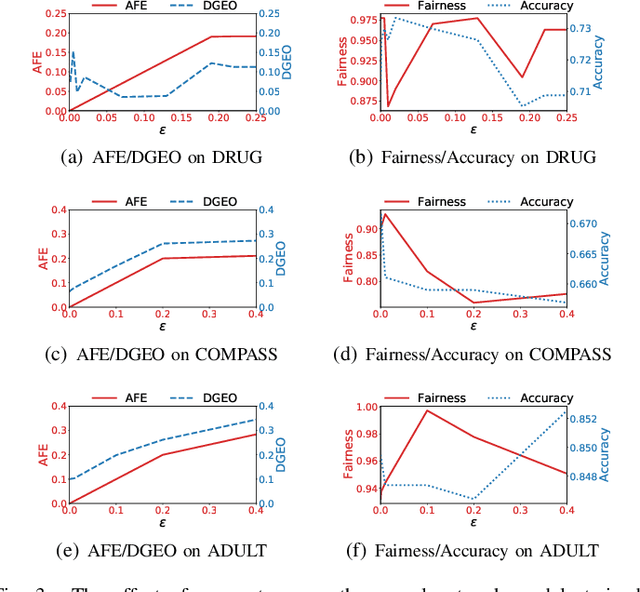
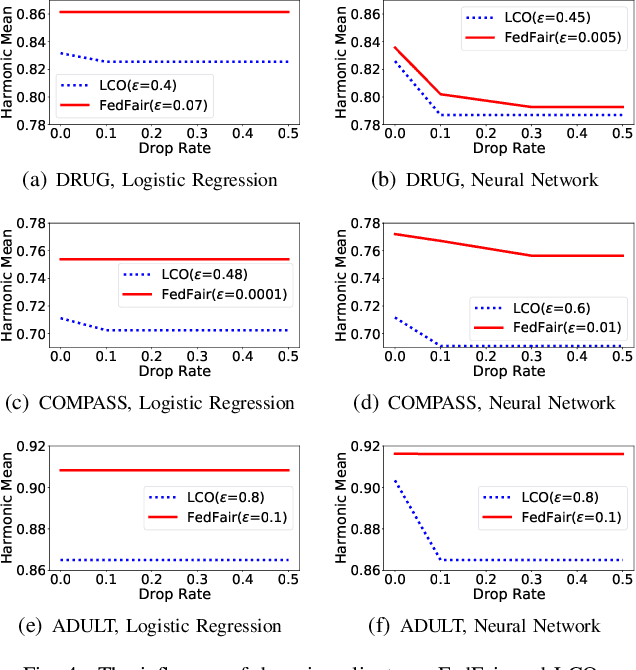
Building fair machine learning models becomes more and more important. As many powerful models are built by collaboration among multiple parties, each holding some sensitive data, it is natural to explore the feasibility of training fair models in cross-silo federated learning so that fairness, privacy and collaboration can be fully respected simultaneously. However, it is a very challenging task, since it is far from trivial to accurately estimate the fairness of a model without knowing the private data of the participating parties. In this paper, we first propose a federated estimation method to accurately estimate the fairness of a model without infringing the data privacy of any party. Then, we use the fairness estimation to formulate a novel problem of training fair models in cross-silo federated learning. We develop FedFair, a well-designed federated learning framework, which can successfully train a fair model with high performance without any data privacy infringement. Our extensive experiments on three real-world data sets demonstrate the excellent fair model training performance of our method.