 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV-Performer: Taming Video Diffusion Model for Faithful and Synchronized Multi-view Performer Synthesis
Oct 08, 2025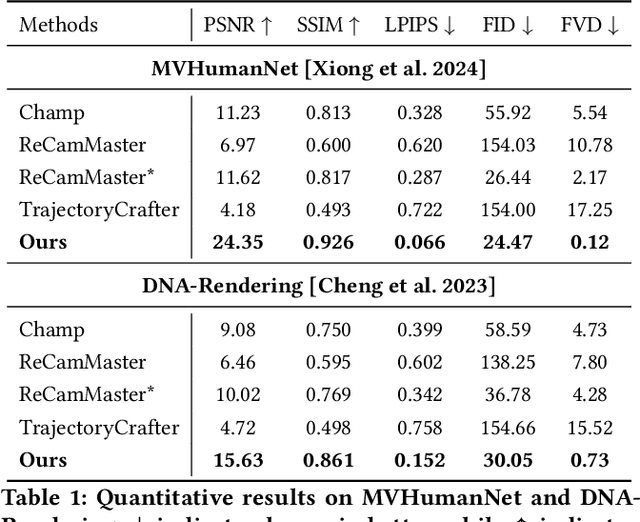

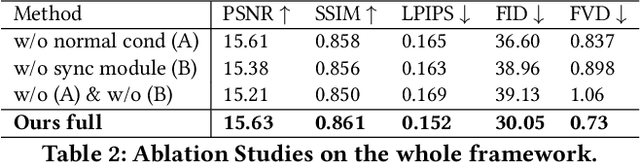
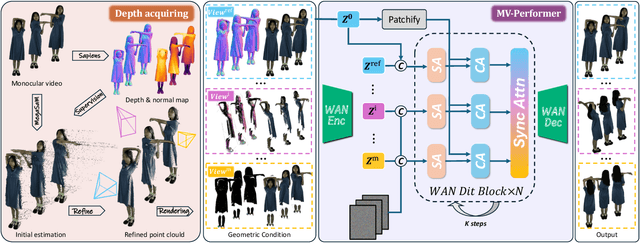
Recent breakthroughs in video generation, powered by large-scale datasets and diffusion techniques, have shown that video diffusion models can function as implicit 4D novel view synthesizers. Nevertheless, current methods primarily concentrate on redirecting camera trajectory within the front view while struggling to generate 360-degree viewpoint changes. In this paper, we focus on human-centric subdomain and present MV-Performer, an innovative framework for creating synchronized novel view videos from monocular full-body captures. To achieve a 360-degree synthesis, we extensively leverage the MVHumanNet dataset and incorporate an informative condition signal. Specifically, we use the camera-dependent normal maps rendered from oriented partial point clouds, which effectively alleviate the ambiguity between seen and unseen observations. To maintain synchronization in the generated videos, we propose a multi-view human-centric video diffusion model that fuses information from the reference video, partial rendering, and different viewpoints. Additionally, we provide a robust inference procedure for in-the-wild video cases, which greatly mitigates the artifacts induced by imperfect monocular depth estimation. Extensive experiments on three datasets demonstrate our MV-Performer's state-of-the-art effectiveness and robustness, setting a strong model for human-centric 4D novel view synthesis.
Exploring Disentangled and Controllable Human Image Synthesis: From End-to-End to Stage-by-Stage
Mar 25, 2025



Achieving fine-grained controllability in human image synthesis is a long-standing challenge in computer vision. Existing methods primarily focus on either facial synthesis or near-frontal body generation, with limited ability to simultaneously control key factors such as viewpoint, pose, clothing, and identity in a disentangled manner. In this paper, we introduce a new disentangled and controllable human synthesis task, which explicitly separates and manipulates these four factors within a unified framework. We first develop an end-to-end generative model trained on MVHumanNet for factor disentanglement. However, the domain gap between MVHumanNet and in-the-wild data produce unsatisfacotry results, motivating the exploration of virtual try-on (VTON) dataset as a potential solution. Through experiments, we observe that simply incorporating the VTON dataset as additional data to train the end-to-end model degrades performance, primarily due to the inconsistency in data forms between the two datasets, which disrupts the disentanglement process. To better leverage both datasets, we propose a stage-by-stage framework that decomposes human image generation into three sequential steps: clothed A-pose generation, back-view synthesis, and pose and view control. This structured pipeline enables better dataset utilization at different stages, significantly improving controllability and generalization, especially for in-the-wild scenarios. Extensive experiments demonstrate that our stage-by-stage approach outperforms end-to-end models in both visual fidelity and disentanglement quality, offering a scalable solution for real-world tasks. Additional demos are available on the project page: https://taited.github.io/discohuman-project/.
SGDiff: A Style Guided Diffusion Model for Fashion Synthesis
Aug 15, 2023



This paper reports on the development of \textbf{a novel style guided diffusion model (SGDiff)} which overcomes certain weaknesses inherent in existing models for image synthesis. The proposed SGDiff combines image modality with a pretrained text-to-image diffusion model to facilitate creative fashion image synthesis. It addresses the limitations of text-to-image diffusion models by incorporating supplementary style guidance, substantially reducing training costs, and overcoming the difficulties of controlling synthesized styles with text-only inputs. This paper also introduces a new dataset -- SG-Fashion, specifically designed for fashion image synthesis applications, offering high-resolution images and an extensive range of garment categories. By means of comprehensive ablation study, we examine the application of classifier-free guidance to a variety of conditions and validate the effectiveness of the proposed model for generating fashion images of the desired categories, product attributes, and styles. The contributions of this paper include a novel classifier-free guidance method for multi-modal feature fusion, a comprehensive dataset for fashion image synthesis application, a thorough investigation on conditioned text-to-image synthesis, and valuable insights for future research in the text-to-image synthesis domain. The code and dataset are available at: \url{https://github.com/taited/SGDiff}.
Automatic Segmentation of Organs-at-Risk from Head-and-Neck CT using Separable Convolutional Neural Network with Hard-Region-Weighted Loss
Feb 03, 2021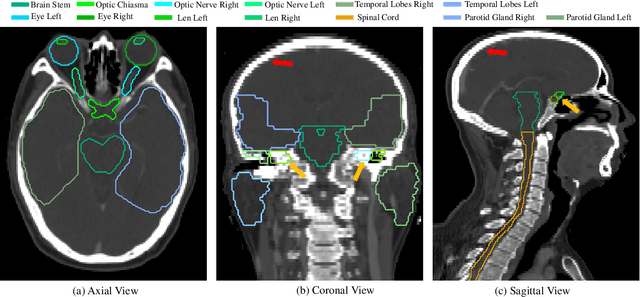
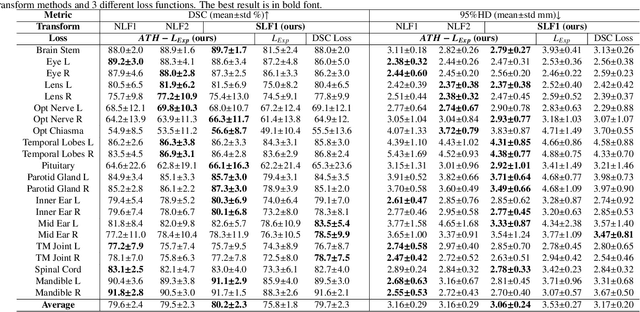
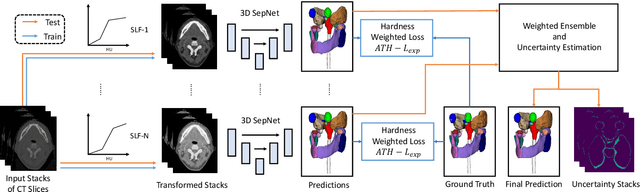
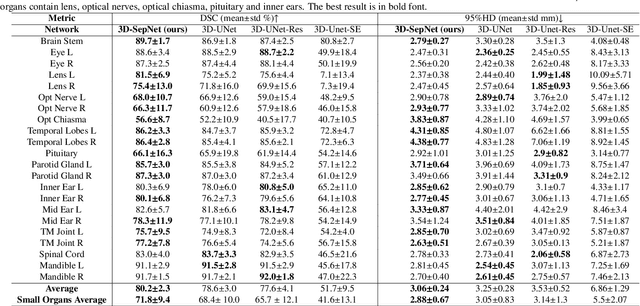
Nasopharyngeal Carcinoma (NPC) is a leading form of Head-and-Neck (HAN) cancer in the Arctic, China, Southeast Asia, and the Middle East/North Africa. Accurate segmentation of Organs-at-Risk (OAR) from Computed Tomography (CT) images with uncertainty information is critical for effective planning of radiation therapy for NPC treatment. Despite the stateof-the-art performance achieved by Convolutional Neural Networks (CNNs) for automatic segmentation of OARs, existing methods do not provide uncertainty estimation of the segmentation results for treatment planning, and their accuracy is still limited by several factors, including the low contrast of soft tissues in CT, highly imbalanced sizes of OARs and large inter-slice spacing. To address these problems, we propose a novel framework for accurate OAR segmentation with reliable uncertainty estimation. First, we propose a Segmental Linear Function (SLF) to transform the intensity of CT images to make multiple organs more distinguishable than existing methods based on a simple window width/level that often gives a better visibility of one organ while hiding the others. Second, to deal with the large inter-slice spacing, we introduce a novel 2.5D network (named as 3D-SepNet) specially designed for dealing with clinic HAN CT scans with anisotropic spacing. Thirdly, existing hardness-aware loss function often deal with class-level hardness, but our proposed attention to hard voxels (ATH) uses a voxel-level hardness strategy, which is more suitable to dealing with some hard regions despite that its corresponding class may be easy. Our code is now available at https://github.com/HiLab-git/SepNet.
Automatic Segmentation of Gross Target Volume of Nasopharynx Cancer using Ensemble of Multiscale Deep Neural Networks with Spatial Attention
Jan 27, 2021

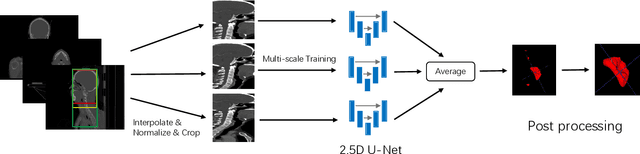
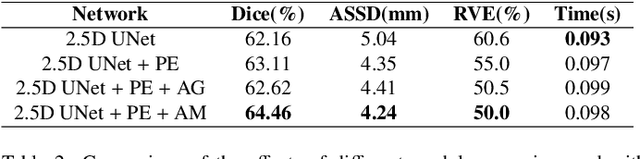
Radiotherapy is the main treatment modality for nasopharynx cancer. Delineation of Gross Target Volume (GTV) from medical images such as CT and MRI images is a prerequisite for radiotherapy. As manual delineation is time-consuming and laborious, automatic segmentation of GTV has a potential to improve this process. Currently, most of the deep learning-based automatic delineation methods of GTV are mainly performed on medical images like CT images. However, it is challenged by the low contrast between the pathology regions and surrounding soft tissues, small target region, and anisotropic resolution of clinical CT images. To deal with these problems, we propose a 2.5D Convolutional Neural Network (CNN) to handle the difference of inplane and through-plane resolution. Furthermore, we propose a spatial attention module to enable the network to focus on small target, and use channel attention to further improve the segmentation performance. Moreover, we use multi-scale sampling method for training so that the networks can learn features at different scales, which are combined with a multi-model ensemble method to improve the robustness of segmentation results. We also estimate the uncertainty of segmentation results based on our model ensemble, which is of great importance for indicating the reliability of automatic segmentation results for radiotherapy planning.