 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Semantic Communication: Architectures, Technologies, and Applications
Dec 11, 2024



This paper delves into the applications of generative artificial intelligence (GAI) in semantic communication (SemCom) and presents a thorough study. Three popular SemCom systems enabled by classical GAI models are first introduced, including variational autoencoders, generative adversarial networks, and diffusion models. For each system, the fundamental concept of the GAI model, the corresponding SemCom architecture, and the associated literature review of recent efforts are elucidated. Then, a novel generative SemCom system is proposed by incorporating the cutting-edge GAI technology-large language models (LLMs). This system features two LLM-based AI agents at both the transmitter and receiver, serving as "brains" to enable powerful information understanding and content regeneration capabilities, respectively. This innovative design allows the receiver to directly generate the desired content, instead of recovering the bit stream, based on the coded semantic information conveyed by the transmitter. Therefore, it shifts the communication mindset from "information recovery" to "information regeneration" and thus ushers in a new era of generative SemCom. A case study on point-to-point video retrieval is presented to demonstrate the superiority of the proposed generative SemCom system, showcasing a 99.98% reduction in communication overhead and a 53% improvement in retrieval accuracy compared to the traditional communication system. Furthermore, four typical application scenarios for generative SemCom are delineated, followed by a discussion of three open issues warranting future investigation. In a nutshell, this paper provides a holistic set of guidelines for applying GAI in SemCom, paving the way for the efficient implementation of generative SemCom in future wireless networks.
Generative Semantic Communication for Joint Image Transmission and Segmentation
Nov 27, 2024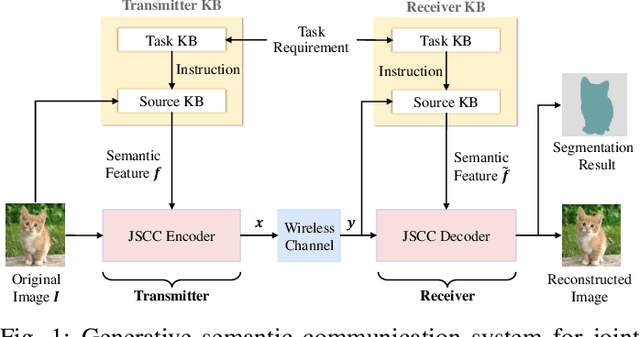
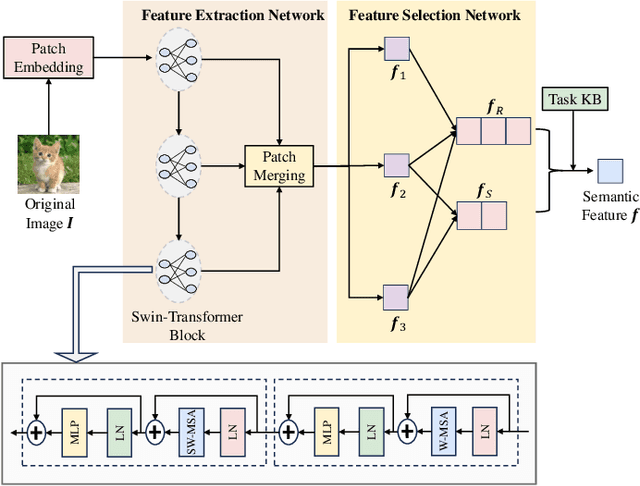
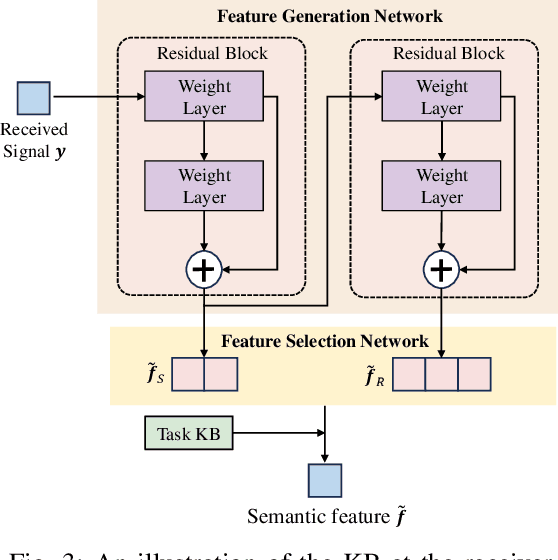
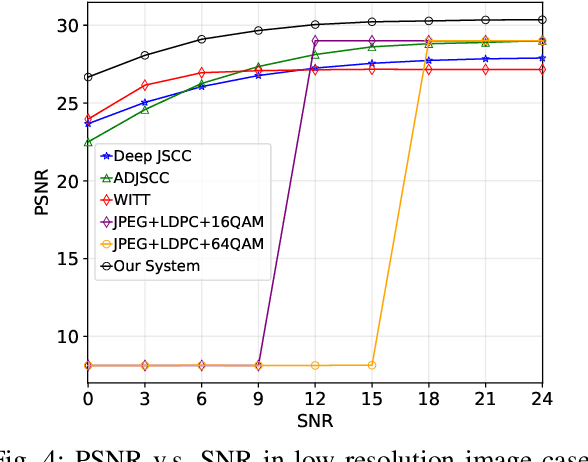
Semantic communication has emerged as a promising technology for enhancing communication efficiency. However, most existing research emphasizes single-task reconstruction, neglecting model adaptability and generalization across multi-task systems. In this paper, we propose a novel generative semantic communication system that supports both image reconstruction and segmentation tasks. Our approach builds upon semantic knowledge bases (KBs) at both the transmitter and receiver, with each semantic KB comprising a source KB and a task KB. The source KB at the transmitter leverages a hierarchical Swin-Transformer, a generative AI scheme, to extract multi-level features from the input image. Concurrently, the counterpart source KB at the receiver utilizes hierarchical residual blocks to generate task-specific knowledge. Furthermore, the two task KBs adopt a semantic similarity model to map different task requirements into pre-defined task instructions, thereby facilitating the feature selection of the source KBs. Additionally, we develop a unified residual block-based joint source and channel (JSCC) encoder and two task-specific JSCC decoders to achieve the two image tasks. In particular, a generative diffusion model is adopted to construct the JSCC decoder for the image reconstruction task. Experimental results demonstrate that our multi-task generative semantic communication system outperforms previous single-task communication systems in terms of peak signal-to-noise ratio and segmentation accuracy.
MVHumanNet: A Large-scale Dataset of Multi-view Daily Dressing Human Captures
Dec 05, 2023
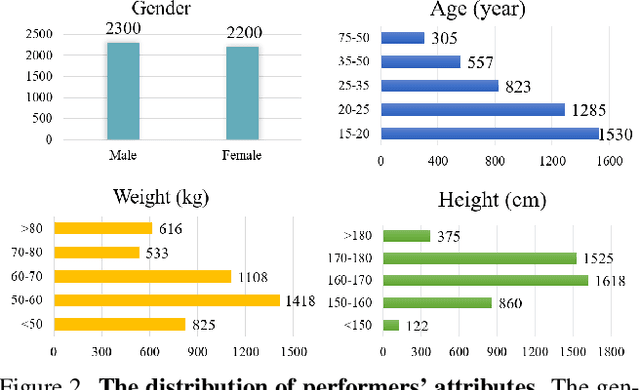
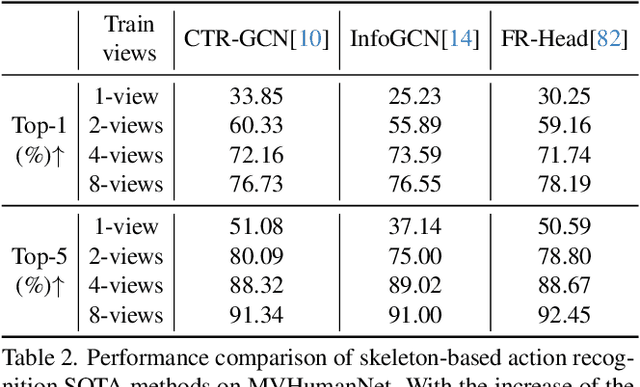

In this era, the success of large language models and text-to-image models can be attributed to the driving force of large-scale datasets. However, in the realm of 3D vision, while remarkable progress has been made with models trained on large-scale synthetic and real-captured object data like Objaverse and MVImgNet, a similar level of progress has not been observed in the domain of human-centric tasks partially due to the lack of a large-scale human dataset. Existing datasets of high-fidelity 3D human capture continue to be mid-sized due to the significant challenges in acquiring large-scale high-quality 3D human data. To bridge this gap, we present MVHumanNet, a dataset that comprises multi-view human action sequences of 4,500 human identities. The primary focus of our work is on collecting human data that features a large number of diverse identities and everyday clothing using a multi-view human capture system, which facilitates easily scalable data collection. Our dataset contains 9,000 daily outfits, 60,000 motion sequences and 645 million frames with extensive annotations, including human masks, camera parameters, 2D and 3D keypoints, SMPL/SMPLX parameters, and corresponding textual descriptions. To explore the potential of MVHumanNet in various 2D and 3D visual tasks, we conducted pilot studies on view-consistent action recognition, human NeRF reconstruction, text-driven view-unconstrained human image generation, as well as 2D view-unconstrained human image and 3D avatar generation. Extensive experiments demonstrate the performance improvements and effective applications enabled by the scale provided by MVHumanNet. As the current largest-scale 3D human dataset, we hope that the release of MVHumanNet data with annotations will foster further innovations in the domain of 3D human-centric tasks at scale.