 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGIC: Map-Guided Few-Shot Audio-Visual Acoustics Modeling
May 22, 2024Few-shot audio-visual acoustics modeling seeks to synthesize the room impulse response in arbitrary locations with few-shot observations. To sufficiently exploit the provided few-shot data for accurate acoustic modeling, we present a *map-guided* framework by constructing acoustic-related visual semantic feature maps of the scenes. Visual features preserve semantic details related to sound and maps provide explicit structural regularities of sound propagation, which are valuable for modeling environment acoustics. We thus extract pixel-wise semantic features derived from observations and project them into a top-down map, namely the **observation semantic map**. This map contains the relative positional information among points and the semantic feature information associated with each point. Yet, limited information extracted by few-shot observations on the map is not sufficient for understanding and modeling the whole scene. We address the challenge by generating a **scene semantic map** via diffusing features and anticipating the observation semantic map. The scene semantic map then interacts with echo encoding by a transformer-based encoder-decoder to predict RIR for arbitrary speaker-listener query pairs. Extensive experiments on Matterport3D and Replica dataset verify the efficacy of our framework.
Learning Vision-and-Language Navigation from YouTube Videos
Jul 22, 2023


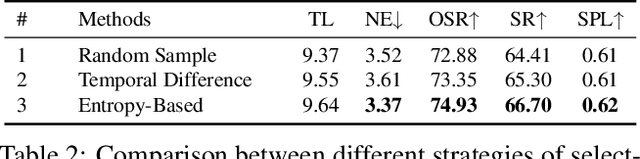
Vision-and-language navigation (VLN) requires an embodied agent to navigate in realistic 3D environments using natural language instructions. Existing VLN methods suffer from training on small-scale environments or unreasonable path-instruction datasets, limiting the generalization to unseen environments. There are massive house tour videos on YouTube, providing abundant real navigation experiences and layout information. However, these videos have not been explored for VLN before. In this paper, we propose to learn an agent from these videos by creating a large-scale dataset which comprises reasonable path-instruction pairs from house tour videos and pre-training the agent on it. To achieve this, we have to tackle the challenges of automatically constructing path-instruction pairs and exploiting real layout knowledge from raw and unlabeled videos. To address these, we first leverage an entropy-based method to construct the nodes of a path trajectory. Then, we propose an action-aware generator for generating instructions from unlabeled trajectories. Last, we devise a trajectory judgment pretext task to encourage the agent to mine the layout knowledge. Experimental results show that our method achieves state-of-the-art performance on two popular benchmarks (R2R and REVERIE). Code is available at https://github.com/JeremyLinky/YouTube-VLN