 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroupGPT: A Token-efficient and Privacy-preserving Agentic Framework for Multi-User Chat Assistant
Mar 01, 2026Recent advances in large language models (LLMs) have enabled increasingly capable chatbots. However, most existing systems focus on single-user settings and do not generalize well to multi-user group chats, where agents require more proactive and accurate intervention under complex, evolving contexts. Existing approaches typically rely on LLMs for both reasoning and generation, leading to high token consumption, limited scalability, and potential privacy risks. To address these challenges, we propose GroupGPT, a token-efficient and privacy-preserving agentic framework for multi-user chat assistant. GroupGPT adopts a small-large model collaborative architecture to decouple intervention timing from response generation, enabling efficient and accurate decision-making. The framework also supports multimodal inputs, including memes, images, videos, and voice messages. We further introduce MUIR, a benchmark dataset for multi-user chat assistant intervention reasoning. MUIR contains 2,500 annotated group chat segments with intervention labels and rationales, supporting evaluation of timing accuracy and response quality. We evaluate a range of models on MUIR, from large language models to smaller counterparts. Extensive experiments demonstrate that GroupGPT produces accurate and well-timed responses, achieving an average score of 4.72/5.0 in LLM-based evaluation, and is well received by users across diverse group chat scenarios. Moreover, GroupGPT reduces token usage by up to 3 times compared to baseline methods, while providing privacy sanitization of user messages before cloud transmission. Code is available at: https://github.com/Eliot-Shen/GroupGPT .
Analyzable Chain-of-Musical-Thought Prompting for High-Fidelity Music Generation
Mar 25, 2025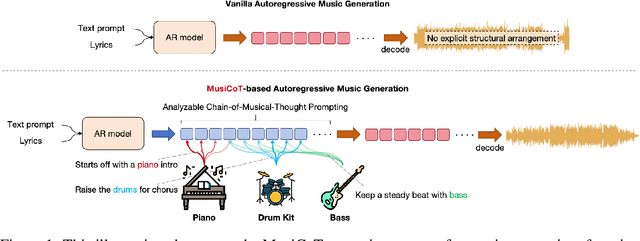
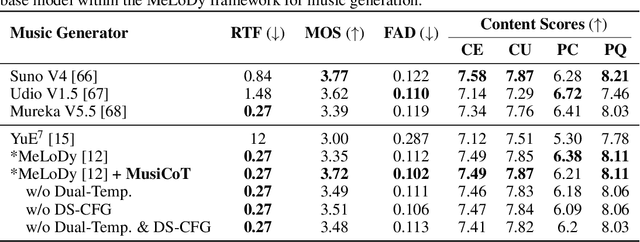
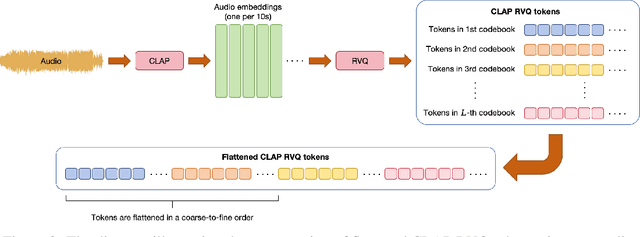
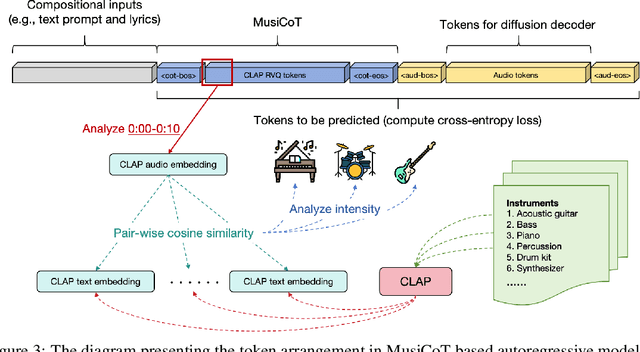
Autoregressive (AR) models have demonstrated impressive capabilities in generating high-fidelity music. However, the conventional next-token prediction paradigm in AR models does not align with the human creative process in music composition, potentially compromising the musicality of generated samples. To overcome this limitation, we introduce MusiCoT, a novel chain-of-thought (CoT) prompting technique tailored for music generation. MusiCoT empowers the AR model to first outline an overall music structure before generating audio tokens, thereby enhancing the coherence and creativity of the resulting compositions. By leveraging the contrastive language-audio pretraining (CLAP) model, we establish a chain of "musical thoughts", making MusiCoT scalable and independent of human-labeled data, in contrast to conventional CoT methods. Moreover, MusiCoT allows for in-depth analysis of music structure, such as instrumental arrangements, and supports music referencing -- accepting variable-length audio inputs as optional style references. This innovative approach effectively addresses copying issues, positioning MusiCoT as a vital practical method for music prompting. Our experimental results indicate that MusiCoT consistently achieves superior performance across both objective and subjective metrics, producing music quality that rivals state-of-the-art generation models. Our samples are available at https://MusiCoT.github.io/.
Interactive Segmentation and Report Generation for CT Images
Mar 05, 2025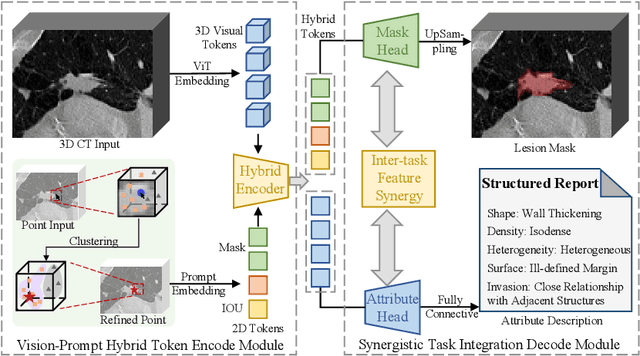
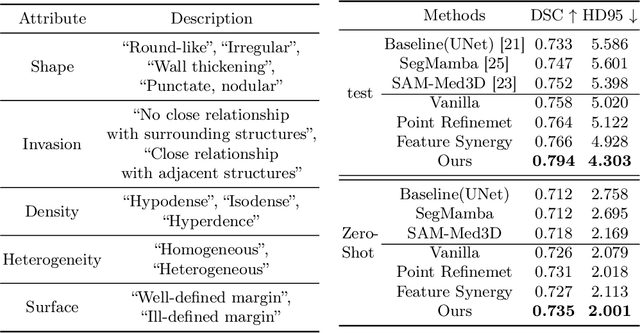

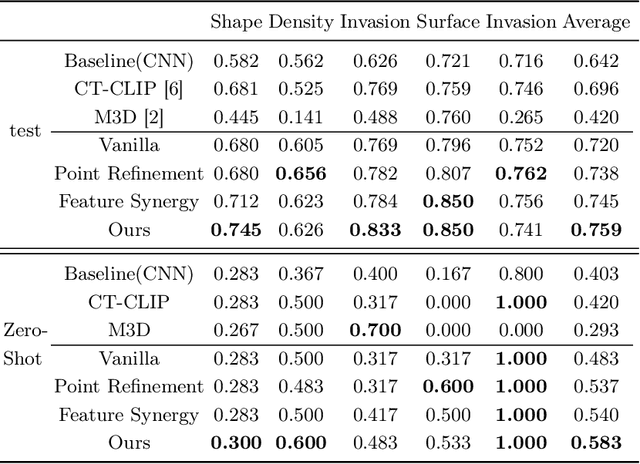
Automated CT report generation plays a crucial role in improving diagnostic accuracy and clinical workflow efficiency. However, existing methods lack interpretability and impede patient-clinician understanding, while their static nature restricts radiologists from dynamically adjusting assessments during image review. Inspired by interactive segmentation techniques, we propose a novel interactive framework for 3D lesion morphology reporting that seamlessly generates segmentation masks with comprehensive attribute descriptions, enabling clinicians to generate detailed lesion profiles for enhanced diagnostic assessment. To our best knowledge, we are the first to integrate the interactive segmentation and structured reports in 3D CT medical images. Experimental results across 15 lesion types demonstrate the effectiveness of our approach in providing a more comprehensive and reliable reporting system for lesion segmentation and capturing. The source code will be made publicly available following paper acceptance.
A Data-Efficient Pan-Tumor Foundation Model for Oncology CT Interpretation
Feb 10, 2025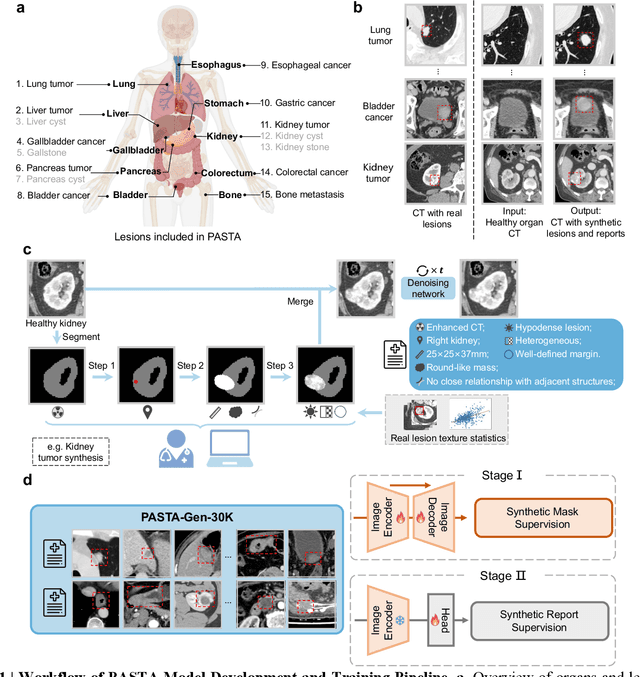
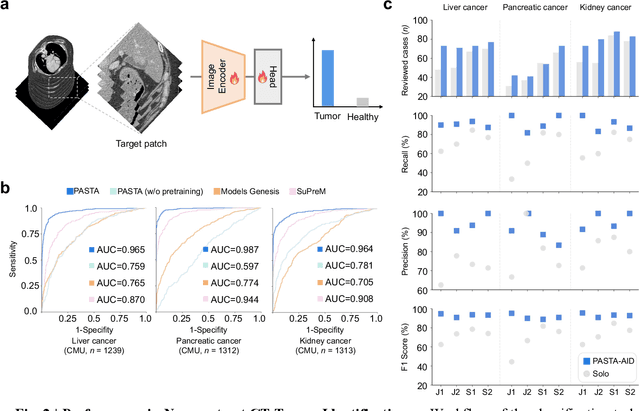
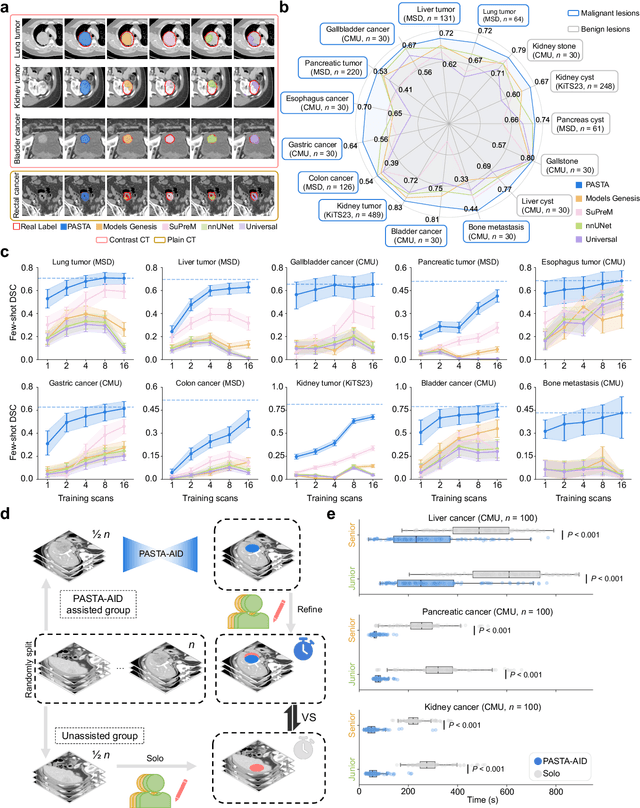
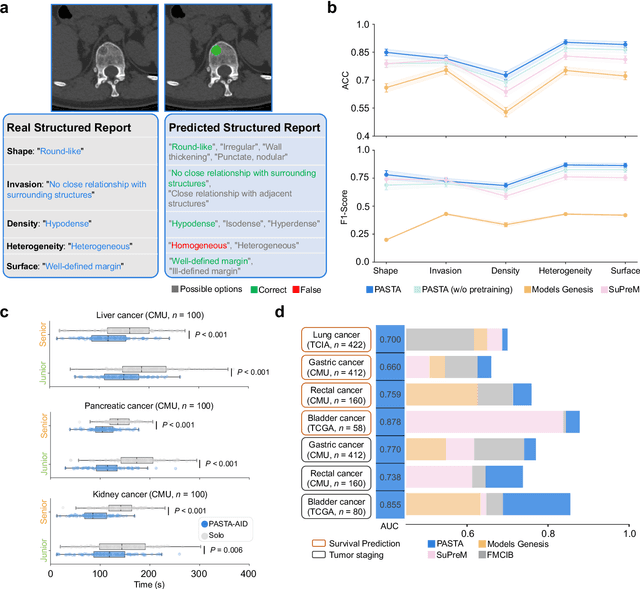
Artificial intelligence-assisted imaging analysis has made substantial strides in tumor diagnosis and management. Here we present PASTA, a pan-tumor CT foundation model that achieves state-of-the-art performance on 45 of 46 representative oncology tasks -- including lesion segmentation, tumor detection in plain CT, tumor staging, survival prediction, structured report generation, and cross-modality transfer learning, significantly outperforming the second-best models on 35 tasks. This remarkable advancement is driven by our development of PASTA-Gen, an innovative synthetic tumor generation framework that produces a comprehensive dataset of 30,000 CT scans with pixel-level annotated lesions and paired structured reports, encompassing malignancies across ten organs and five benign lesion types. By leveraging this rich, high-quality synthetic data, we overcome a longstanding bottleneck in the development of CT foundation models -- specifically, the scarcity of publicly available, high-quality annotated datasets due to privacy constraints and the substantial labor required for scaling precise data annotation. Encouragingly, PASTA demonstrates exceptional data efficiency with promising practical value, markedly improving performance on various tasks with only a small amount of real-world data. The open release of both the synthetic dataset and PASTA foundation model effectively addresses the challenge of data scarcity, thereby advancing oncological research and clinical translation.
Doppelgangers++: Improved Visual Disambiguation with Geometric 3D Features
Dec 08, 2024



Accurate 3D reconstruction is frequently hindered by visual aliasing, where visually similar but distinct surfaces (aka, doppelgangers), are incorrectly matched. These spurious matches distort the structure-from-motion (SfM) process, leading to misplaced model elements and reduced accuracy. Prior efforts addressed this with CNN classifiers trained on curated datasets, but these approaches struggle to generalize across diverse real-world scenes and can require extensive parameter tuning. In this work, we present Doppelgangers++, a method to enhance doppelganger detection and improve 3D reconstruction accuracy. Our contributions include a diversified training dataset that incorporates geo-tagged images from everyday scenes to expand robustness beyond landmark-based datasets. We further propose a Transformer-based classifier that leverages 3D-aware features from the MASt3R model, achieving superior precision and recall across both in-domain and out-of-domain tests. Doppelgangers++ integrates seamlessly into standard SfM and MASt3R-SfM pipelines, offering efficiency and adaptability across varied scenes. To evaluate SfM accuracy, we introduce an automated, geotag-based method for validating reconstructed models, eliminating the need for manual inspection. Through extensive experiments, we demonstrate that Doppelgangers++ significantly enhances pairwise visual disambiguation and improves 3D reconstruction quality in complex and diverse scenarios.
3D Reconstruction with Fast Dipole Sums
May 29, 2024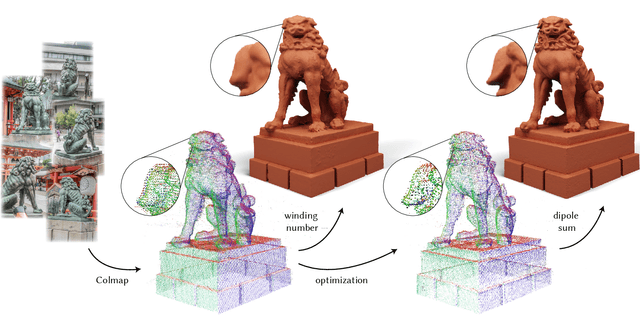

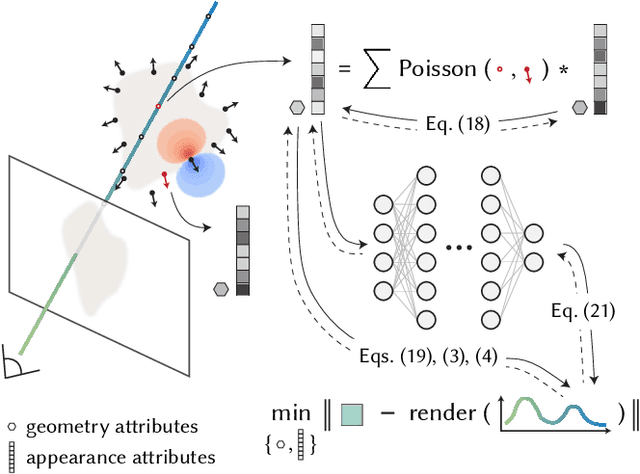

We introduce a technique for the reconstruction of high-fidelity surfaces from multi-view images. Our technique uses a new point-based representation, the dipole sum, which generalizes the winding number to allow for interpolation of arbitrary per-point attributes in point clouds with noisy or outlier points. Using dipole sums allows us to represent implicit geometry and radiance fields as per-point attributes of a point cloud, which we initialize directly from structure from motion. We additionally derive Barnes-Hut fast summation schemes for accelerated forward and reverse-mode dipole sum queries. These queries facilitate the use of ray tracing to efficiently and differentiably render images with our point-based representations, and thus update their point attributes to optimize scene geometry and appearance. We evaluate this inverse rendering framework against state-of-the-art alternatives, based on ray tracing of neural representations or rasterization of Gaussian point-based representations. Our technique significantly improves reconstruction quality at equal runtimes, while also supporting more general rendering techniques such as shadow rays for direct illumination. In the supplement, we provide interactive visualizations of our results.
Deep Data Consistency: a Fast and Robust Diffusion Model-based Solver for Inverse Problems
May 17, 2024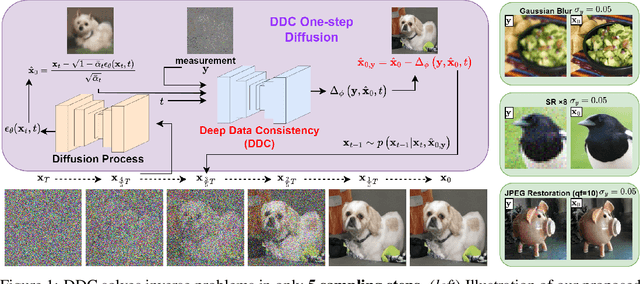
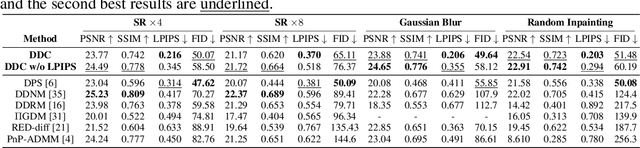
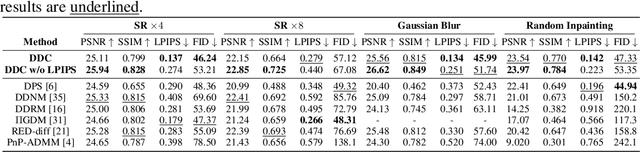
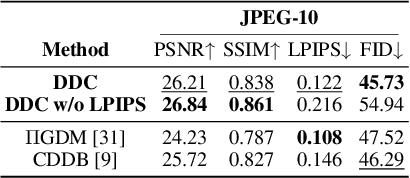
Diffusion models have become a successful approach for solving various image inverse problems by providing a powerful diffusion prior. Many studies tried to combine the measurement into diffusion by score function replacement, matrix decomposition, or optimization algorithms, but it is hard to balance the data consistency and realness. The slow sampling speed is also a main obstacle to its wide application. To address the challenges, we propose Deep Data Consistency (DDC) to update the data consistency step with a deep learning model when solving inverse problems with diffusion models. By analyzing existing methods, the variational bound training objective is used to maximize the conditional posterior and reduce its impact on the diffusion process. In comparison with state-of-the-art methods in linear and non-linear tasks, DDC demonstrates its outstanding performance of both similarity and realness metrics in generating high-quality solutions with only 5 inference steps in 0.77 seconds on average. In addition, the robustness of DDC is well illustrated in the experiments across datasets, with large noise and the capacity to solve multiple tasks in only one pre-trained model.
CT Synthesis with Conditional Diffusion Models for Abdominal Lymph Node Segmentation
Mar 26, 2024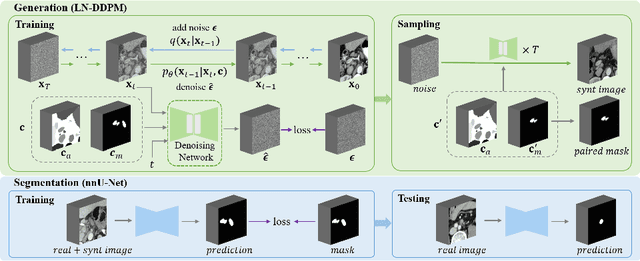
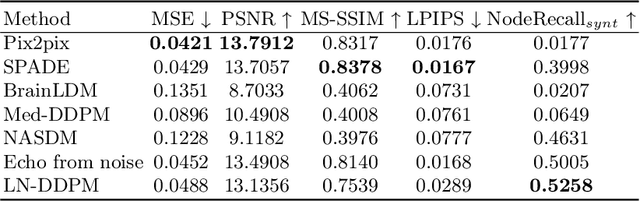
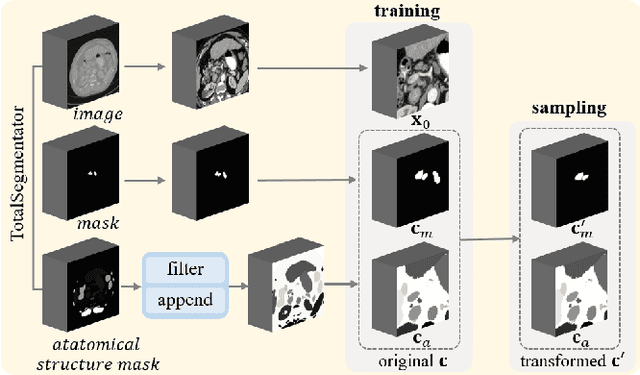
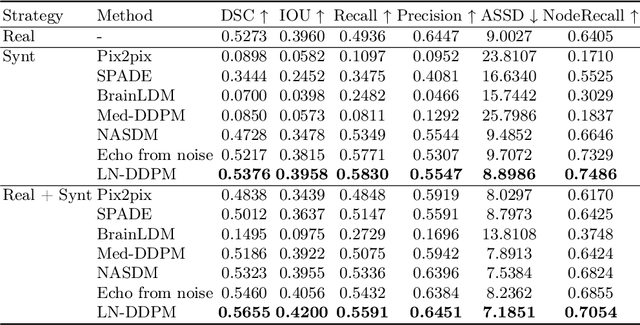
Despite the significant success achieved by deep learning methods in medical image segmentation, researchers still struggle in the computer-aided diagnosis of abdominal lymph nodes due to the complex abdominal environment, small and indistinguishable lesions, and limited annotated data. To address these problems, we present a pipeline that integrates the conditional diffusion model for lymph node generation and the nnU-Net model for lymph node segmentation to improve the segmentation performance of abdominal lymph nodes through synthesizing a diversity of realistic abdominal lymph node data. We propose LN-DDPM, a conditional denoising diffusion probabilistic model (DDPM) for lymph node (LN) generation. LN-DDPM utilizes lymph node masks and anatomical structure masks as model conditions. These conditions work in two conditioning mechanisms: global structure conditioning and local detail conditioning, to distinguish between lymph nodes and their surroundings and better capture lymph node characteristics. The obtained paired abdominal lymph node images and masks are used for the downstream segmentation task. Experimental results on the abdominal lymph node datasets demonstrate that LN-DDPM outperforms other generative methods in the abdominal lymph node image synthesis and better assists the downstream abdominal lymph node segmentation task.
Mitigating Data Consistency Induced Discrepancy in Cascaded Diffusion Models for Sparse-view CT Reconstruction
Mar 14, 2024
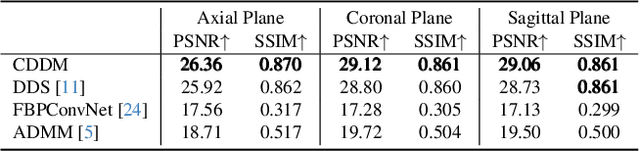
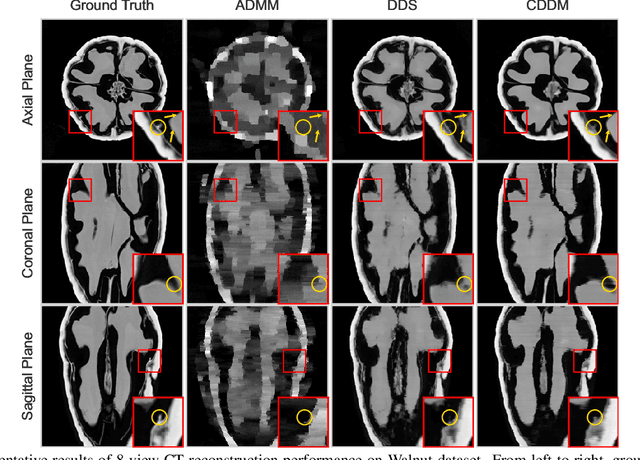
Sparse-view Computed Tomography (CT) image reconstruction is a promising approach to reduce radiation exposure, but it inevitably leads to image degradation. Although diffusion model-based approaches are computationally expensive and suffer from the training-sampling discrepancy, they provide a potential solution to the problem. This study introduces a novel Cascaded Diffusion with Discrepancy Mitigation (CDDM) framework, including the low-quality image generation in latent space and the high-quality image generation in pixel space which contains data consistency and discrepancy mitigation in a one-step reconstruction process. The cascaded framework minimizes computational costs by moving some inference steps from pixel space to latent space. The discrepancy mitigation technique addresses the training-sampling gap induced by data consistency, ensuring the data distribution is close to the original manifold. A specialized Alternating Direction Method of Multipliers (ADMM) is employed to process image gradients in separate directions, offering a more targeted approach to regularization. Experimental results across two datasets demonstrate CDDM's superior performance in high-quality image generation with clearer boundaries compared to existing methods, highlighting the framework's computational efficiency.
A theory of volumetric representations for opaque solids
Dec 24, 2023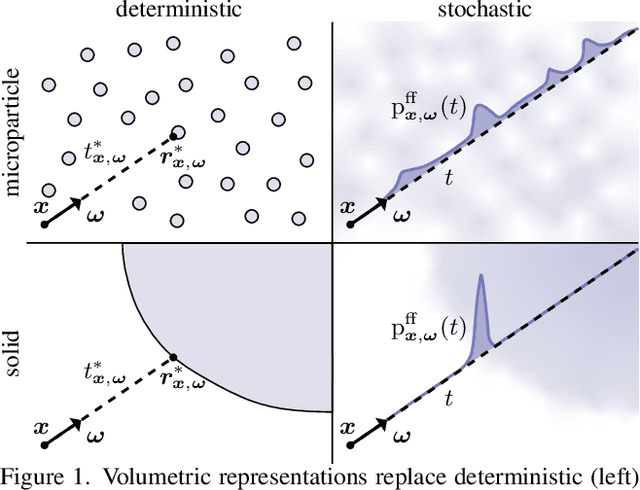

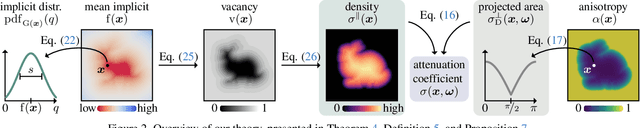
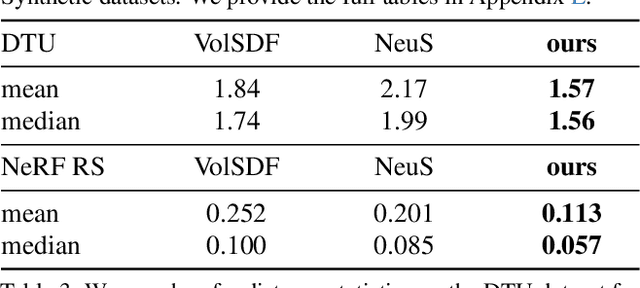
We develop a theory for the representation of opaque solids as volumetric models. Starting from a stochastic representation of opaque solids as random indicator functions, we prove the conditions under which such solids can be modeled using exponential volumetric transport. We also derive expressions for the volumetric attenuation coefficient as a functional of the probability distributions of the underlying indicator functions. We generalize our theory to account for isotropic and anisotropic scattering at different parts of the solid, and for representations of opaque solids as implicit surfaces. We derive our volumetric representation from first principles, which ensures that it satisfies physical constraints such as reciprocity and reversibility. We use our theory to explain, compare, and correct previous volumetric representations, as well as propose meaningful extensions that lead to improved performance in 3D reconstruction tasks.