 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing User-Oriented Proactivity in Open-Domain Dialogues with Critic Guidance
May 18, 2025
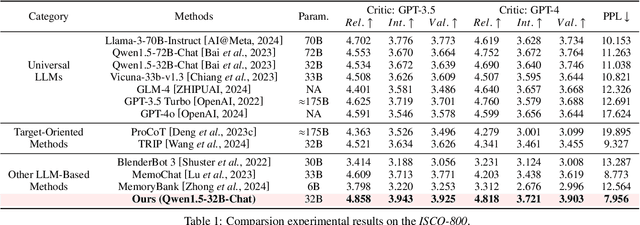
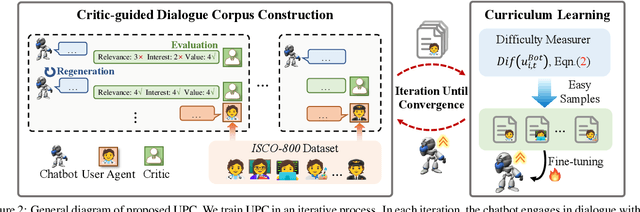

Open-domain dialogue systems aim to generate natural and engaging conversations, providing significant practical value in real applications such as social robotics and personal assistants. The advent of large language models (LLMs) has greatly advanced this field by improving context understanding and conversational fluency. However, existing LLM-based dialogue systems often fall short in proactively understanding the user's chatting preferences and guiding conversations toward user-centered topics. This lack of user-oriented proactivity can lead users to feel unappreciated, reducing their satisfaction and willingness to continue the conversation in human-computer interactions. To address this issue, we propose a User-oriented Proactive Chatbot (UPC) to enhance the user-oriented proactivity. Specifically, we first construct a critic to evaluate this proactivity inspired by the LLM-as-a-judge strategy. Given the scarcity of high-quality training data, we then employ the critic to guide dialogues between the chatbot and user agents, generating a corpus with enhanced user-oriented proactivity. To ensure the diversity of the user backgrounds, we introduce the ISCO-800, a diverse user background dataset for constructing user agents. Moreover, considering the communication difficulty varies among users, we propose an iterative curriculum learning method that trains the chatbot from easy-to-communicate users to more challenging ones, thereby gradually enhancing its performance. Experiments demonstrate that our proposed training method is applicable to different LLMs, improving user-oriented proactivity and attractiveness in open-domain dialogues.
Fine-Grained Alignment in Vision-and-Language Navigation through Bayesian Optimization
Nov 22, 2024



This paper addresses the challenge of fine-grained alignment in Vision-and-Language Navigation (VLN) tasks, where robots navigate realistic 3D environments based on natural language instructions. Current approaches use contrastive learning to align language with visual trajectory sequences. Nevertheless, they encounter difficulties with fine-grained vision negatives. To enhance cross-modal embeddings, we introduce a novel Bayesian Optimization-based adversarial optimization framework for creating fine-grained contrastive vision samples. To validate the proposed methodology, we conduct a series of experiments to assess the effectiveness of the enriched embeddings on fine-grained vision negatives. We conduct experiments on two common VLN benchmarks R2R and REVERIE, experiments on the them demonstrate that these embeddings benefit navigation, and can lead to a promising performance enhancement. Our source code and trained models are available at: https://anonymous.4open.science/r/FGVLN.
MAGIC: Map-Guided Few-Shot Audio-Visual Acoustics Modeling
May 22, 2024Few-shot audio-visual acoustics modeling seeks to synthesize the room impulse response in arbitrary locations with few-shot observations. To sufficiently exploit the provided few-shot data for accurate acoustic modeling, we present a *map-guided* framework by constructing acoustic-related visual semantic feature maps of the scenes. Visual features preserve semantic details related to sound and maps provide explicit structural regularities of sound propagation, which are valuable for modeling environment acoustics. We thus extract pixel-wise semantic features derived from observations and project them into a top-down map, namely the **observation semantic map**. This map contains the relative positional information among points and the semantic feature information associated with each point. Yet, limited information extracted by few-shot observations on the map is not sufficient for understanding and modeling the whole scene. We address the challenge by generating a **scene semantic map** via diffusing features and anticipating the observation semantic map. The scene semantic map then interacts with echo encoding by a transformer-based encoder-decoder to predict RIR for arbitrary speaker-listener query pairs. Extensive experiments on Matterport3D and Replica dataset verify the efficacy of our framework.
DCIR: Dynamic Consistency Intrinsic Reward for Multi-Agent Reinforcement Learning
Dec 10, 2023Learning optimal behavior policy for each agent in multi-agent systems is an essential yet difficult problem. Despite fruitful progress in multi-agent reinforcement learning, the challenge of addressing the dynamics of whether two agents should exhibit consistent behaviors is still under-explored. In this paper, we propose a new approach that enables agents to learn whether their behaviors should be consistent with that of other agents by utilizing intrinsic rewards to learn the optimal policy for each agent. We begin by defining behavior consistency as the divergence in output actions between two agents when provided with the same observation. Subsequently, we introduce dynamic consistency intrinsic reward (DCIR) to stimulate agents to be aware of others' behaviors and determine whether to be consistent with them. Lastly, we devise a dynamic scale network (DSN) that provides learnable scale factors for the agent at every time step to dynamically ascertain whether to award consistent behavior and the magnitude of rewards. We evaluate DCIR in multiple environments including Multi-agent Particle, Google Research Football and StarCraft II Micromanagement, demonstrating its efficacy.
Learning Vision-and-Language Navigation from YouTube Videos
Jul 22, 2023


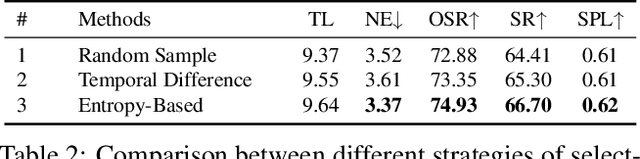
Vision-and-language navigation (VLN) requires an embodied agent to navigate in realistic 3D environments using natural language instructions. Existing VLN methods suffer from training on small-scale environments or unreasonable path-instruction datasets, limiting the generalization to unseen environments. There are massive house tour videos on YouTube, providing abundant real navigation experiences and layout information. However, these videos have not been explored for VLN before. In this paper, we propose to learn an agent from these videos by creating a large-scale dataset which comprises reasonable path-instruction pairs from house tour videos and pre-training the agent on it. To achieve this, we have to tackle the challenges of automatically constructing path-instruction pairs and exploiting real layout knowledge from raw and unlabeled videos. To address these, we first leverage an entropy-based method to construct the nodes of a path trajectory. Then, we propose an action-aware generator for generating instructions from unlabeled trajectories. Last, we devise a trajectory judgment pretext task to encourage the agent to mine the layout knowledge. Experimental results show that our method achieves state-of-the-art performance on two popular benchmarks (R2R and REVERIE). Code is available at https://github.com/JeremyLinky/YouTube-VLN
Instance Segmentation for Chinese Character Stroke Extraction, Datasets and Benchmarks
Oct 25, 2022



Stroke is the basic element of Chinese character and stroke extraction has been an important and long-standing endeavor. Existing stroke extraction methods are often handcrafted and highly depend on domain expertise due to the limited training data. Moreover, there are no standardized benchmarks to provide a fair comparison between different stroke extraction methods, which, we believe, is a major impediment to the development of Chinese character stroke understanding and related tasks. In this work, we present the first public available Chinese Character Stroke Extraction (CCSE) benchmark, with two new large-scale datasets: Kaiti CCSE (CCSE-Kai) and Handwritten CCSE (CCSE-HW). With the large-scale datasets, we hope to leverage the representation power of deep models such as CNNs to solve the stroke extraction task, which, however, remains an open question. To this end, we turn the stroke extraction problem into a stroke instance segmentation problem. Using the proposed datasets to train a stroke instance segmentation model, we surpass previous methods by a large margin. Moreover, the models trained with the proposed datasets benefit the downstream font generation and handwritten aesthetic assessment tasks. We hope these benchmark results can facilitate further research. The source code and datasets are publicly available at: https://github.com/lizhaoliu-Lec/CCSE.
Learning Active Camera for Multi-Object Navigation
Oct 14, 2022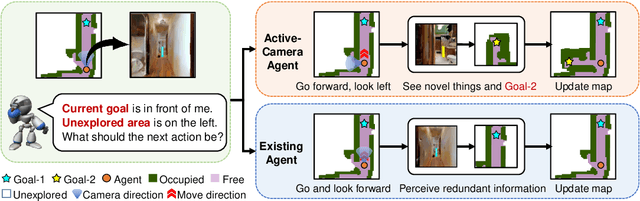
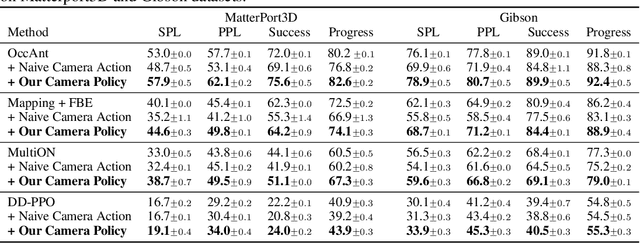
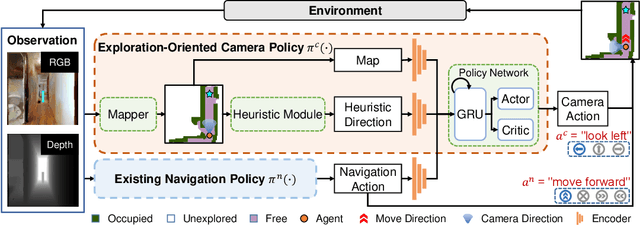
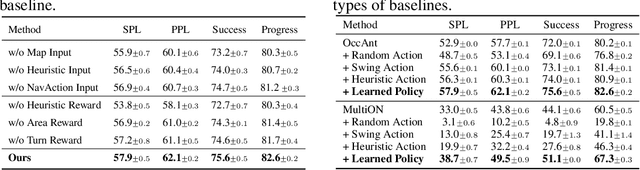
Getting robots to navigate to multiple objects autonomously is essential yet difficult in robot applications. One of the key challenges is how to explore environments efficiently with camera sensors only. Existing navigation methods mainly focus on fixed cameras and few attempts have been made to navigate with active cameras. As a result, the agent may take a very long time to perceive the environment due to limited camera scope. In contrast, humans typically gain a larger field of view by looking around for a better perception of the environment. How to make robots perceive the environment as efficiently as humans is a fundamental problem in robotics. In this paper, we consider navigating to multiple objects more efficiently with active cameras. Specifically, we cast moving camera to a Markov Decision Process and reformulate the active camera problem as a reinforcement learning problem. However, we have to address two new challenges: 1) how to learn a good camera policy in complex environments and 2) how to coordinate it with the navigation policy. To address these, we carefully design a reward function to encourage the agent to explore more areas by moving camera actively. Moreover, we exploit human experience to infer a rule-based camera action to guide the learning process. Last, to better coordinate two kinds of policies, the camera policy takes navigation actions into account when making camera moving decisions. Experimental results show our camera policy consistently improves the performance of multi-object navigation over four baselines on two datasets.
Weakly-Supervised Multi-Granularity Map Learning for Vision-and-Language Navigation
Oct 14, 2022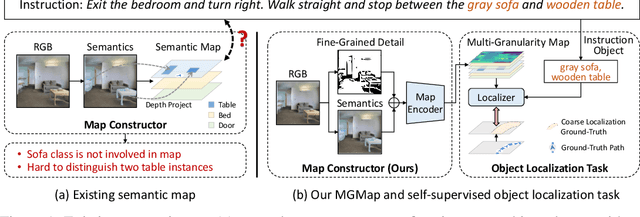
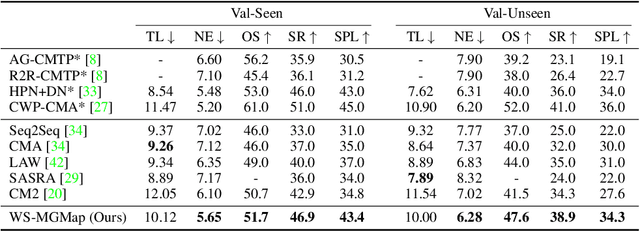
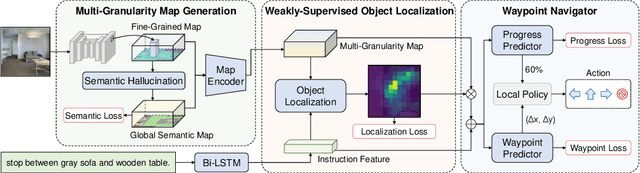
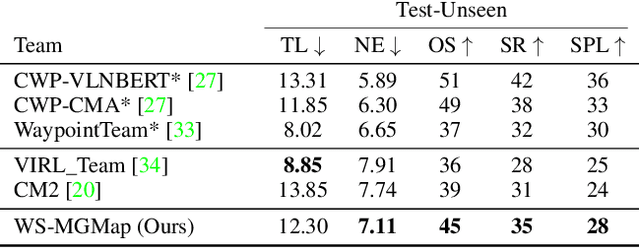
We address a practical yet challenging problem of training robot agents to navigate in an environment following a path described by some language instructions. The instructions often contain descriptions of objects in the environment. To achieve accurate and efficient navigation, it is critical to build a map that accurately represents both spatial location and the semantic information of the environment objects. However, enabling a robot to build a map that well represents the environment is extremely challenging as the environment often involves diverse objects with various attributes. In this paper, we propose a multi-granularity map, which contains both object fine-grained details (e.g., color, texture) and semantic classes, to represent objects more comprehensively. Moreover, we propose a weakly-supervised auxiliary task, which requires the agent to localize instruction-relevant objects on the map. Through this task, the agent not only learns to localize the instruction-relevant objects for navigation but also is encouraged to learn a better map representation that reveals object information. We then feed the learned map and instruction to a waypoint predictor to determine the next navigation goal. Experimental results show our method outperforms the state-of-the-art by 4.0% and 4.6% w.r.t. success rate both in seen and unseen environments, respectively on VLN-CE dataset. Code is available at https://github.com/PeihaoChen/WS-MGMap.