 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRePre: Improving Self-Supervised Vision Transformer with Reconstructive Pre-training
Paper and Code
Jan 19, 2022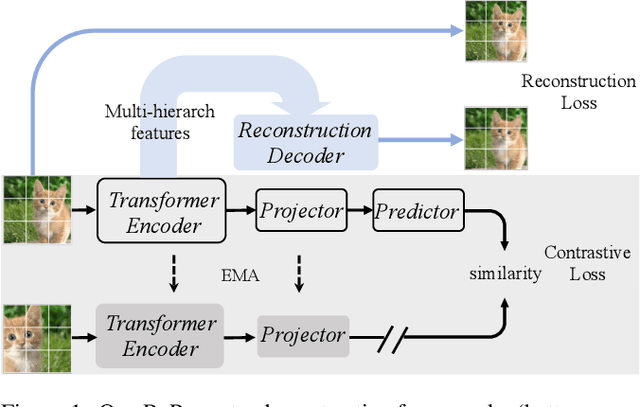
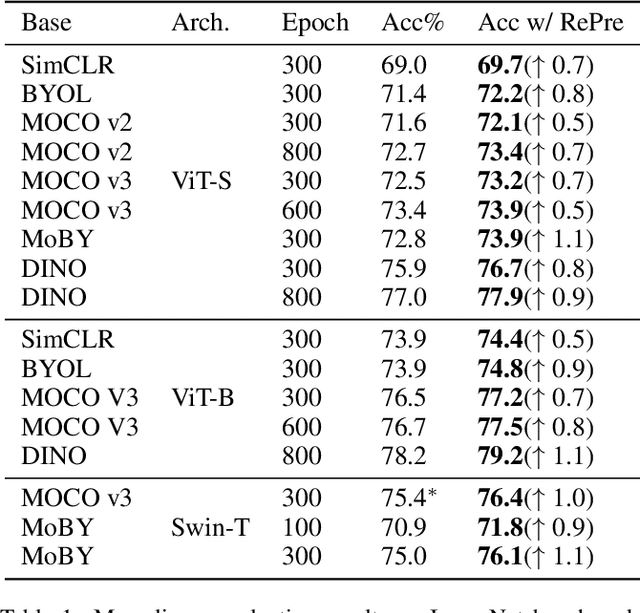
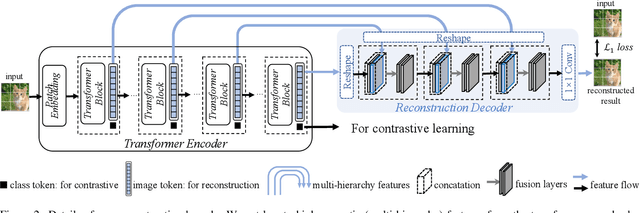
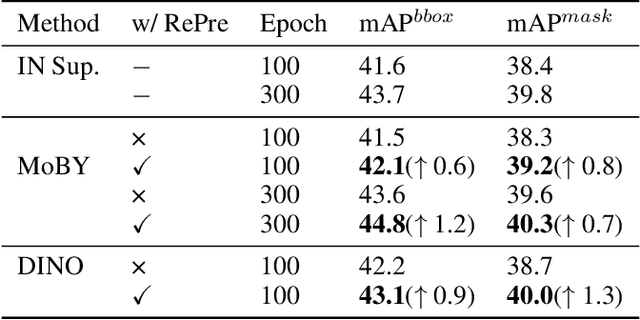
Recently, self-supervised vision transformers have attracted unprecedented attention for their impressive representation learning ability. However, the dominant method, contrastive learning, mainly relies on an instance discrimination pretext task, which learns a global understanding of the image. This paper incorporates local feature learning into self-supervised vision transformers via Reconstructive Pre-training (RePre). Our RePre extends contrastive frameworks by adding a branch for reconstructing raw image pixels in parallel with the existing contrastive objective. RePre is equipped with a lightweight convolution-based decoder that fuses the multi-hierarchy features from the transformer encoder. The multi-hierarchy features provide rich supervisions from low to high semantic information, which are crucial for our RePre. Our RePre brings decent improvements on various contrastive frameworks with different vision transformer architectures. Transfer performance in downstream tasks outperforms supervised pre-training and state-of-the-art (SOTA) self-supervised counterparts.