 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedScope: Incentivizing "Think with Videos" for Clinical Reasoning via Coarse-to-Fine Tool Calling
Feb 11, 2026Long-form clinical videos are central to visual evidence-based decision-making, with growing importance for applications such as surgical robotics and related settings. However, current multimodal large language models typically process videos with passive sampling or weakly grounded inspection, which limits their ability to iteratively locate, verify, and justify predictions with temporally targeted evidence. To close this gap, we propose MedScope, a tool-using clinical video reasoning model that performs coarse-to-fine evidence seeking over long-form procedures. By interleaving intermediate reasoning with targeted tool calls and verification on retrieved observations, MedScope produces more accurate and trustworthy predictions that are explicitly grounded in temporally localized visual evidence. To address the lack of high-fidelity supervision, we build ClinVideoSuite, an evidence-centric, fine-grained clinical video suite. We then optimize MedScope with Grounding-Aware Group Relative Policy Optimization (GA-GRPO), which directly reinforces tool use with grounding-aligned rewards and evidence-weighted advantages. On full and fine-grained video understanding benchmarks, MedScope achieves state-of-the-art performance in both in-domain and out-of-domain evaluations. Our approach illuminates a path toward medical AI agents that can genuinely "think with videos" through tool-integrated reasoning. We will release our code, models, and data.
InternAgent-1.5: A Unified Agentic Framework for Long-Horizon Autonomous Scientific Discovery
Feb 09, 2026We introduce InternAgent-1.5, a unified system designed for end-to-end scientific discovery across computational and empirical domains. The system is built on a structured architecture composed of three coordinated subsystems for generation, verification, and evolution. These subsystems are supported by foundational capabilities for deep research, solution optimization, and long horizon memory. The architecture allows InternAgent-1.5 to operate continuously across extended discovery cycles while maintaining coherent and improving behavior. It also enables the system to coordinate computational modeling and laboratory experimentation within a single unified system. We evaluate InternAgent-1.5 on scientific reasoning benchmarks such as GAIA, HLE, GPQA, and FrontierScience, and the system achieves leading performance that demonstrates strong foundational capabilities. Beyond these benchmarks, we further assess two categories of discovery tasks. In algorithm discovery tasks, InternAgent-1.5 autonomously designs competitive methods for core machine learning problems. In empirical discovery tasks, it executes complete computational or wet lab experiments and produces scientific findings in earth, life, biological, and physical domains. Overall, these results show that InternAgent-1.5 provides a general and scalable framework for autonomous scientific discovery.
Beyond Static Tools: Test-Time Tool Evolution for Scientific Reasoning
Jan 12, 2026The central challenge of AI for Science is not reasoning alone, but the ability to create computational methods in an open-ended scientific world. Existing LLM-based agents rely on static, pre-defined tool libraries, a paradigm that fundamentally fails in scientific domains where tools are sparse, heterogeneous, and intrinsically incomplete. In this paper, we propose Test-Time Tool Evolution (TTE), a new paradigm that enables agents to synthesize, verify, and evolve executable tools during inference. By transforming tools from fixed resources into problem-driven artifacts, TTE overcomes the rigidity and long-tail limitations of static tool libraries. To facilitate rigorous evaluation, we introduce SciEvo, a benchmark comprising 1,590 scientific reasoning tasks supported by 925 automatically evolved tools. Extensive experiments show that TTE achieves state-of-the-art performance in both accuracy and tool efficiency, while enabling effective cross-domain adaptation of computational tools. The code and benchmark have been released at https://github.com/lujiaxuan0520/Test-Time-Tool-Evol.
IBISAgent: Reinforcing Pixel-Level Visual Reasoning in MLLMs for Universal Biomedical Object Referring and Segmentation
Jan 06, 2026Recent research on medical MLLMs has gradually shifted its focus from image-level understanding to fine-grained, pixel-level comprehension. Although segmentation serves as the foundation for pixel-level understanding, existing approaches face two major challenges. First, they introduce implicit segmentation tokens and require simultaneous fine-tuning of both the MLLM and external pixel decoders, which increases the risk of catastrophic forgetting and limits generalization to out-of-domain scenarios. Second, most methods rely on single-pass reasoning and lack the capability to iteratively refine segmentation results, leading to suboptimal performance. To overcome these limitations, we propose a novel agentic MLLM, named IBISAgent, that reformulates segmentation as a vision-centric, multi-step decision-making process. IBISAgent enables MLLMs to generate interleaved reasoning and text-based click actions, invoke segmentation tools, and produce high-quality masks without architectural modifications. By iteratively performing multi-step visual reasoning on masked image features, IBISAgent naturally supports mask refinement and promotes the development of pixel-level visual reasoning capabilities. We further design a two-stage training framework consisting of cold-start supervised fine-tuning and agentic reinforcement learning with tailored, fine-grained rewards, enhancing the model's robustness in complex medical referring and reasoning segmentation tasks. Extensive experiments demonstrate that IBISAgent consistently outperforms both closed-source and open-source SOTA methods. All datasets, code, and trained models will be released publicly.
SCP: Accelerating Discovery with a Global Web of Autonomous Scientific Agents
Dec 30, 2025We introduce SCP: the Science Context Protocol, an open-source standard designed to accelerate discovery by enabling a global network of autonomous scientific agents. SCP is built on two foundational pillars: (1) Unified Resource Integration: At its core, SCP provides a universal specification for describing and invoking scientific resources, spanning software tools, models, datasets, and physical instruments. This protocol-level standardization enables AI agents and applications to discover, call, and compose capabilities seamlessly across disparate platforms and institutional boundaries. (2) Orchestrated Experiment Lifecycle Management: SCP complements the protocol with a secure service architecture, which comprises a centralized SCP Hub and federated SCP Servers. This architecture manages the complete experiment lifecycle (registration, planning, execution, monitoring, and archival), enforces fine-grained authentication and authorization, and orchestrates traceable, end-to-end workflows that bridge computational and physical laboratories. Based on SCP, we have constructed a scientific discovery platform that offers researchers and agents a large-scale ecosystem of more than 1,600 tool resources. Across diverse use cases, SCP facilitates secure, large-scale collaboration between heterogeneous AI systems and human researchers while significantly reducing integration overhead and enhancing reproducibility. By standardizing scientific context and tool orchestration at the protocol level, SCP establishes essential infrastructure for scalable, multi-institution, agent-driven science.
Incentivizing Tool-augmented Thinking with Images for Medical Image Analysis
Dec 16, 2025Recent reasoning based medical MLLMs have made progress in generating step by step textual reasoning chains. However, they still struggle with complex tasks that necessitate dynamic and iterative focusing on fine-grained visual regions to achieve precise grounding and diagnosis. We introduce Ophiuchus, a versatile, tool-augmented framework that equips an MLLM to (i) decide when additional visual evidence is needed, (ii) determine where to probe and ground within the medical image, and (iii) seamlessly weave the relevant sub-image content back into an interleaved, multimodal chain of thought. In contrast to prior approaches limited by the performance ceiling of specialized tools, Ophiuchus integrates the model's inherent grounding and perception capabilities with external tools, thereby fostering higher-level reasoning. The core of our method is a three-stage training strategy: cold-start training with tool-integrated reasoning data to achieve basic tool selection and adaptation for inspecting key regions; self-reflection fine-tuning to strengthen reflective reasoning and encourage revisiting tool outputs; and Agentic Tool Reinforcement Learning to directly optimize task-specific rewards and emulate expert-like diagnostic behavior. Extensive experiments show that Ophiuchus consistently outperforms both closed-source and open-source SOTA methods across diverse medical benchmarks, including VQA, detection, and reasoning-based segmentation. Our approach illuminates a path toward medical AI agents that can genuinely "think with images" through tool-integrated reasoning. Datasets, codes, and trained models will be released publicly.
TK-Mamba: Marrying KAN with Mamba for Text-Driven 3D Medical Image Segmentation
May 24, 2025



3D medical image segmentation is vital for clinical diagnosis and treatment but is challenged by high-dimensional data and complex spatial dependencies. Traditional single-modality networks, such as CNNs and Transformers, are often limited by computational inefficiency and constrained contextual modeling in 3D settings. We introduce a novel multimodal framework that leverages Mamba and Kolmogorov-Arnold Networks (KAN) as an efficient backbone for long-sequence modeling. Our approach features three key innovations: First, an EGSC (Enhanced Gated Spatial Convolution) module captures spatial information when unfolding 3D images into 1D sequences. Second, we extend Group-Rational KAN (GR-KAN), a Kolmogorov-Arnold Networks variant with rational basis functions, into 3D-Group-Rational KAN (3D-GR-KAN) for 3D medical imaging - its first application in this domain - enabling superior feature representation tailored to volumetric data. Third, a dual-branch text-driven strategy leverages CLIP's text embeddings: one branch swaps one-hot labels for semantic vectors to preserve inter-organ semantic relationships, while the other aligns images with detailed organ descriptions to enhance semantic alignment. Experiments on the Medical Segmentation Decathlon (MSD) and KiTS23 datasets show our method achieving state-of-the-art performance, surpassing existing approaches in accuracy and efficiency. This work highlights the power of combining advanced sequence modeling, extended network architectures, and vision-language synergy to push forward 3D medical image segmentation, delivering a scalable solution for clinical use. The source code is openly available at https://github.com/yhy-whu/TK-Mamba.
Advancing Generalizable Tumor Segmentation with Anomaly-Aware Open-Vocabulary Attention Maps and Frozen Foundation Diffusion Models
May 05, 2025We explore Generalizable Tumor Segmentation, aiming to train a single model for zero-shot tumor segmentation across diverse anatomical regions. Existing methods face limitations related to segmentation quality, scalability, and the range of applicable imaging modalities. In this paper, we uncover the potential of the internal representations within frozen medical foundation diffusion models as highly efficient zero-shot learners for tumor segmentation by introducing a novel framework named DiffuGTS. DiffuGTS creates anomaly-aware open-vocabulary attention maps based on text prompts to enable generalizable anomaly segmentation without being restricted by a predefined training category list. To further improve and refine anomaly segmentation masks, DiffuGTS leverages the diffusion model, transforming pathological regions into high-quality pseudo-healthy counterparts through latent space inpainting, and applies a novel pixel-level and feature-level residual learning approach, resulting in segmentation masks with significantly enhanced quality and generalization. Comprehensive experiments on four datasets and seven tumor categories demonstrate the superior performance of our method, surpassing current state-of-the-art models across multiple zero-shot settings. Codes are available at https://github.com/Yankai96/DiffuGTS.
Towards All-in-One Medical Image Re-Identification
Mar 11, 2025Medical image re-identification (MedReID) is under-explored so far, despite its critical applications in personalized healthcare and privacy protection. In this paper, we introduce a thorough benchmark and a unified model for this problem. First, to handle various medical modalities, we propose a novel Continuous Modality-based Parameter Adapter (ComPA). ComPA condenses medical content into a continuous modality representation and dynamically adjusts the modality-agnostic model with modality-specific parameters at runtime. This allows a single model to adaptively learn and process diverse modality data. Furthermore, we integrate medical priors into our model by aligning it with a bag of pre-trained medical foundation models, in terms of the differential features. Compared to single-image feature, modeling the inter-image difference better fits the re-identification problem, which involves discriminating multiple images. We evaluate the proposed model against 25 foundation models and 8 large multi-modal language models across 11 image datasets, demonstrating consistently superior performance. Additionally, we deploy the proposed MedReID technique to two real-world applications, i.e., history-augmented personalized diagnosis and medical privacy protection. Codes and model is available at \href{https://github.com/tianyuan168326/All-in-One-MedReID-Pytorch}{https://github.com/tianyuan168326/All-in-One-MedReID-Pytorch}.
A Data-Efficient Pan-Tumor Foundation Model for Oncology CT Interpretation
Feb 10, 2025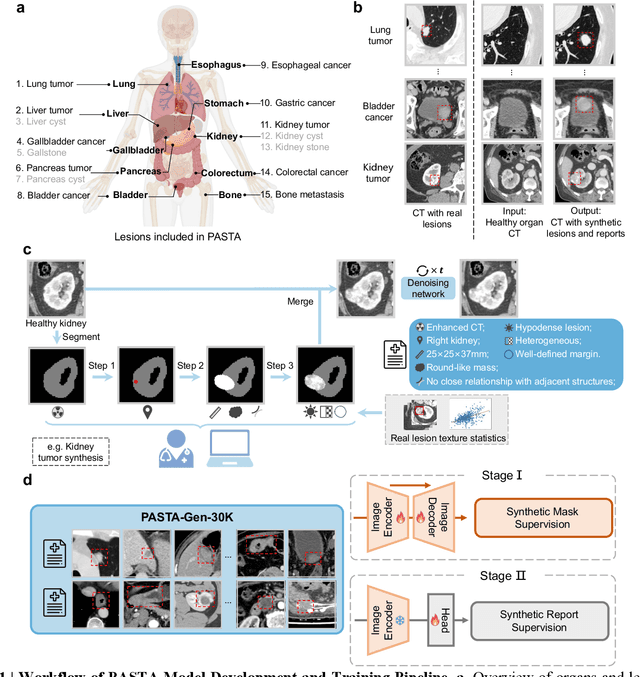
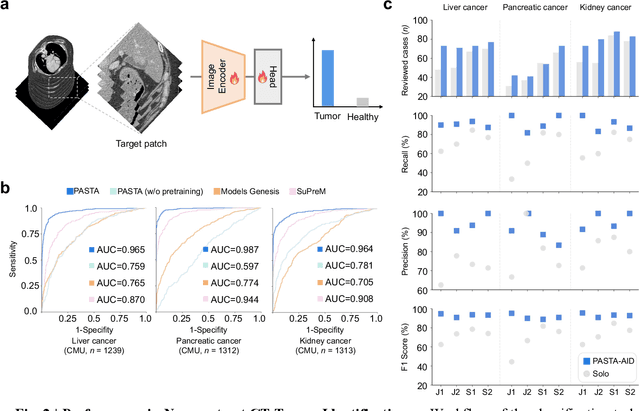
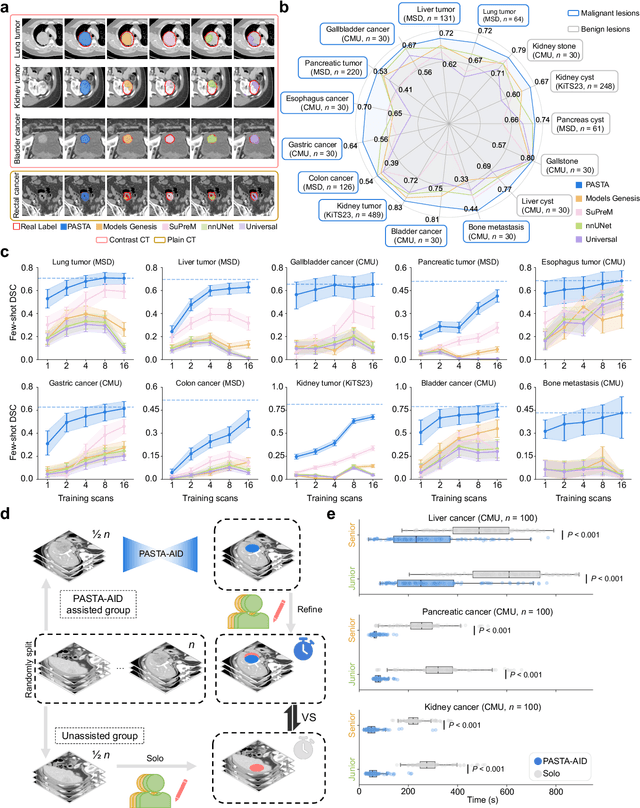
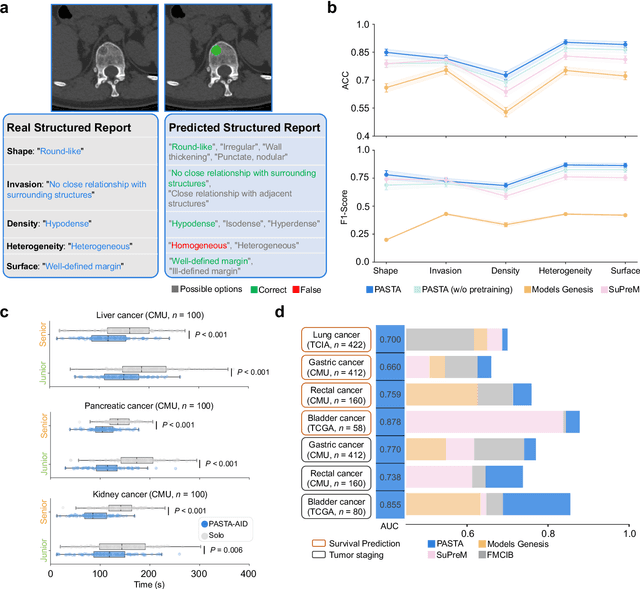
Artificial intelligence-assisted imaging analysis has made substantial strides in tumor diagnosis and management. Here we present PASTA, a pan-tumor CT foundation model that achieves state-of-the-art performance on 45 of 46 representative oncology tasks -- including lesion segmentation, tumor detection in plain CT, tumor staging, survival prediction, structured report generation, and cross-modality transfer learning, significantly outperforming the second-best models on 35 tasks. This remarkable advancement is driven by our development of PASTA-Gen, an innovative synthetic tumor generation framework that produces a comprehensive dataset of 30,000 CT scans with pixel-level annotated lesions and paired structured reports, encompassing malignancies across ten organs and five benign lesion types. By leveraging this rich, high-quality synthetic data, we overcome a longstanding bottleneck in the development of CT foundation models -- specifically, the scarcity of publicly available, high-quality annotated datasets due to privacy constraints and the substantial labor required for scaling precise data annotation. Encouragingly, PASTA demonstrates exceptional data efficiency with promising practical value, markedly improving performance on various tasks with only a small amount of real-world data. The open release of both the synthetic dataset and PASTA foundation model effectively addresses the challenge of data scarcity, thereby advancing oncological research and clinical translation.