 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReImagine: Rethinking Controllable High-Quality Human Video Generation via Image-First Synthesis
Apr 21, 2026Human video generation remains challenging due to the difficulty of jointly modeling human appearance, motion, and camera viewpoint under limited multi-view data. Existing methods often address these factors separately, resulting in limited controllability or reduced visual quality. We revisit this problem from an image-first perspective, where high-quality human appearance is learned via image generation and used as a prior for video synthesis, decoupling appearance modeling from temporal consistency. We propose a pose- and viewpoint-controllable pipeline that combines a pretrained image backbone with SMPL-X-based motion guidance, together with a training-free temporal refinement stage based on a pretrained video diffusion model. Our method produces high-quality, temporally consistent videos under diverse poses and viewpoints. We also release a canonical human dataset and an auxiliary model for compositional human image synthesis. Code and data are publicly available at https://github.com/Taited/ReImagine.
ForeHOI: Feed-forward 3D Object Reconstruction from Daily Hand-Object Interaction Videos
Feb 05, 2026The ubiquity of monocular videos capturing daily hand-object interactions presents a valuable resource for embodied intelligence. While 3D hand reconstruction from in-the-wild videos has seen significant progress, reconstructing the involved objects remains challenging due to severe occlusions and the complex, coupled motion of the camera, hands, and object. In this paper, we introduce ForeHOI, a novel feed-forward model that directly reconstructs 3D object geometry from monocular hand-object interaction videos within one minute of inference time, eliminating the need for any pre-processing steps. Our key insight is that, the joint prediction of 2D mask inpainting and 3D shape completion in a feed-forward framework can effectively address the problem of severe occlusion in monocular hand-held object videos, thereby achieving results that outperform the performance of optimization-based methods. The information exchanges between the 2D and 3D shape completion boosts the overall reconstruction quality, enabling the framework to effectively handle severe hand-object occlusion. Furthermore, to support the training of our model, we contribute the first large-scale, high-fidelity synthetic dataset of hand-object interactions with comprehensive annotations. Extensive experiments demonstrate that ForeHOI achieves state-of-the-art performance in object reconstruction, significantly outperforming previous methods with around a 100x speedup. Code and data are available at: https://github.com/Tao-11-chen/ForeHOI.
MV-Performer: Taming Video Diffusion Model for Faithful and Synchronized Multi-view Performer Synthesis
Oct 08, 2025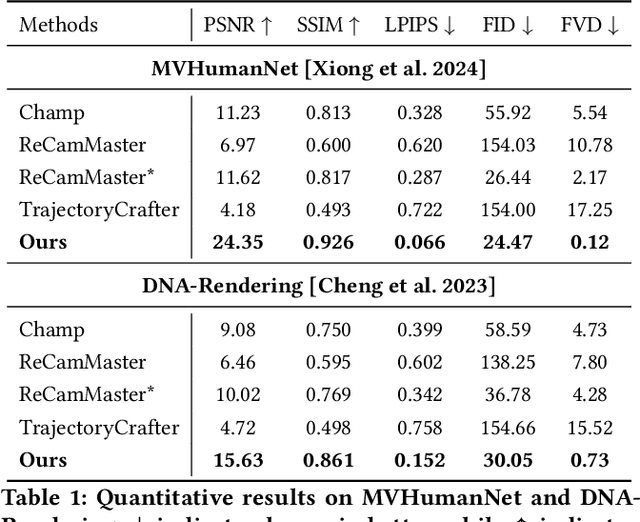

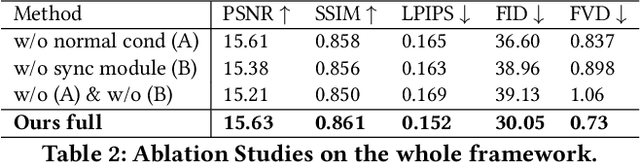
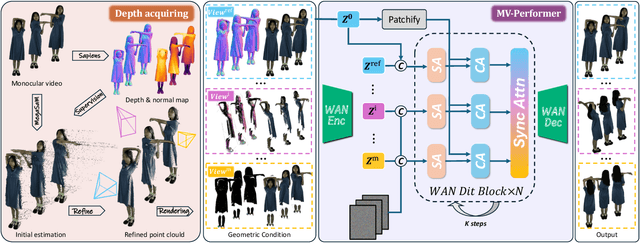
Recent breakthroughs in video generation, powered by large-scale datasets and diffusion techniques, have shown that video diffusion models can function as implicit 4D novel view synthesizers. Nevertheless, current methods primarily concentrate on redirecting camera trajectory within the front view while struggling to generate 360-degree viewpoint changes. In this paper, we focus on human-centric subdomain and present MV-Performer, an innovative framework for creating synchronized novel view videos from monocular full-body captures. To achieve a 360-degree synthesis, we extensively leverage the MVHumanNet dataset and incorporate an informative condition signal. Specifically, we use the camera-dependent normal maps rendered from oriented partial point clouds, which effectively alleviate the ambiguity between seen and unseen observations. To maintain synchronization in the generated videos, we propose a multi-view human-centric video diffusion model that fuses information from the reference video, partial rendering, and different viewpoints. Additionally, we provide a robust inference procedure for in-the-wild video cases, which greatly mitigates the artifacts induced by imperfect monocular depth estimation. Extensive experiments on three datasets demonstrate our MV-Performer's state-of-the-art effectiveness and robustness, setting a strong model for human-centric 4D novel view synthesis.
ADGaussian: Generalizable Gaussian Splatting for Autonomous Driving with Multi-modal Inputs
Apr 01, 2025We present a novel approach, termed ADGaussian, for generalizable street scene reconstruction. The proposed method enables high-quality rendering from single-view input. Unlike prior Gaussian Splatting methods that primarily focus on geometry refinement, we emphasize the importance of joint optimization of image and depth features for accurate Gaussian prediction. To this end, we first incorporate sparse LiDAR depth as an additional input modality, formulating the Gaussian prediction process as a joint learning framework of visual information and geometric clue. Furthermore, we propose a multi-modal feature matching strategy coupled with a multi-scale Gaussian decoding model to enhance the joint refinement of multi-modal features, thereby enabling efficient multi-modal Gaussian learning. Extensive experiments on two large-scale autonomous driving datasets, Waymo and KITTI, demonstrate that our ADGaussian achieves state-of-the-art performance and exhibits superior zero-shot generalization capabilities in novel-view shifting.
Exploring Disentangled and Controllable Human Image Synthesis: From End-to-End to Stage-by-Stage
Mar 25, 2025



Achieving fine-grained controllability in human image synthesis is a long-standing challenge in computer vision. Existing methods primarily focus on either facial synthesis or near-frontal body generation, with limited ability to simultaneously control key factors such as viewpoint, pose, clothing, and identity in a disentangled manner. In this paper, we introduce a new disentangled and controllable human synthesis task, which explicitly separates and manipulates these four factors within a unified framework. We first develop an end-to-end generative model trained on MVHumanNet for factor disentanglement. However, the domain gap between MVHumanNet and in-the-wild data produce unsatisfacotry results, motivating the exploration of virtual try-on (VTON) dataset as a potential solution. Through experiments, we observe that simply incorporating the VTON dataset as additional data to train the end-to-end model degrades performance, primarily due to the inconsistency in data forms between the two datasets, which disrupts the disentanglement process. To better leverage both datasets, we propose a stage-by-stage framework that decomposes human image generation into three sequential steps: clothed A-pose generation, back-view synthesis, and pose and view control. This structured pipeline enables better dataset utilization at different stages, significantly improving controllability and generalization, especially for in-the-wild scenarios. Extensive experiments demonstrate that our stage-by-stage approach outperforms end-to-end models in both visual fidelity and disentanglement quality, offering a scalable solution for real-world tasks. Additional demos are available on the project page: https://taited.github.io/discohuman-project/.
GarVerseLOD: High-Fidelity 3D Garment Reconstruction from a Single In-the-Wild Image using a Dataset with Levels of Details
Nov 05, 2024



Neural implicit functions have brought impressive advances to the state-of-the-art of clothed human digitization from multiple or even single images. However, despite the progress, current arts still have difficulty generalizing to unseen images with complex cloth deformation and body poses. In this work, we present GarVerseLOD, a new dataset and framework that paves the way to achieving unprecedented robustness in high-fidelity 3D garment reconstruction from a single unconstrained image. Inspired by the recent success of large generative models, we believe that one key to addressing the generalization challenge lies in the quantity and quality of 3D garment data. Towards this end, GarVerseLOD collects 6,000 high-quality cloth models with fine-grained geometry details manually created by professional artists. In addition to the scale of training data, we observe that having disentangled granularities of geometry can play an important role in boosting the generalization capability and inference accuracy of the learned model. We hence craft GarVerseLOD as a hierarchical dataset with levels of details (LOD), spanning from detail-free stylized shape to pose-blended garment with pixel-aligned details. This allows us to make this highly under-constrained problem tractable by factorizing the inference into easier tasks, each narrowed down with smaller searching space. To ensure GarVerseLOD can generalize well to in-the-wild images, we propose a novel labeling paradigm based on conditional diffusion models to generate extensive paired images for each garment model with high photorealism. We evaluate our method on a massive amount of in-the-wild images. Experimental results demonstrate that GarVerseLOD can generate standalone garment pieces with significantly better quality than prior approaches. Project page: https://garverselod.github.io/
MVHumanNet: A Large-scale Dataset of Multi-view Daily Dressing Human Captures
Dec 05, 2023
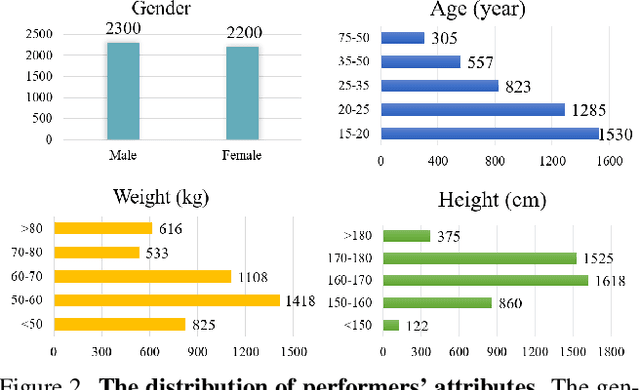
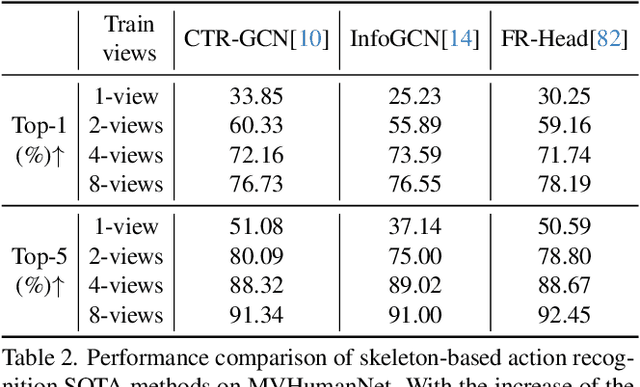

In this era, the success of large language models and text-to-image models can be attributed to the driving force of large-scale datasets. However, in the realm of 3D vision, while remarkable progress has been made with models trained on large-scale synthetic and real-captured object data like Objaverse and MVImgNet, a similar level of progress has not been observed in the domain of human-centric tasks partially due to the lack of a large-scale human dataset. Existing datasets of high-fidelity 3D human capture continue to be mid-sized due to the significant challenges in acquiring large-scale high-quality 3D human data. To bridge this gap, we present MVHumanNet, a dataset that comprises multi-view human action sequences of 4,500 human identities. The primary focus of our work is on collecting human data that features a large number of diverse identities and everyday clothing using a multi-view human capture system, which facilitates easily scalable data collection. Our dataset contains 9,000 daily outfits, 60,000 motion sequences and 645 million frames with extensive annotations, including human masks, camera parameters, 2D and 3D keypoints, SMPL/SMPLX parameters, and corresponding textual descriptions. To explore the potential of MVHumanNet in various 2D and 3D visual tasks, we conducted pilot studies on view-consistent action recognition, human NeRF reconstruction, text-driven view-unconstrained human image generation, as well as 2D view-unconstrained human image and 3D avatar generation. Extensive experiments demonstrate the performance improvements and effective applications enabled by the scale provided by MVHumanNet. As the current largest-scale 3D human dataset, we hope that the release of MVHumanNet data with annotations will foster further innovations in the domain of 3D human-centric tasks at scale.
EMS: 3D Eyebrow Modeling from Single-view Images
Sep 22, 2023Eyebrows play a critical role in facial expression and appearance. Although the 3D digitization of faces is well explored, less attention has been drawn to 3D eyebrow modeling. In this work, we propose EMS, the first learning-based framework for single-view 3D eyebrow reconstruction. Following the methods of scalp hair reconstruction, we also represent the eyebrow as a set of fiber curves and convert the reconstruction to fibers growing problem. Three modules are then carefully designed: RootFinder firstly localizes the fiber root positions which indicates where to grow; OriPredictor predicts an orientation field in the 3D space to guide the growing of fibers; FiberEnder is designed to determine when to stop the growth of each fiber. Our OriPredictor is directly borrowing the method used in hair reconstruction. Considering the differences between hair and eyebrows, both RootFinder and FiberEnder are newly proposed. Specifically, to cope with the challenge that the root location is severely occluded, we formulate root localization as a density map estimation task. Given the predicted density map, a density-based clustering method is further used for finding the roots. For each fiber, the growth starts from the root point and moves step by step until the ending, where each step is defined as an oriented line with a constant length according to the predicted orientation field. To determine when to end, a pixel-aligned RNN architecture is designed to form a binary classifier, which outputs stop or not for each growing step. To support the training of all proposed networks, we build the first 3D synthetic eyebrow dataset that contains 400 high-quality eyebrow models manually created by artists. Extensive experiments have demonstrated the effectiveness of the proposed EMS pipeline on a variety of different eyebrow styles and lengths, ranging from short and sparse to long bushy eyebrows.
PVSeRF: Joint Pixel-, Voxel- and Surface-Aligned Radiance Field for Single-Image Novel View Synthesis
Feb 10, 2022
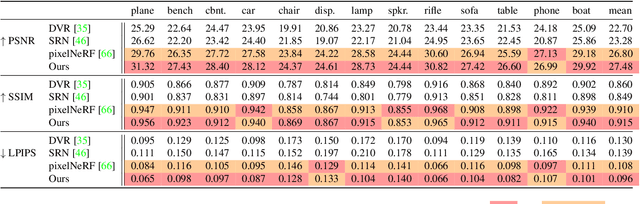
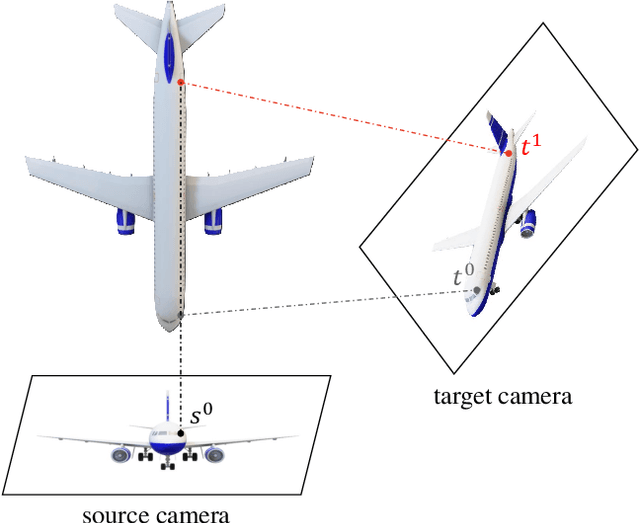
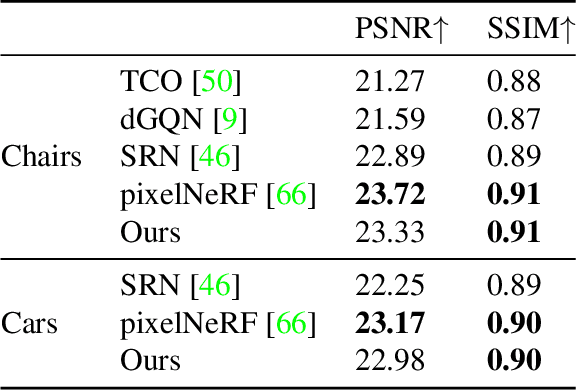
We present PVSeRF, a learning framework that reconstructs neural radiance fields from single-view RGB images, for novel view synthesis. Previous solutions, such as pixelNeRF, rely only on pixel-aligned features and suffer from feature ambiguity issues. As a result, they struggle with the disentanglement of geometry and appearance, leading to implausible geometries and blurry results. To address this challenge, we propose to incorporate explicit geometry reasoning and combine it with pixel-aligned features for radiance field prediction. Specifically, in addition to pixel-aligned features, we further constrain the radiance field learning to be conditioned on i) voxel-aligned features learned from a coarse volumetric grid and ii) fine surface-aligned features extracted from a regressed point cloud. We show that the introduction of such geometry-aware features helps to achieve a better disentanglement between appearance and geometry, i.e. recovering more accurate geometries and synthesizing higher quality images of novel views. Extensive experiments against state-of-the-art methods on ShapeNet benchmarks demonstrate the superiority of our approach for single-image novel view synthesis.
Fully Attentional Network for Semantic Segmentation
Dec 08, 2021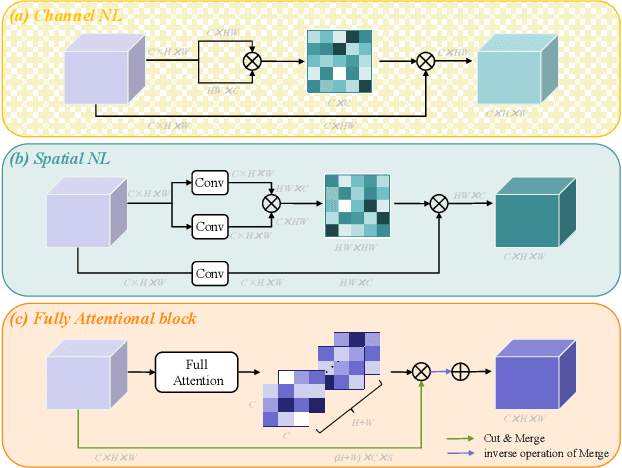



Recent non-local self-attention methods have proven to be effective in capturing long-range dependencies for semantic segmentation. These methods usually form a similarity map of RC*C (by compressing spatial dimensions) or RHW*HW (by compressing channels) to describe the feature relations along either channel or spatial dimensions, where C is the number of channels, H and W are the spatial dimensions of the input feature map. However, such practices tend to condense feature dependencies along the other dimensions,hence causing attention missing, which might lead to inferior results for small/thin categories or inconsistent segmentation inside large objects. To address this problem, we propose anew approach, namely Fully Attentional Network (FLANet),to encode both spatial and channel attentions in a single similarity map while maintaining high computational efficiency. Specifically, for each channel map, our FLANet can harvest feature responses from all other channel maps, and the associated spatial positions as well, through a novel fully attentional module. Our new method has achieved state-of-the-art performance on three challenging semantic segmentation datasets,i.e., 83.6%, 46.99%, and 88.5% on the Cityscapes test set,the ADE20K validation set, and the PASCAL VOC test set,respectively.