 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTK-Mamba: Marrying KAN with Mamba for Text-Driven 3D Medical Image Segmentation
May 24, 2025



3D medical image segmentation is vital for clinical diagnosis and treatment but is challenged by high-dimensional data and complex spatial dependencies. Traditional single-modality networks, such as CNNs and Transformers, are often limited by computational inefficiency and constrained contextual modeling in 3D settings. We introduce a novel multimodal framework that leverages Mamba and Kolmogorov-Arnold Networks (KAN) as an efficient backbone for long-sequence modeling. Our approach features three key innovations: First, an EGSC (Enhanced Gated Spatial Convolution) module captures spatial information when unfolding 3D images into 1D sequences. Second, we extend Group-Rational KAN (GR-KAN), a Kolmogorov-Arnold Networks variant with rational basis functions, into 3D-Group-Rational KAN (3D-GR-KAN) for 3D medical imaging - its first application in this domain - enabling superior feature representation tailored to volumetric data. Third, a dual-branch text-driven strategy leverages CLIP's text embeddings: one branch swaps one-hot labels for semantic vectors to preserve inter-organ semantic relationships, while the other aligns images with detailed organ descriptions to enhance semantic alignment. Experiments on the Medical Segmentation Decathlon (MSD) and KiTS23 datasets show our method achieving state-of-the-art performance, surpassing existing approaches in accuracy and efficiency. This work highlights the power of combining advanced sequence modeling, extended network architectures, and vision-language synergy to push forward 3D medical image segmentation, delivering a scalable solution for clinical use. The source code is openly available at https://github.com/yhy-whu/TK-Mamba.
Interactive Segmentation and Report Generation for CT Images
Mar 05, 2025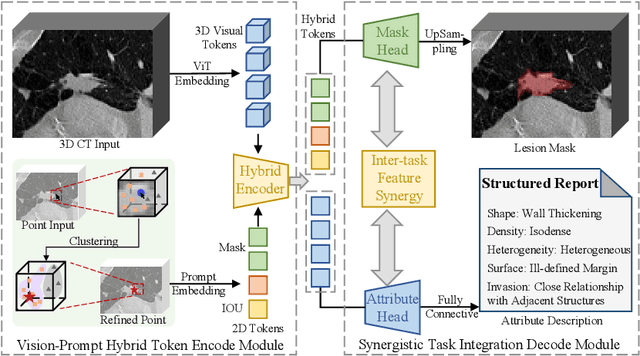
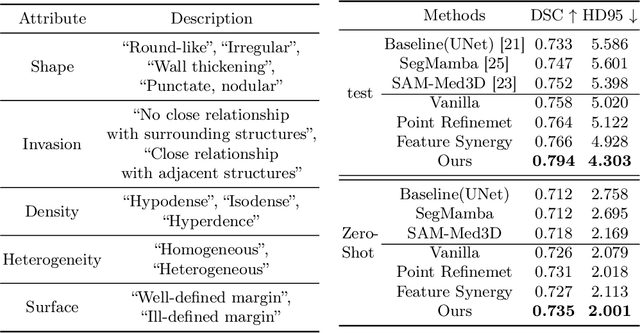

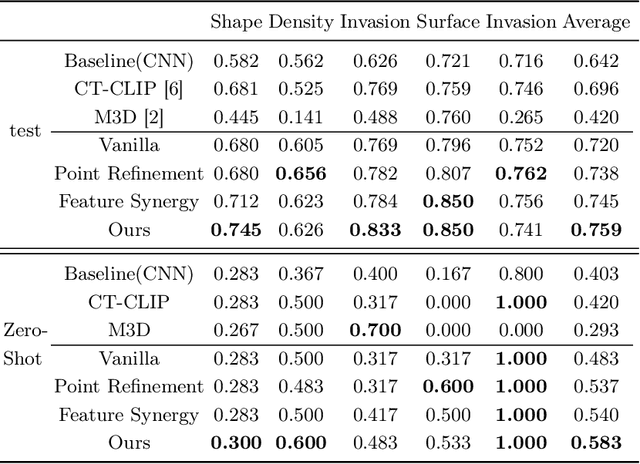
Automated CT report generation plays a crucial role in improving diagnostic accuracy and clinical workflow efficiency. However, existing methods lack interpretability and impede patient-clinician understanding, while their static nature restricts radiologists from dynamically adjusting assessments during image review. Inspired by interactive segmentation techniques, we propose a novel interactive framework for 3D lesion morphology reporting that seamlessly generates segmentation masks with comprehensive attribute descriptions, enabling clinicians to generate detailed lesion profiles for enhanced diagnostic assessment. To our best knowledge, we are the first to integrate the interactive segmentation and structured reports in 3D CT medical images. Experimental results across 15 lesion types demonstrate the effectiveness of our approach in providing a more comprehensive and reliable reporting system for lesion segmentation and capturing. The source code will be made publicly available following paper acceptance.
A Data-Efficient Pan-Tumor Foundation Model for Oncology CT Interpretation
Feb 10, 2025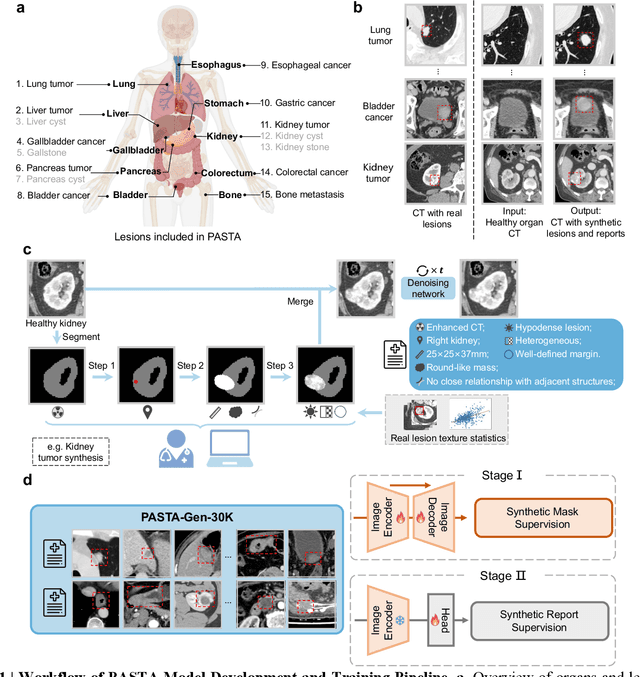
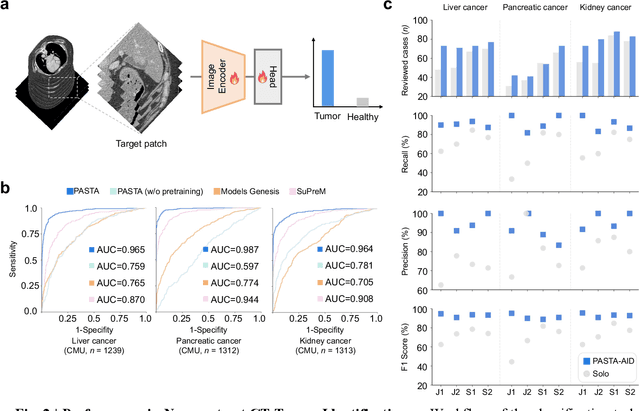
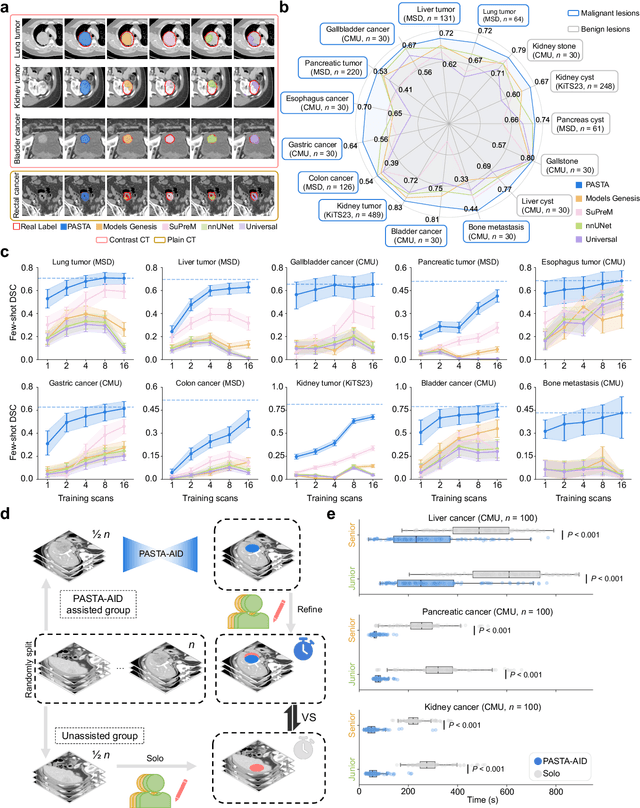
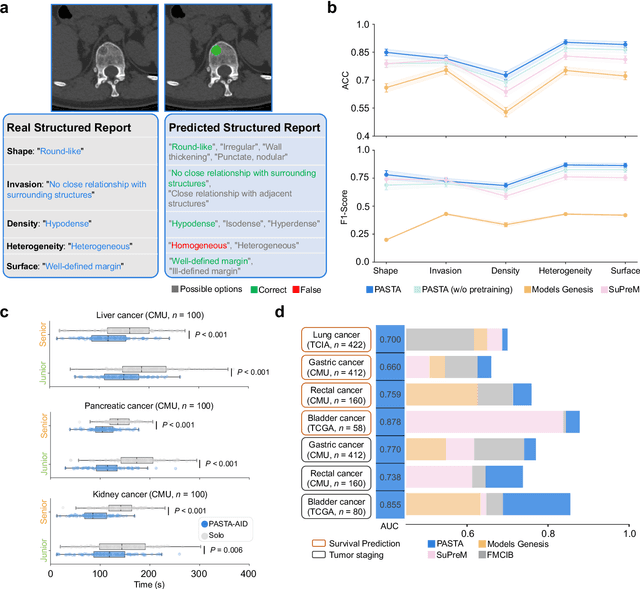
Artificial intelligence-assisted imaging analysis has made substantial strides in tumor diagnosis and management. Here we present PASTA, a pan-tumor CT foundation model that achieves state-of-the-art performance on 45 of 46 representative oncology tasks -- including lesion segmentation, tumor detection in plain CT, tumor staging, survival prediction, structured report generation, and cross-modality transfer learning, significantly outperforming the second-best models on 35 tasks. This remarkable advancement is driven by our development of PASTA-Gen, an innovative synthetic tumor generation framework that produces a comprehensive dataset of 30,000 CT scans with pixel-level annotated lesions and paired structured reports, encompassing malignancies across ten organs and five benign lesion types. By leveraging this rich, high-quality synthetic data, we overcome a longstanding bottleneck in the development of CT foundation models -- specifically, the scarcity of publicly available, high-quality annotated datasets due to privacy constraints and the substantial labor required for scaling precise data annotation. Encouragingly, PASTA demonstrates exceptional data efficiency with promising practical value, markedly improving performance on various tasks with only a small amount of real-world data. The open release of both the synthetic dataset and PASTA foundation model effectively addresses the challenge of data scarcity, thereby advancing oncological research and clinical translation.
Unleashing the Potential of Vision-Language Pre-Training for 3D Zero-Shot Lesion Segmentation via Mask-Attribute Alignment
Oct 21, 2024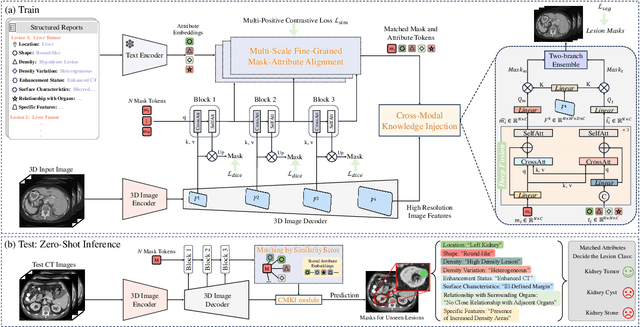
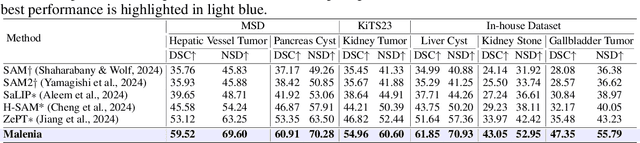
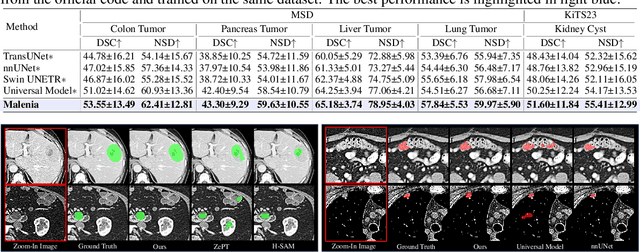
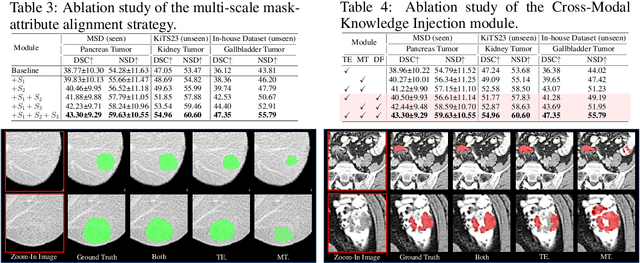
Recent advancements in medical vision-language pre-training models have driven significant progress in zero-shot disease recognition. However, transferring image-level knowledge to pixel-level tasks, such as lesion segmentation in 3D CT scans, remains a critical challenge. Due to the complexity and variability of pathological visual characteristics, existing methods struggle to align fine-grained lesion features not encountered during training with disease-related textual representations. In this paper, we present Malenia, a novel multi-scale lesion-level mask-attribute alignment framework, specifically designed for 3D zero-shot lesion segmentation. Malenia improves the compatibility between mask representations and their associated elemental attributes, explicitly linking the visual features of unseen lesions with the extensible knowledge learned from previously seen ones. Furthermore, we design a Cross-Modal Knowledge Injection module to enhance both visual and textual features with mutually beneficial information, effectively guiding the generation of segmentation results. Comprehensive experiments across three datasets and 12 lesion categories validate the superior performance of Malenia. Codes will be publicly available.
CT Synthesis with Conditional Diffusion Models for Abdominal Lymph Node Segmentation
Mar 26, 2024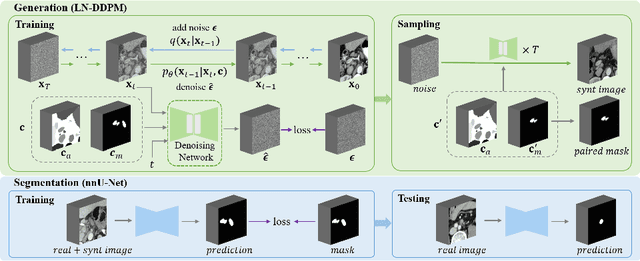
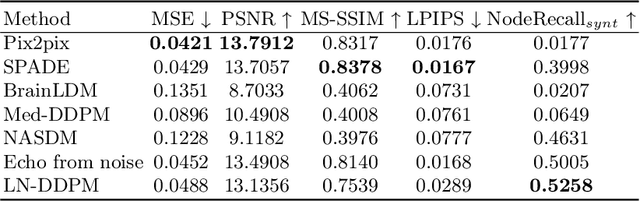
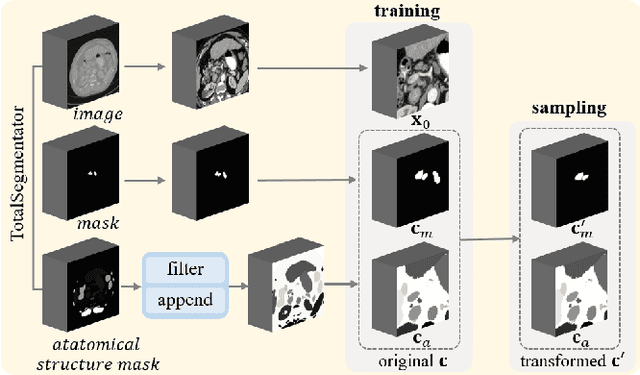
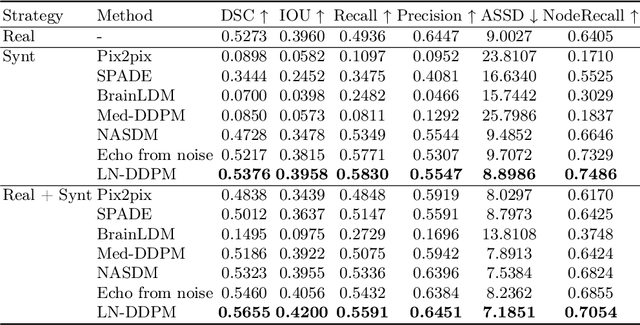
Despite the significant success achieved by deep learning methods in medical image segmentation, researchers still struggle in the computer-aided diagnosis of abdominal lymph nodes due to the complex abdominal environment, small and indistinguishable lesions, and limited annotated data. To address these problems, we present a pipeline that integrates the conditional diffusion model for lymph node generation and the nnU-Net model for lymph node segmentation to improve the segmentation performance of abdominal lymph nodes through synthesizing a diversity of realistic abdominal lymph node data. We propose LN-DDPM, a conditional denoising diffusion probabilistic model (DDPM) for lymph node (LN) generation. LN-DDPM utilizes lymph node masks and anatomical structure masks as model conditions. These conditions work in two conditioning mechanisms: global structure conditioning and local detail conditioning, to distinguish between lymph nodes and their surroundings and better capture lymph node characteristics. The obtained paired abdominal lymph node images and masks are used for the downstream segmentation task. Experimental results on the abdominal lymph node datasets demonstrate that LN-DDPM outperforms other generative methods in the abdominal lymph node image synthesis and better assists the downstream abdominal lymph node segmentation task.
Efficient Subclass Segmentation in Medical Images
Jul 01, 2023



As research interests in medical image analysis become increasingly fine-grained, the cost for extensive annotation also rises. One feasible way to reduce the cost is to annotate with coarse-grained superclass labels while using limited fine-grained annotations as a complement. In this way, fine-grained data learning is assisted by ample coarse annotations. Recent studies in classification tasks have adopted this method to achieve satisfactory results. However, there is a lack of research on efficient learning of fine-grained subclasses in semantic segmentation tasks. In this paper, we propose a novel approach that leverages the hierarchical structure of categories to design network architecture. Meanwhile, a task-driven data generation method is presented to make it easier for the network to recognize different subclass categories. Specifically, we introduce a Prior Concatenation module that enhances confidence in subclass segmentation by concatenating predicted logits from the superclass classifier, a Separate Normalization module that stretches the intra-class distance within the same superclass to facilitate subclass segmentation, and a HierarchicalMix model that generates high-quality pseudo labels for unlabeled samples by fusing only similar superclass regions from labeled and unlabeled images. Our experiments on the BraTS2021 and ACDC datasets demonstrate that our approach achieves comparable accuracy to a model trained with full subclass annotations, with limited subclass annotations and sufficient superclass annotations. Our approach offers a promising solution for efficient fine-grained subclass segmentation in medical images. Our code is publicly available here.
MedLSAM: Localize and Segment Anything Model for 3D Medical Images
Jun 30, 2023The Segment Anything Model (SAM) has recently emerged as a groundbreaking model in the field of image segmentation. Nevertheless, both the original SAM and its medical adaptations necessitate slice-by-slice annotations, which directly increase the annotation workload with the size of the dataset. We propose MedLSAM to address this issue, ensuring a constant annotation workload irrespective of dataset size and thereby simplifying the annotation process. Our model introduces a few-shot localization framework capable of localizing any target anatomical part within the body. To achieve this, we develop a Localize Anything Model for 3D Medical Images (MedLAM), utilizing two self-supervision tasks: relative distance regression (RDR) and multi-scale similarity (MSS) across a comprehensive dataset of 14,012 CT scans. We then establish a methodology for accurate segmentation by integrating MedLAM with SAM. By annotating only six extreme points across three directions on a few templates, our model can autonomously identify the target anatomical region on all data scheduled for annotation. This allows our framework to generate a 2D bounding box for every slice of the image, which are then leveraged by SAM to carry out segmentations. We conducted experiments on two 3D datasets covering 38 organs and found that MedLSAM matches the performance of SAM and its medical adaptations while requiring only minimal extreme point annotations for the entire dataset. Furthermore, MedLAM has the potential to be seamlessly integrated with future 3D SAM models, paving the way for enhanced performance. Our code is public at https://github.com/openmedlab/MedLSAM.
CDDSA: Contrastive Domain Disentanglement and Style Augmentation for Generalizable Medical Image Segmentation
Nov 22, 2022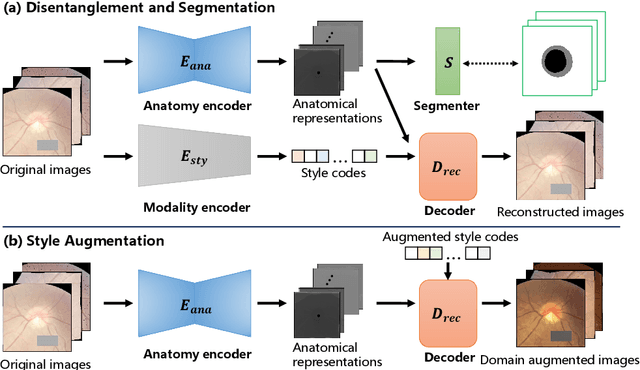
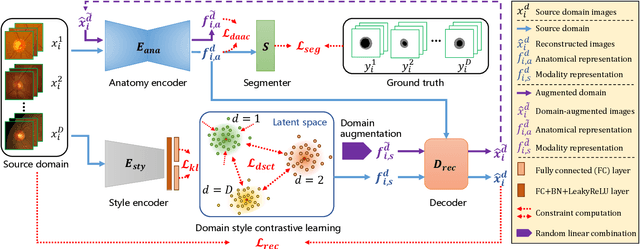

Generalization to previously unseen images with potential domain shifts and different styles is essential for clinically applicable medical image segmentation, and the ability to disentangle domain-specific and domain-invariant features is key for achieving Domain Generalization (DG). However, existing DG methods can hardly achieve effective disentanglement to get high generalizability. To deal with this problem, we propose an efficient Contrastive Domain Disentanglement and Style Augmentation (CDDSA) framework for generalizable medical image segmentation. First, a disentangle network is proposed to decompose an image into a domain-invariant anatomical representation and a domain-specific style code, where the former is sent to a segmentation model that is not affected by the domain shift, and the disentangle network is regularized by a decoder that combines the anatomical and style codes to reconstruct the input image. Second, to achieve better disentanglement, a contrastive loss is proposed to encourage the style codes from the same domain and different domains to be compact and divergent, respectively. Thirdly, to further improve generalizability, we propose a style augmentation method based on the disentanglement representation to synthesize images in various unseen styles with shared anatomical structures. Our method was validated on a public multi-site fundus image dataset for optic cup and disc segmentation and an in-house multi-site Nasopharyngeal Carcinoma Magnetic Resonance Image (NPC-MRI) dataset for nasopharynx Gross Tumor Volume (GTVnx) segmentation. Experimental results showed that the proposed CDDSA achieved remarkable generalizability across different domains, and it outperformed several state-of-the-art methods in domain-generalizable segmentation.
Contrastive Semi-supervised Learning for Domain Adaptive Segmentation Across Similar Anatomical Structures
Aug 18, 2022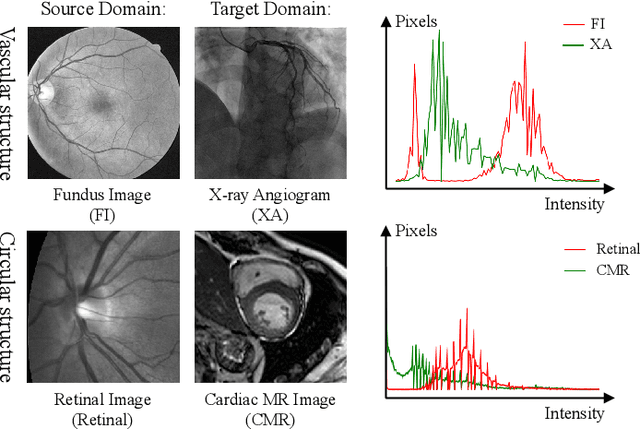
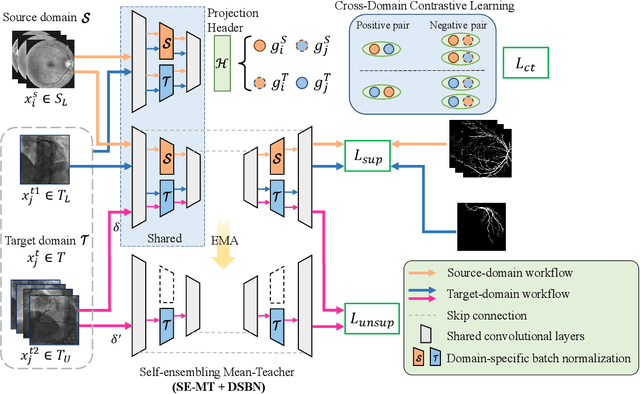
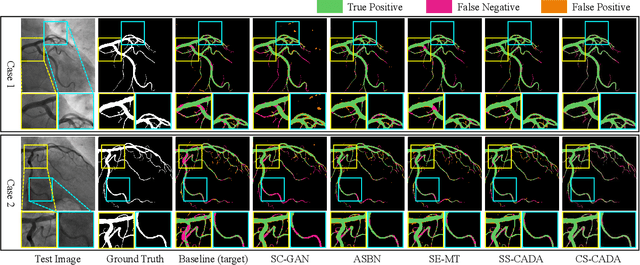
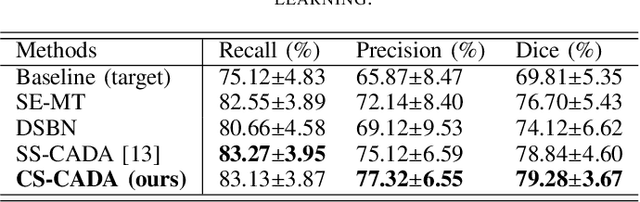
Convolutional Neural Networks (CNNs) have achieved state-of-the-art performance for medical image segmentation, yet need plenty of manual annotations for training. Semi-Supervised Learning (SSL) methods are promising to reduce the requirement of annotations, but their performance is still limited when the dataset size and the number of annotated images are small. Leveraging existing annotated datasets with similar anatomical structures to assist training has a potential for improving the model's performance. However, it is further challenged by the cross-anatomy domain shift due to the different appearance and even imaging modalities from the target structure. To solve this problem, we propose Contrastive Semi-supervised learning for Cross Anatomy Domain Adaptation (CS-CADA) that adapts a model to segment similar structures in a target domain, which requires only limited annotations in the target domain by leveraging a set of existing annotated images of similar structures in a source domain. We use Domain-Specific Batch Normalization (DSBN) to individually normalize feature maps for the two anatomical domains, and propose a cross-domain contrastive learning strategy to encourage extracting domain invariant features. They are integrated into a Self-Ensembling Mean-Teacher (SE-MT) framework to exploit unlabeled target domain images with a prediction consistency constraint. Extensive experiments show that our CS-CADA is able to solve the challenging cross-anatomy domain shift problem, achieving accurate segmentation of coronary arteries in X-ray images with the help of retinal vessel images and cardiac MR images with the help of fundus images, respectively, given only a small number of annotations in the target domain.
HMRNet: High and Multi-Resolution Network with Bidirectional Feature Calibration for Brain Structure Segmentation in Radiotherapy
Jun 07, 2022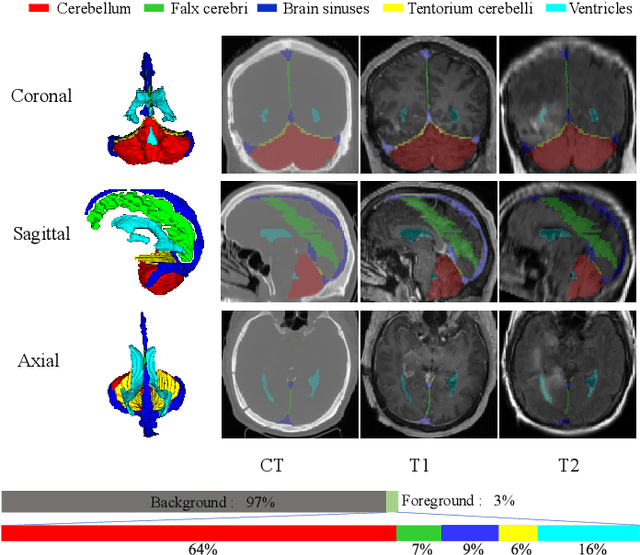
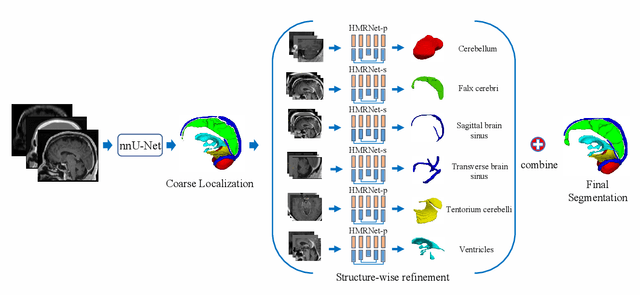

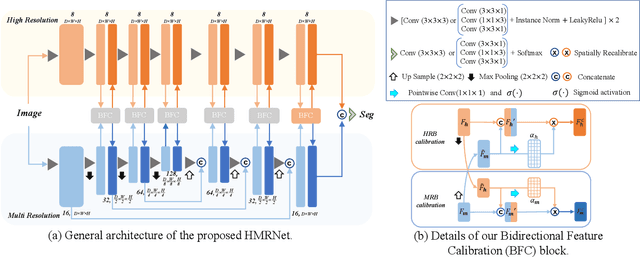
Accurate segmentation of Anatomical brain Barriers to Cancer spread (ABCs) plays an important role for automatic delineation of Clinical Target Volume (CTV) of brain tumors in radiotherapy. Despite that variants of U-Net are state-of-the-art segmentation models, they have limited performance when dealing with ABCs structures with various shapes and sizes, especially thin structures (e.g., the falx cerebri) that span only few slices. To deal with this problem, we propose a High and Multi-Resolution Network (HMRNet) that consists of a multi-scale feature learning branch and a high-resolution branch, which can maintain the high-resolution contextual information and extract more robust representations of anatomical structures with various scales. We further design a Bidirectional Feature Calibration (BFC) block to enable the two branches to generate spatial attention maps for mutual feature calibration. Considering the different sizes and positions of ABCs structures, our network was applied after a rough localization of each structure to obtain fine segmentation results. Experiments on the MICCAI 2020 ABCs challenge dataset showed that: 1) Our proposed two-stage segmentation strategy largely outperformed methods segmenting all the structures in just one stage; 2) The proposed HMRNet with two branches can maintain high-resolution representations and is effective to improve the performance on thin structures; 3) The proposed BFC block outperformed existing attention methods using monodirectional feature calibration. Our method won the second place of ABCs 2020 challenge and has a potential for more accurate and reasonable delineation of CTV of brain tumors.