 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the Potential of Vision-Language Pre-Training for 3D Zero-Shot Lesion Segmentation via Mask-Attribute Alignment
Paper and Code
Oct 21, 2024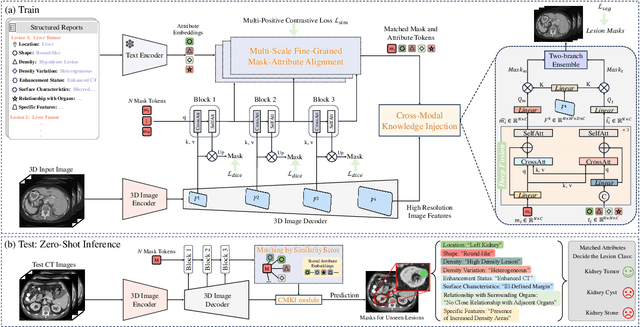
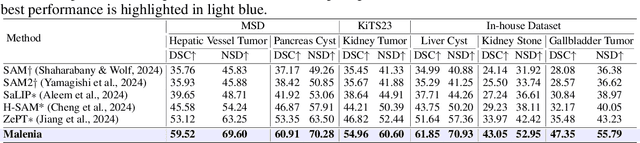
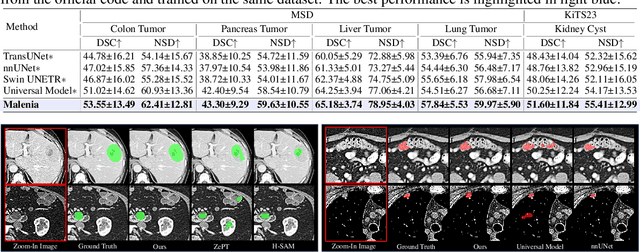
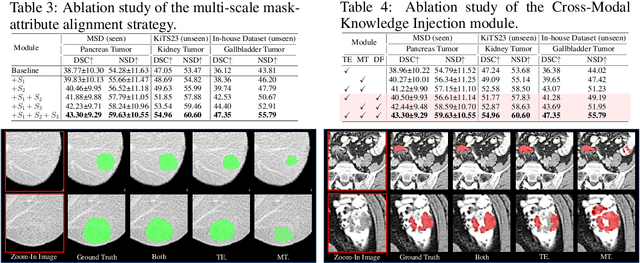
Recent advancements in medical vision-language pre-training models have driven significant progress in zero-shot disease recognition. However, transferring image-level knowledge to pixel-level tasks, such as lesion segmentation in 3D CT scans, remains a critical challenge. Due to the complexity and variability of pathological visual characteristics, existing methods struggle to align fine-grained lesion features not encountered during training with disease-related textual representations. In this paper, we present Malenia, a novel multi-scale lesion-level mask-attribute alignment framework, specifically designed for 3D zero-shot lesion segmentation. Malenia improves the compatibility between mask representations and their associated elemental attributes, explicitly linking the visual features of unseen lesions with the extensible knowledge learned from previously seen ones. Furthermore, we design a Cross-Modal Knowledge Injection module to enhance both visual and textual features with mutually beneficial information, effectively guiding the generation of segmentation results. Comprehensive experiments across three datasets and 12 lesion categories validate the superior performance of Malenia. Codes will be publicly available.