 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel Extrapolation for MIMO Systems with the Assistance of Multi-path Information Induced from Channel State Information
Jan 29, 2026Acquiring channel state information (CSI) through traditional methods, such as channel estimation, is increasingly challenging for the emerging sixth generation (6G) mobile networks due to high overhead. To address this issue, channel extrapolation techniques have been proposed to acquire complete CSI from a limited number of known CSIs. To improve extrapolation accuracy, environmental information, such as visual images or radar data, has been utilized, which poses challenges including additional hardware, privacy and multi-modal alignment concerns. To this end, this paper proposes a novel channel extrapolation framework by leveraging environment-related multi-path characteristics induced directly from CSI without integrating additional modalities. Specifically, we propose utilizing the multi-path characteristics in the form of power-delay profile (PDP), which is acquired using a CSI-to-PDP module. CSI-to-PDP module is trained in an AE-based framework by reconstructing the PDPs and constraining the latent low-dimensional features to represent the CSI. We further extract the total power & power-weighted delay of all the identified paths in PDP as the multi-path information. Building on this, we proposed a MAE architecture trained in a self-supervised manner to perform channel extrapolation. Unlike standard MAE approaches, our method employs separate encoders to extract features from the masked CSI and the multi-path information, which are then fused by a cross-attention module. Extensive simulations demonstrate that this framework improves extrapolation performance dramatically, with a minor increase in inference time (around 0.1 ms). Furthermore, our model shows strong generalization capabilities, particularly when only a small portion of the CSI is known, outperforming existing benchmarks.
Enhancing User-Oriented Proactivity in Open-Domain Dialogues with Critic Guidance
May 18, 2025
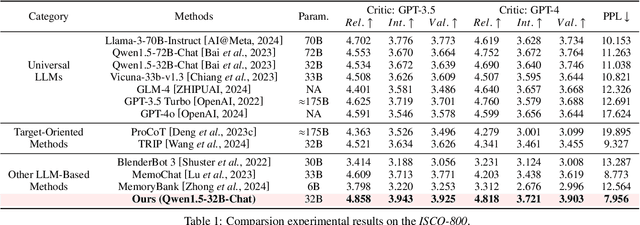
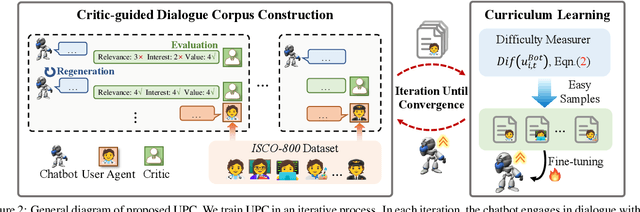

Open-domain dialogue systems aim to generate natural and engaging conversations, providing significant practical value in real applications such as social robotics and personal assistants. The advent of large language models (LLMs) has greatly advanced this field by improving context understanding and conversational fluency. However, existing LLM-based dialogue systems often fall short in proactively understanding the user's chatting preferences and guiding conversations toward user-centered topics. This lack of user-oriented proactivity can lead users to feel unappreciated, reducing their satisfaction and willingness to continue the conversation in human-computer interactions. To address this issue, we propose a User-oriented Proactive Chatbot (UPC) to enhance the user-oriented proactivity. Specifically, we first construct a critic to evaluate this proactivity inspired by the LLM-as-a-judge strategy. Given the scarcity of high-quality training data, we then employ the critic to guide dialogues between the chatbot and user agents, generating a corpus with enhanced user-oriented proactivity. To ensure the diversity of the user backgrounds, we introduce the ISCO-800, a diverse user background dataset for constructing user agents. Moreover, considering the communication difficulty varies among users, we propose an iterative curriculum learning method that trains the chatbot from easy-to-communicate users to more challenging ones, thereby gradually enhancing its performance. Experiments demonstrate that our proposed training method is applicable to different LLMs, improving user-oriented proactivity and attractiveness in open-domain dialogues.
A Data-Efficient Pan-Tumor Foundation Model for Oncology CT Interpretation
Feb 10, 2025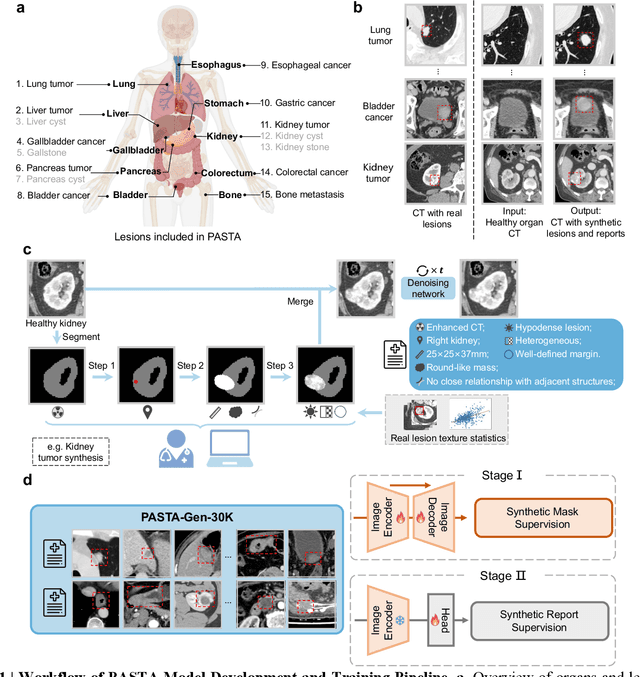
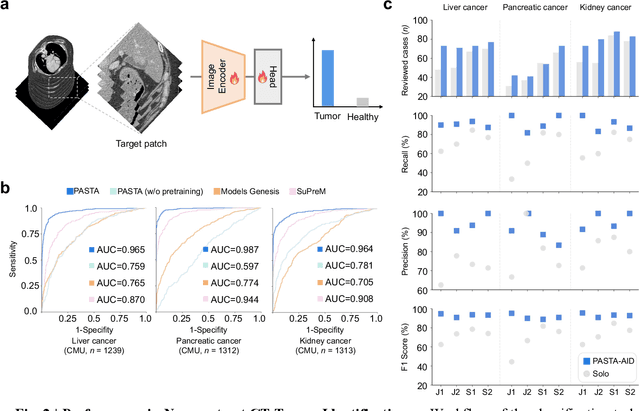
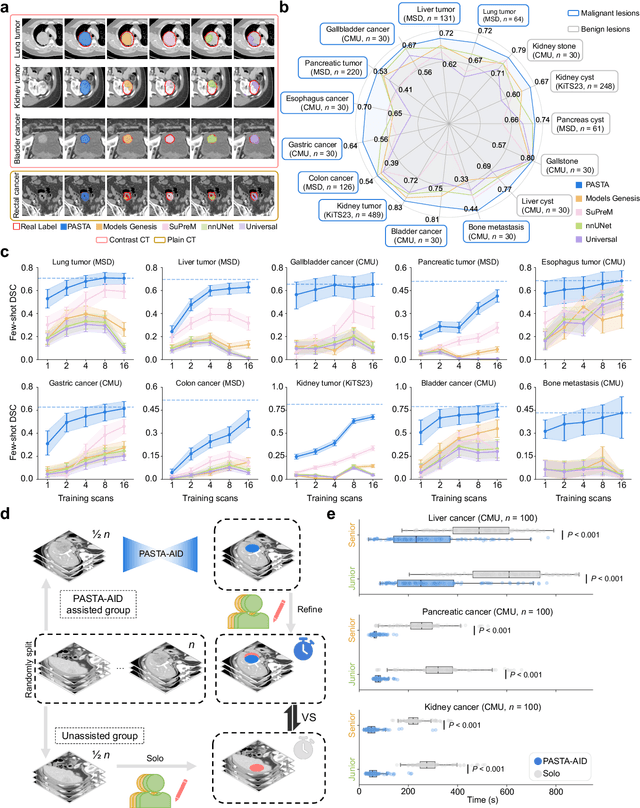
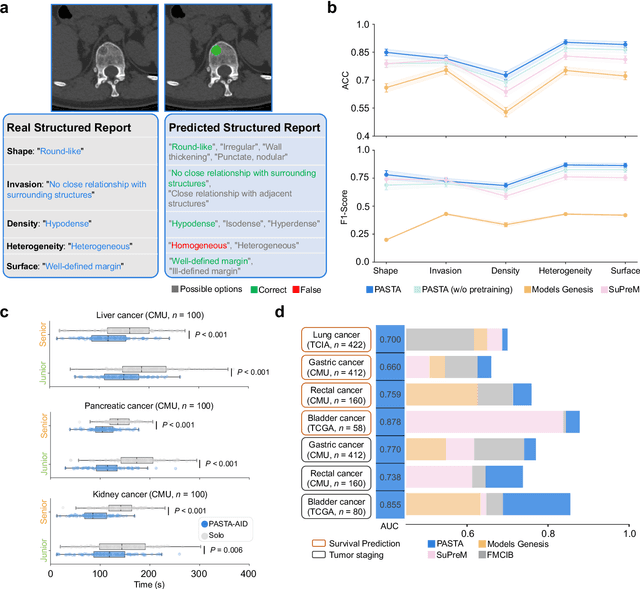
Artificial intelligence-assisted imaging analysis has made substantial strides in tumor diagnosis and management. Here we present PASTA, a pan-tumor CT foundation model that achieves state-of-the-art performance on 45 of 46 representative oncology tasks -- including lesion segmentation, tumor detection in plain CT, tumor staging, survival prediction, structured report generation, and cross-modality transfer learning, significantly outperforming the second-best models on 35 tasks. This remarkable advancement is driven by our development of PASTA-Gen, an innovative synthetic tumor generation framework that produces a comprehensive dataset of 30,000 CT scans with pixel-level annotated lesions and paired structured reports, encompassing malignancies across ten organs and five benign lesion types. By leveraging this rich, high-quality synthetic data, we overcome a longstanding bottleneck in the development of CT foundation models -- specifically, the scarcity of publicly available, high-quality annotated datasets due to privacy constraints and the substantial labor required for scaling precise data annotation. Encouragingly, PASTA demonstrates exceptional data efficiency with promising practical value, markedly improving performance on various tasks with only a small amount of real-world data. The open release of both the synthetic dataset and PASTA foundation model effectively addresses the challenge of data scarcity, thereby advancing oncological research and clinical translation.
SpotLight: Shadow-Guided Object Relighting via Diffusion
Nov 27, 2024Recent work has shown that diffusion models can be used as powerful neural rendering engines that can be leveraged for inserting virtual objects into images. Unlike typical physics-based renderers, however, neural rendering engines are limited by the lack of manual control over the lighting setup, which is often essential for improving or personalizing the desired image outcome. In this paper, we show that precise lighting control can be achieved for object relighting simply by specifying the desired shadows of the object. Rather surprisingly, we show that injecting only the shadow of the object into a pre-trained diffusion-based neural renderer enables it to accurately shade the object according to the desired light position, while properly harmonizing the object (and its shadow) within the target background image. Our method, SpotLight, leverages existing neural rendering approaches and achieves controllable relighting results with no additional training. Specifically, we demonstrate its use with two neural renderers from the recent literature. We show that SpotLight achieves superior object compositing results, both quantitatively and perceptually, as confirmed by a user study, outperforming existing diffusion-based models specifically designed for relighting.
ZeroComp: Zero-shot Object Compositing from Image Intrinsics via Diffusion
Oct 10, 2024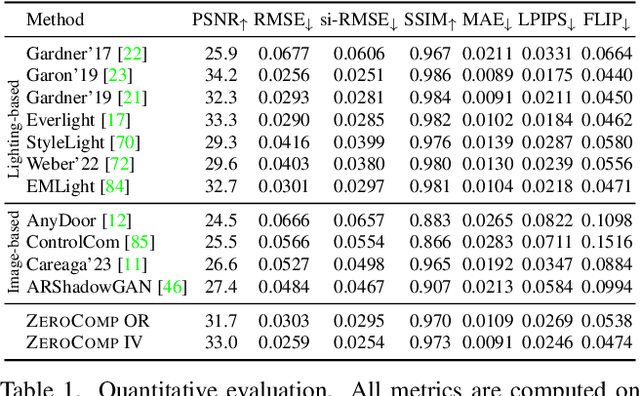
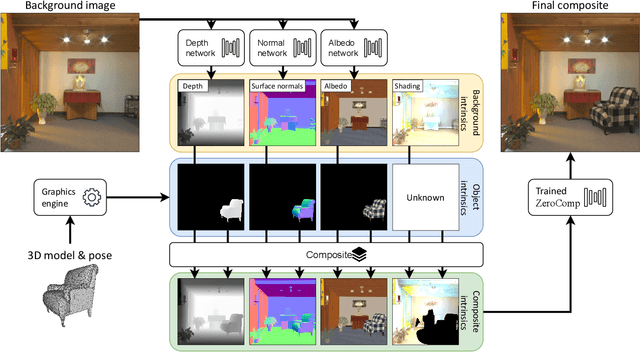
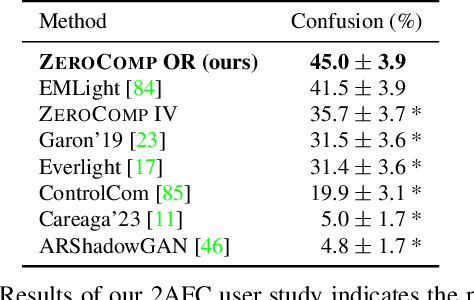

We present ZeroComp, an effective zero-shot 3D object compositing approach that does not require paired composite-scene images during training. Our method leverages ControlNet to condition from intrinsic images and combines it with a Stable Diffusion model to utilize its scene priors, together operating as an effective rendering engine. During training, ZeroComp uses intrinsic images based on geometry, albedo, and masked shading, all without the need for paired images of scenes with and without composite objects. Once trained, it seamlessly integrates virtual 3D objects into scenes, adjusting shading to create realistic composites. We developed a high-quality evaluation dataset and demonstrate that ZeroComp outperforms methods using explicit lighting estimations and generative techniques in quantitative and human perception benchmarks. Additionally, ZeroComp extends to real and outdoor image compositing, even when trained solely on synthetic indoor data, showcasing its effectiveness in image compositing.
CT Synthesis with Conditional Diffusion Models for Abdominal Lymph Node Segmentation
Mar 26, 2024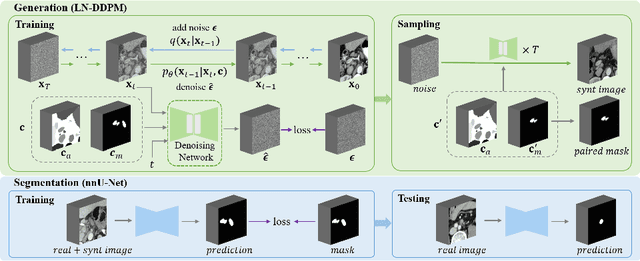
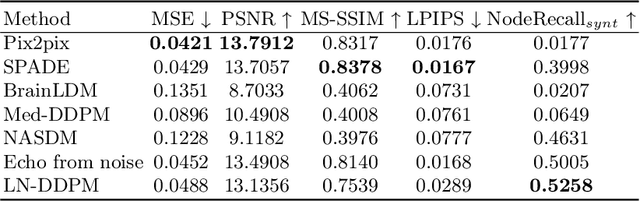
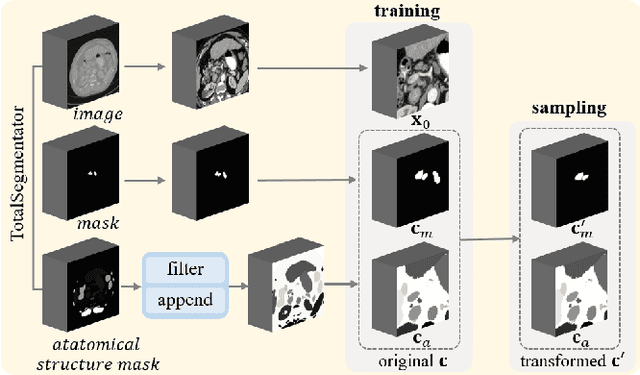
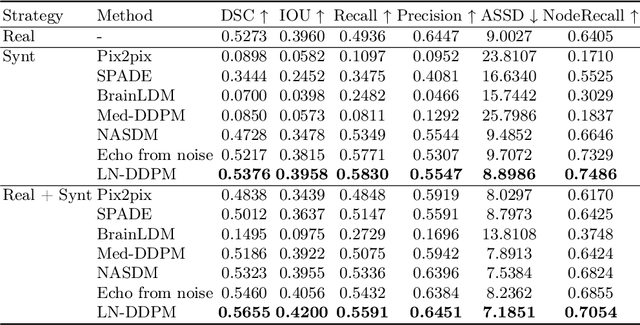
Despite the significant success achieved by deep learning methods in medical image segmentation, researchers still struggle in the computer-aided diagnosis of abdominal lymph nodes due to the complex abdominal environment, small and indistinguishable lesions, and limited annotated data. To address these problems, we present a pipeline that integrates the conditional diffusion model for lymph node generation and the nnU-Net model for lymph node segmentation to improve the segmentation performance of abdominal lymph nodes through synthesizing a diversity of realistic abdominal lymph node data. We propose LN-DDPM, a conditional denoising diffusion probabilistic model (DDPM) for lymph node (LN) generation. LN-DDPM utilizes lymph node masks and anatomical structure masks as model conditions. These conditions work in two conditioning mechanisms: global structure conditioning and local detail conditioning, to distinguish between lymph nodes and their surroundings and better capture lymph node characteristics. The obtained paired abdominal lymph node images and masks are used for the downstream segmentation task. Experimental results on the abdominal lymph node datasets demonstrate that LN-DDPM outperforms other generative methods in the abdominal lymph node image synthesis and better assists the downstream abdominal lymph node segmentation task.
Adaptive Modulation for Wobbling UAV Air-to-Ground Links in Millimeter-wave Bands
Apr 13, 2022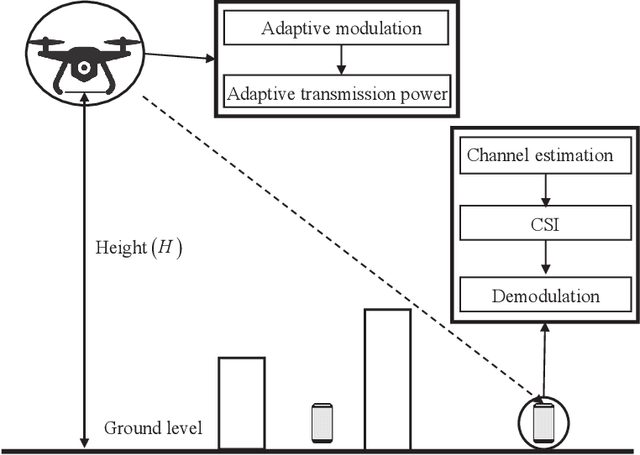
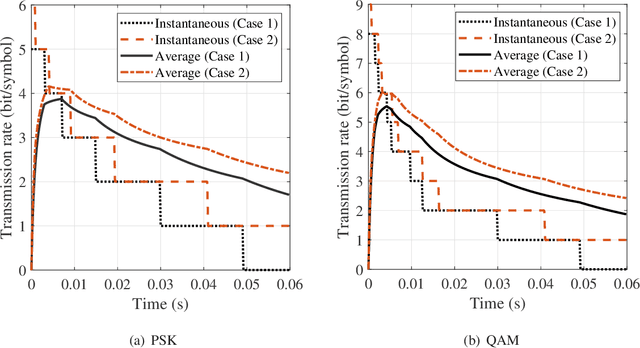
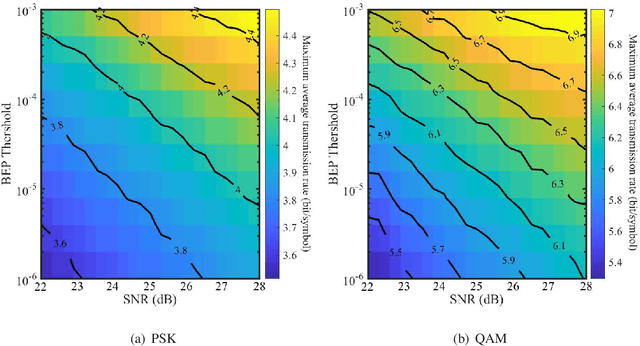
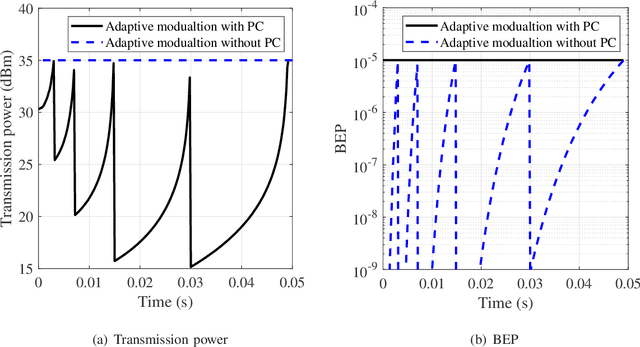
The emerging millimeter-wave (mm-wave) unmanned aerial vehicle (UAV) air-to-ground (A2G) communications are facing the Doppler effect problem that arises from the inevitable wobbling of the UAV. The fast time-varying channel for UAV A2G communications may lead to the outdated channel state information (CSI) from the channel estimation. In this paper, we introduce two detectors to demodulate the received signal and get the instantaneous bit error probability (BEP) of a mm-wave UAV A2G link under imperfect CSI. Based on the designed detectors, we propose an adaptive modulation scheme to maximize the average transmission rate under imperfect CSI by optimizing the data transmission time subject to the maximum tolerable BEP. A power control policy is in conjunction with adaptive modulation to minimize the transmission power while maintaining both the BEP under the threshold and the maximized average transmission rate. Numerical results show that the proposed adaptive modulation scheme in conjunction with the power control policy could maximize the temporally averaged transmission rate, while saves as much as 50\% energy.
Consistent Depth Prediction under Various Illuminations using Dilated Cross Attention
Dec 15, 2021

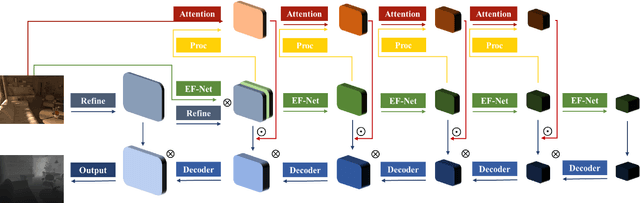
In this paper, we aim to solve the problem of consistent depth prediction in complex scenes under various illumination conditions. The existing indoor datasets based on RGB-D sensors or virtual rendering have two critical limitations - sparse depth maps (NYU Depth V2) and non-realistic illumination (SUN CG, SceneNet RGB-D). We propose to use internet 3D indoor scenes and manually tune their illuminations to render photo-realistic RGB photos and their corresponding depth and BRDF maps, obtaining a new indoor depth dataset called Vari dataset. We propose a simple convolutional block named DCA by applying depthwise separable dilated convolution on encoded features to process global information and reduce parameters. We perform cross attention on these dilated features to retain the consistency of depth prediction under different illuminations. Our method is evaluated by comparing it with current state-of-the-art methods on Vari dataset and a significant improvement is observed in our experiments. We also conduct the ablation study, finetune our model on NYU Depth V2 and also evaluate on real-world data to further validate the effectiveness of our DCA block. The code, pre-trained weights and Vari dataset are open-sourced.
Impact of Rotary-Wing UAV Wobbling on Millimeter-wave Air-to-Ground Wireless Channel
Jul 14, 2021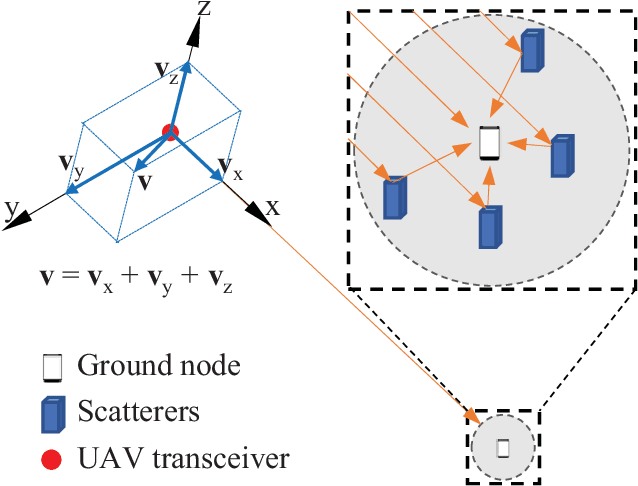
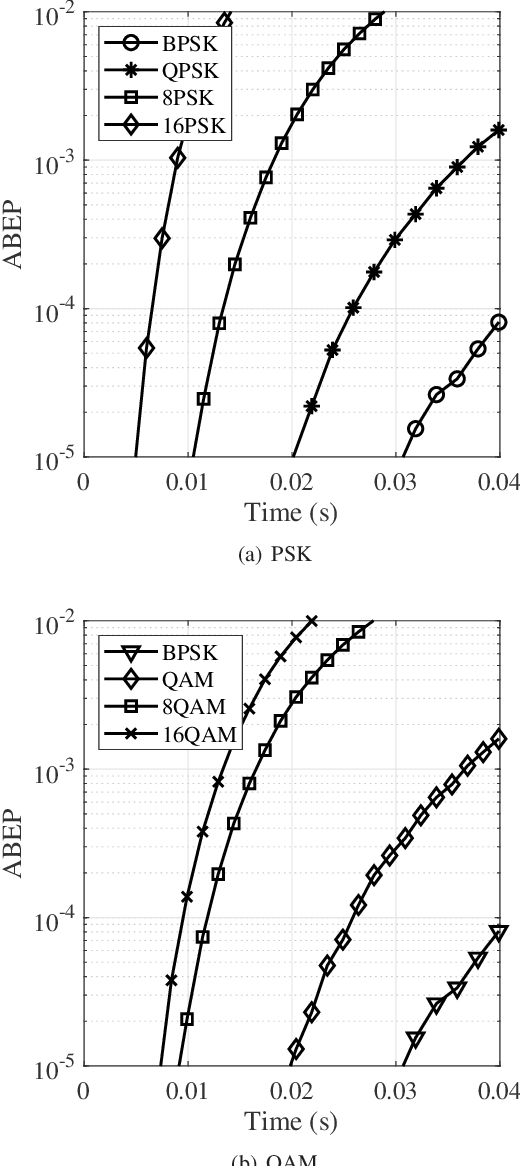
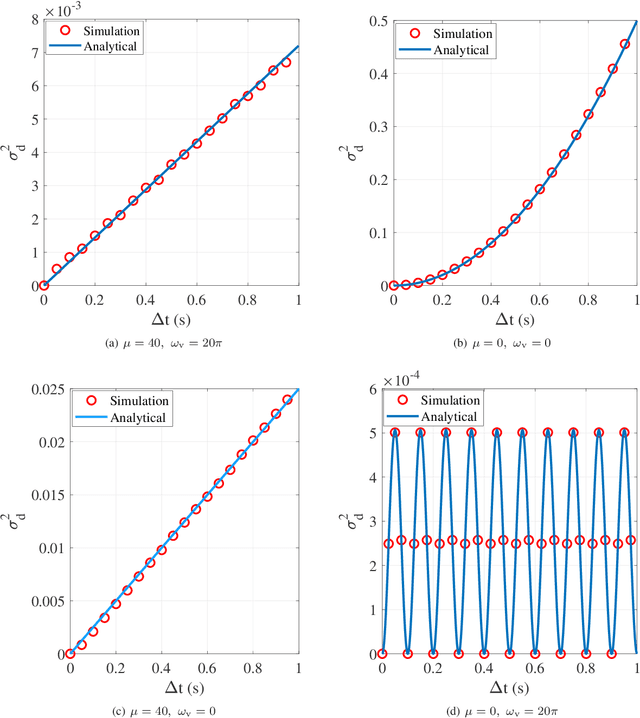
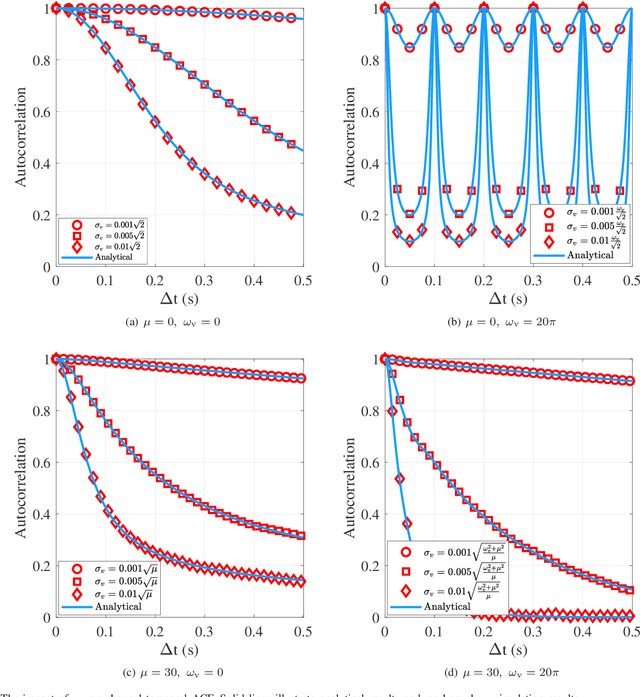
Millimeter-wave rotary-wing (RW) unmanned aerial vehicle (UAV) air-to-ground (A2G) links face unpredictable Doppler effect arising from the inevitable wobbling of RW UAV. Moreover, the time-varying channel characteristics during transmission lead to inaccurate channel estimation, which in turn results in the deteriorated bit error probability performance of the UAV A2G link. This paper studies the impact of mechanical wobbling on the Doppler effect of the millimeter-wave wireless channel between a hovering RW UAV and a ground node. Our contributions of this paper lie in: i) modeling the wobbling process of a hovering RW UAV; ii) developing an analytical model to derive the channel temporal autocorrelation function (ACF) for the millimeter-wave RW UAV A2G link in a closed-form expression; and iii) investigating how RW UAV wobbling impacts the Doppler effect on the millimeter-wave RW UAV A2G link. Numerical results show that different RW UAV wobbling patterns impact the amplitude and the frequency of ACF oscillation in the millimeter-wave RW UAV A2G link. For UAV wobbling, the channel temporal ACF decreases quickly and the impact of the Doppler effect is significant on the millimeter-wave A2G link.
Multi-Scale Progressive Fusion Learning for Depth Map Super-Resolution
Nov 24, 2020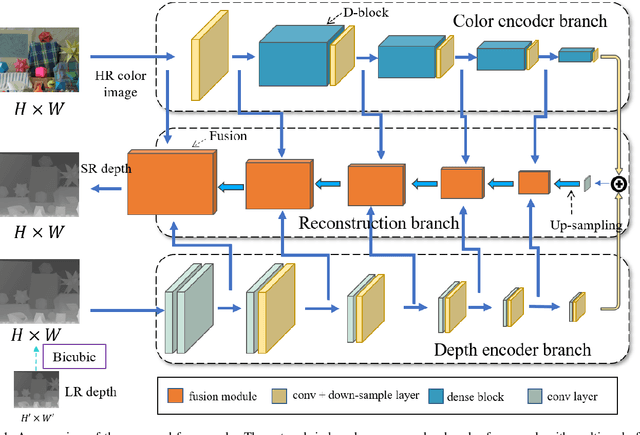
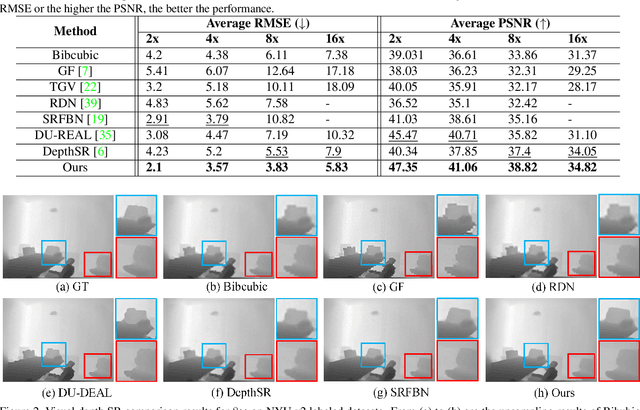


Limited by the cost and technology, the resolution of depth map collected by depth camera is often lower than that of its associated RGB camera. Although there have been many researches on RGB image super-resolution (SR), a major problem with depth map super-resolution is that there will be obvious jagged edges and excessive loss of details. To tackle these difficulties, in this work, we propose a multi-scale progressive fusion network for depth map SR, which possess an asymptotic structure to integrate hierarchical features in different domains. Given a low-resolution (LR) depth map and its associated high-resolution (HR) color image, We utilize two different branches to achieve multi-scale feature learning. Next, we propose a step-wise fusion strategy to restore the HR depth map. Finally, a multi-dimensional loss is introduced to constrain clear boundaries and details. Extensive experiments show that our proposed method produces improved results against state-of-the-art methods both qualitatively and quantitatively.