 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Wireless Federated Learning via Nesterov's Momentum and Distributed Principle Component Analysis
Mar 31, 2023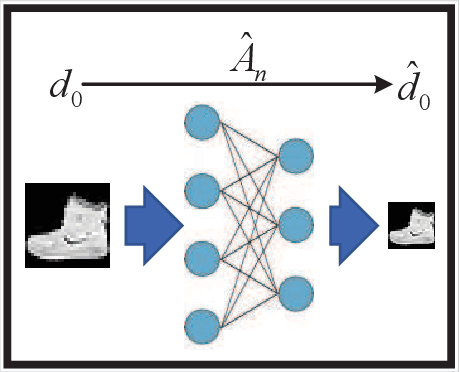
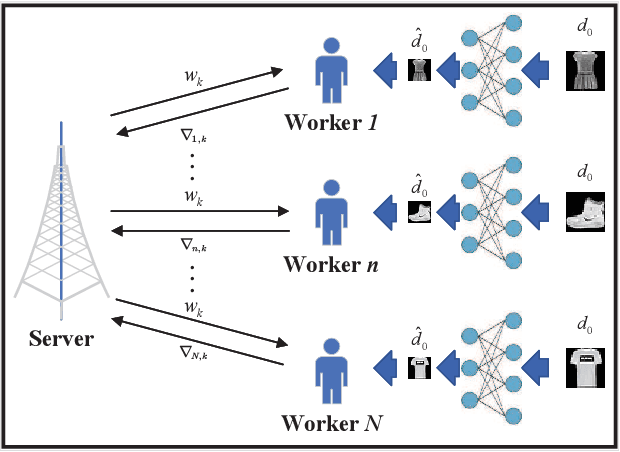
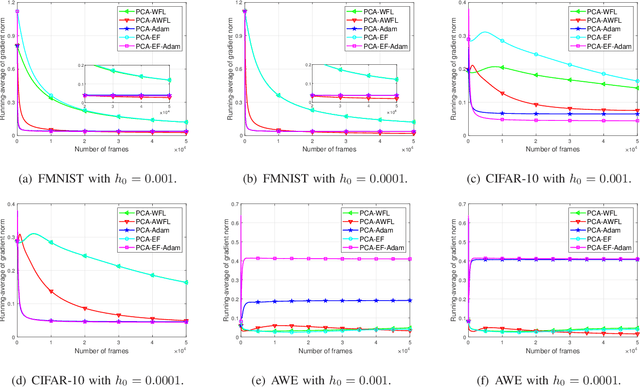
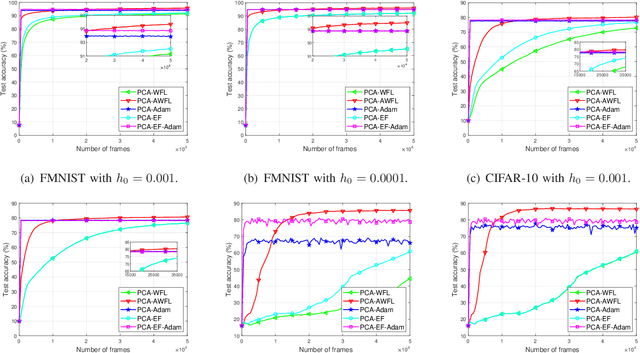
A wireless federated learning system is investigated by allowing a server and workers to exchange uncoded information via orthogonal wireless channels. Since the workers frequently upload local gradients to the server via bandwidth-limited channels, the uplink transmission from the workers to the server becomes a communication bottleneck. Therefore, a one-shot distributed principle component analysis (PCA) is leveraged to reduce the dimension of uploaded gradients such that the communication bottleneck is relieved. A PCA-based wireless federated learning (PCA-WFL) algorithm and its accelerated version (i.e., PCA-AWFL) are proposed based on the low-dimensional gradients and the Nesterov's momentum. For the non-convex loss functions, a finite-time analysis is performed to quantify the impacts of system hyper-parameters on the convergence of the PCA-WFL and PCA-AWFL algorithms. The PCA-AWFL algorithm is theoretically certified to converge faster than the PCA-WFL algorithm. Besides, the convergence rates of PCA-WFL and PCA-AWFL algorithms quantitatively reveal the linear speedup with respect to the number of workers over the vanilla gradient descent algorithm. Numerical results are used to demonstrate the improved convergence rates of the proposed PCA-WFL and PCA-AWFL algorithms over the benchmarks.
Fast-BEV: Towards Real-time On-vehicle Bird's-Eye View Perception
Jan 19, 2023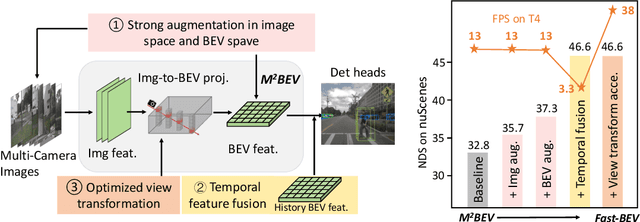
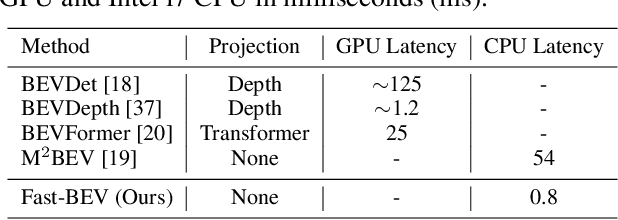
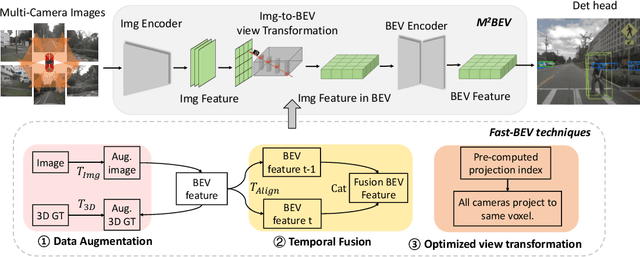
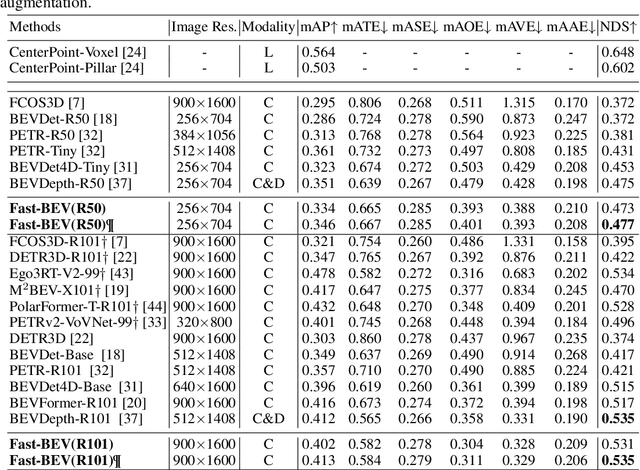
Recently, the pure camera-based Bird's-Eye-View (BEV) perception removes expensive Lidar sensors, making it a feasible solution for economical autonomous driving. However, most existing BEV solutions either suffer from modest performance or require considerable resources to execute on-vehicle inference. This paper proposes a simple yet effective framework, termed Fast-BEV, which is capable of performing real-time BEV perception on the on-vehicle chips. Towards this goal, we first empirically find that the BEV representation can be sufficiently powerful without expensive view transformation or depth representation. Starting from M2BEV baseline, we further introduce (1) a strong data augmentation strategy for both image and BEV space to avoid over-fitting (2) a multi-frame feature fusion mechanism to leverage the temporal information (3) an optimized deployment-friendly view transformation to speed up the inference. Through experiments, we show Fast-BEV model family achieves considerable accuracy and efficiency on edge. In particular, our M1 model (R18@256x704) can run over 50FPS on the Tesla T4 platform, with 47.0% NDS on the nuScenes validation set. Our largest model (R101@900x1600) establishes a new state-of-the-art 53.5% NDS on the nuScenes validation set. The code is released at: https://github.com/Sense-GVT/Fast-BEV.
* Accepted by NeurIPS2022_ML4AD on October 22, 2022
RePre: Improving Self-Supervised Vision Transformer with Reconstructive Pre-training
Jan 19, 2022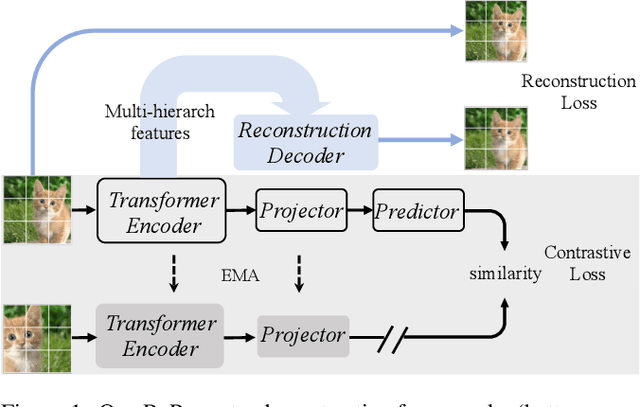
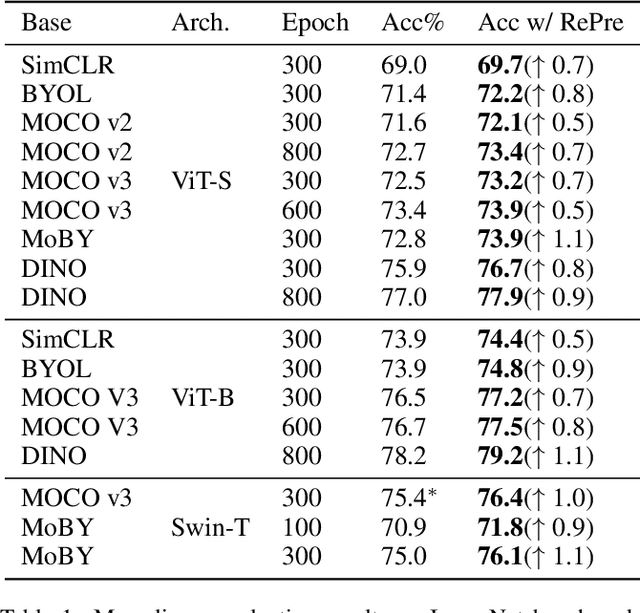
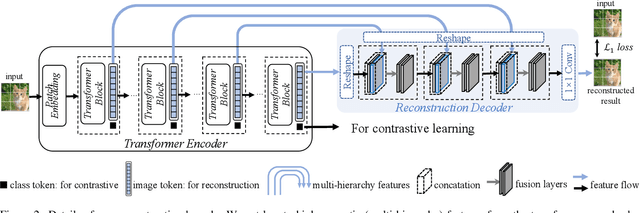
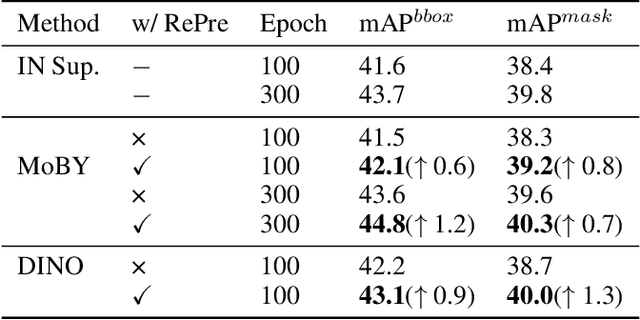
Recently, self-supervised vision transformers have attracted unprecedented attention for their impressive representation learning ability. However, the dominant method, contrastive learning, mainly relies on an instance discrimination pretext task, which learns a global understanding of the image. This paper incorporates local feature learning into self-supervised vision transformers via Reconstructive Pre-training (RePre). Our RePre extends contrastive frameworks by adding a branch for reconstructing raw image pixels in parallel with the existing contrastive objective. RePre is equipped with a lightweight convolution-based decoder that fuses the multi-hierarchy features from the transformer encoder. The multi-hierarchy features provide rich supervisions from low to high semantic information, which are crucial for our RePre. Our RePre brings decent improvements on various contrastive frameworks with different vision transformer architectures. Transfer performance in downstream tasks outperforms supervised pre-training and state-of-the-art (SOTA) self-supervised counterparts.