 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Model Scaling: Test-Time Intervention for Efficient Deep Reasoning
Jan 16, 2026Large Reasoning Models (LRMs) excel at multi-step reasoning but often suffer from inefficient reasoning processes like overthinking and overshoot, where excessive or misdirected reasoning increases computational cost and degrades performance. Existing efficient reasoning methods operate in a closed-loop manner, lacking mechanisms for external intervention to guide the reasoning process. To address this, we propose Think-with-Me, a novel test-time interactive reasoning paradigm that introduces external feedback intervention into the reasoning process. Our key insights are that transitional conjunctions serve as natural points for intervention, signaling phases of self-validation or exploration and using transitional words appropriately to prolong the reasoning enhances performance, while excessive use affects performance. Building on these insights, Think-with-Me pauses reasoning at these points for external feedback, adaptively extending or terminating reasoning to reduce redundancy while preserving accuracy. The feedback is generated via a multi-criteria evaluation (rationality and completeness) and comes from either human or LLM proxies. We train the target model using Group Relative Policy Optimization (GRPO) to adapt to this interactive mode. Experiments show that Think-with-Me achieves a superior balance between accuracy and reasoning length under limited context windows. On AIME24, Think-with-Me outperforms QwQ-32B by 7.19% in accuracy while reducing average reasoning length by 81% under an 8K window. The paradigm also benefits security and creative tasks.
Curse of High Dimensionality Issue in Transformer for Long-context Modeling
May 28, 2025Transformer-based large language models (LLMs) excel in natural language processing tasks by capturing long-range dependencies through self-attention mechanisms. However, long-context modeling faces significant computational inefficiencies due to \textit{redundant} attention computations: while attention weights are often \textit{sparse}, all tokens consume \textit{equal} computational resources. In this paper, we reformulate traditional probabilistic sequence modeling as a \textit{supervised learning task}, enabling the separation of relevant and irrelevant tokens and providing a clearer understanding of redundancy. Based on this reformulation, we theoretically analyze attention sparsity, revealing that only a few tokens significantly contribute to predictions. Building on this, we formulate attention optimization as a linear coding problem and propose a \textit{group coding strategy}, theoretically showing its ability to improve robustness against random noise and enhance learning efficiency. Motivated by this, we propose \textit{Dynamic Group Attention} (DGA), which leverages the group coding to explicitly reduce redundancy by aggregating less important tokens during attention computation. Empirical results show that our DGA significantly reduces computational costs while maintaining competitive performance.Code is available at https://github.com/bolixinyu/DynamicGroupAttention.
Enhancing User-Oriented Proactivity in Open-Domain Dialogues with Critic Guidance
May 18, 2025
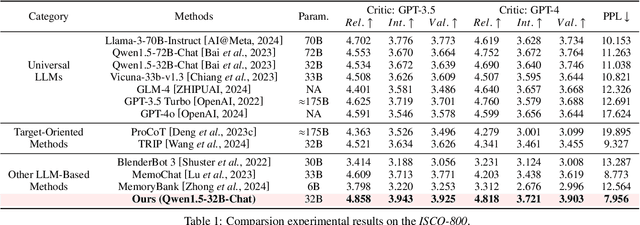
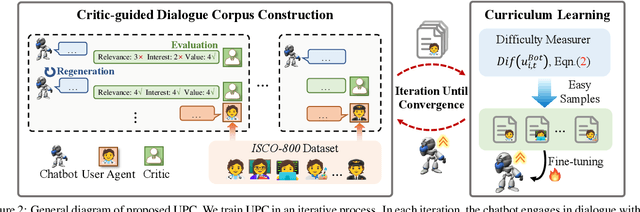

Open-domain dialogue systems aim to generate natural and engaging conversations, providing significant practical value in real applications such as social robotics and personal assistants. The advent of large language models (LLMs) has greatly advanced this field by improving context understanding and conversational fluency. However, existing LLM-based dialogue systems often fall short in proactively understanding the user's chatting preferences and guiding conversations toward user-centered topics. This lack of user-oriented proactivity can lead users to feel unappreciated, reducing their satisfaction and willingness to continue the conversation in human-computer interactions. To address this issue, we propose a User-oriented Proactive Chatbot (UPC) to enhance the user-oriented proactivity. Specifically, we first construct a critic to evaluate this proactivity inspired by the LLM-as-a-judge strategy. Given the scarcity of high-quality training data, we then employ the critic to guide dialogues between the chatbot and user agents, generating a corpus with enhanced user-oriented proactivity. To ensure the diversity of the user backgrounds, we introduce the ISCO-800, a diverse user background dataset for constructing user agents. Moreover, considering the communication difficulty varies among users, we propose an iterative curriculum learning method that trains the chatbot from easy-to-communicate users to more challenging ones, thereby gradually enhancing its performance. Experiments demonstrate that our proposed training method is applicable to different LLMs, improving user-oriented proactivity and attractiveness in open-domain dialogues.
Generating Long-form Story Using Dynamic Hierarchical Outlining with Memory-Enhancement
Dec 18, 2024Long-form story generation task aims to produce coherent and sufficiently lengthy text, essential for applications such as novel writingand interactive storytelling. However, existing methods, including LLMs, rely on rigid outlines or lack macro-level planning, making it difficult to achieve both contextual consistency and coherent plot development in long-form story generation. To address this issues, we propose Dynamic Hierarchical Outlining with Memory-Enhancement long-form story generation method, named DOME, to generate the long-form story with coherent content and plot. Specifically, the Dynamic Hierarchical Outline(DHO) mechanism incorporates the novel writing theory into outline planning and fuses the plan and writing stages together, improving the coherence of the plot by ensuring the plot completeness and adapting to the uncertainty during story generation. A Memory-Enhancement Module (MEM) based on temporal knowledge graphs is introduced to store and access the generated content, reducing contextual conflicts and improving story coherence. Finally, we propose a Temporal Conflict Analyzer leveraging temporal knowledge graphs to automatically evaluate the contextual consistency of long-form story. Experiments demonstrate that DOME significantly improves the fluency, coherence, and overall quality of generated long stories compared to state-of-the-art methods.