 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAT: Coordinating Anatomical-Textual Prompts for Multi-Organ and Tumor Segmentation
Paper and Code
Jun 11, 2024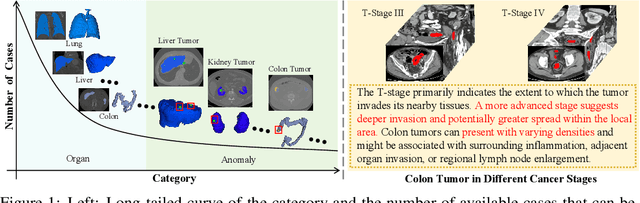
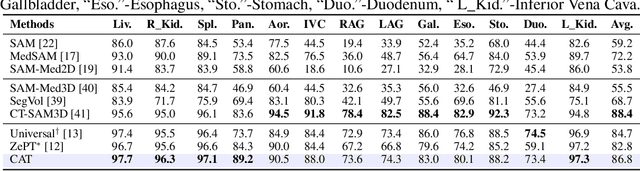
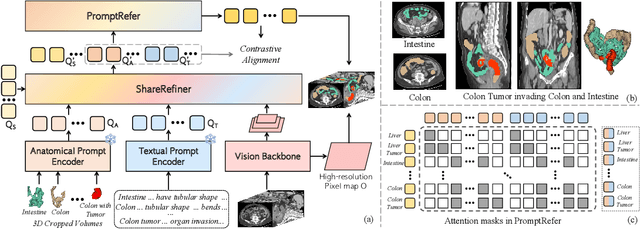
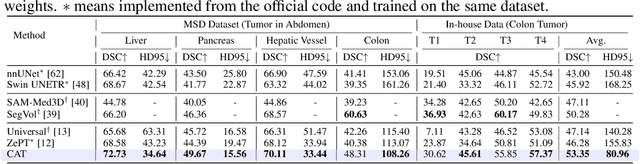
Existing promptable segmentation methods in the medical imaging field primarily consider either textual or visual prompts to segment relevant objects, yet they often fall short when addressing anomalies in medical images, like tumors, which may vary greatly in shape, size, and appearance. Recognizing the complexity of medical scenarios and the limitations of textual or visual prompts, we propose a novel dual-prompt schema that leverages the complementary strengths of visual and textual prompts for segmenting various organs and tumors. Specifically, we introduce CAT, an innovative model that Coordinates Anatomical prompts derived from 3D cropped images with Textual prompts enriched by medical domain knowledge. The model architecture adopts a general query-based design, where prompt queries facilitate segmentation queries for mask prediction. To synergize two types of prompts within a unified framework, we implement a ShareRefiner, which refines both segmentation and prompt queries while disentangling the two types of prompts. Trained on a consortium of 10 public CT datasets, CAT demonstrates superior performance in multiple segmentation tasks. Further validation on a specialized in-house dataset reveals the remarkable capacity of segmenting tumors across multiple cancer stages. This approach confirms that coordinating multimodal prompts is a promising avenue for addressing complex scenarios in the medical domain.