 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPNeRF: Open Vocabulary 3D Neural Scene Segmentation with Superpoints
Mar 19, 2025



Open-vocabulary segmentation, powered by large visual-language models like CLIP, has expanded 2D segmentation capabilities beyond fixed classes predefined by the dataset, enabling zero-shot understanding across diverse scenes. Extending these capabilities to 3D segmentation introduces challenges, as CLIP's image-based embeddings often lack the geometric detail necessary for 3D scene segmentation. Recent methods tend to address this by introducing additional segmentation models or replacing CLIP with variations trained on segmentation data, which lead to redundancy or loss on CLIP's general language capabilities. To overcome this limitation, we introduce SPNeRF, a NeRF based zero-shot 3D segmentation approach that leverages geometric priors. We integrate geometric primitives derived from the 3D scene into NeRF training to produce primitive-wise CLIP features, avoiding the ambiguity of point-wise features. Additionally, we propose a primitive-based merging mechanism enhanced with affinity scores. Without relying on additional segmentation models, our method further explores CLIP's capability for 3D segmentation and achieves notable improvements over original LERF.
Multi-View Mesh Reconstruction with Neural Deferred Shading
Dec 08, 2022



We propose an analysis-by-synthesis method for fast multi-view 3D reconstruction of opaque objects with arbitrary materials and illumination. State-of-the-art methods use both neural surface representations and neural rendering. While flexible, neural surface representations are a significant bottleneck in optimization runtime. Instead, we represent surfaces as triangle meshes and build a differentiable rendering pipeline around triangle rasterization and neural shading. The renderer is used in a gradient descent optimization where both a triangle mesh and a neural shader are jointly optimized to reproduce the multi-view images. We evaluate our method on a public 3D reconstruction dataset and show that it can match the reconstruction accuracy of traditional baselines and neural approaches while surpassing them in optimization runtime. Additionally, we investigate the shader and find that it learns an interpretable representation of appearance, enabling applications such as 3D material editing.
Learning Active Camera for Multi-Object Navigation
Oct 14, 2022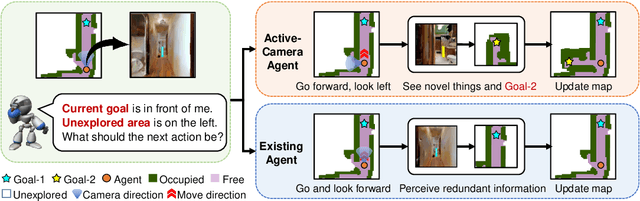
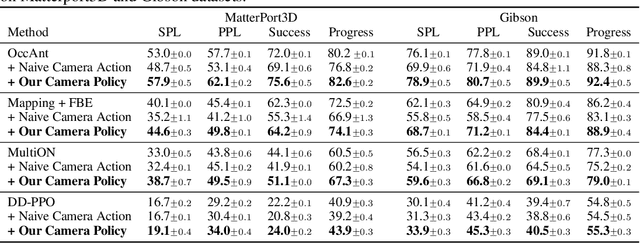
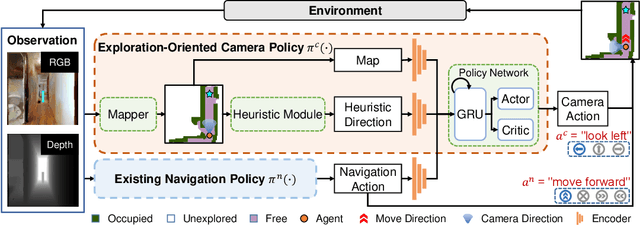
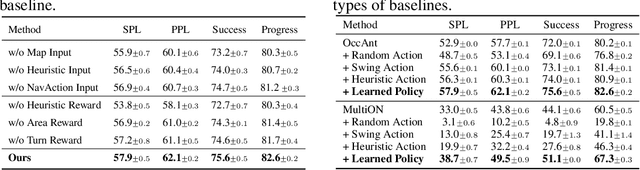
Getting robots to navigate to multiple objects autonomously is essential yet difficult in robot applications. One of the key challenges is how to explore environments efficiently with camera sensors only. Existing navigation methods mainly focus on fixed cameras and few attempts have been made to navigate with active cameras. As a result, the agent may take a very long time to perceive the environment due to limited camera scope. In contrast, humans typically gain a larger field of view by looking around for a better perception of the environment. How to make robots perceive the environment as efficiently as humans is a fundamental problem in robotics. In this paper, we consider navigating to multiple objects more efficiently with active cameras. Specifically, we cast moving camera to a Markov Decision Process and reformulate the active camera problem as a reinforcement learning problem. However, we have to address two new challenges: 1) how to learn a good camera policy in complex environments and 2) how to coordinate it with the navigation policy. To address these, we carefully design a reward function to encourage the agent to explore more areas by moving camera actively. Moreover, we exploit human experience to infer a rule-based camera action to guide the learning process. Last, to better coordinate two kinds of policies, the camera policy takes navigation actions into account when making camera moving decisions. Experimental results show our camera policy consistently improves the performance of multi-object navigation over four baselines on two datasets.
ASCNet: Self-supervised Video Representation Learning with Appearance-Speed Consistency
Jun 04, 2021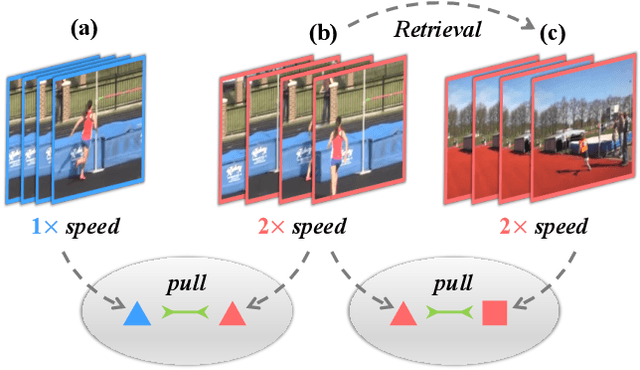

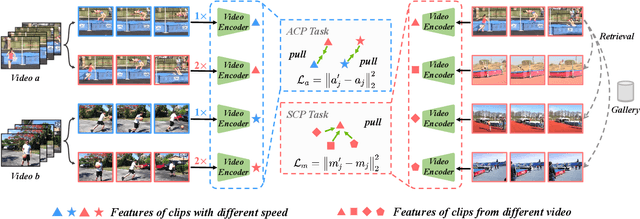

We study self-supervised video representation learning, which is a challenging task due to 1) a lack of labels for explicit supervision and 2) unstructured and noisy visual information. Existing methods mainly use contrastive loss with video clips as the instances and learn visual representation by discriminating instances from each other, but they require careful treatment of negative pairs by relying on large batch sizes, memory banks, extra modalities, or customized mining strategies, inevitably including noisy data. In this paper, we observe that the consistency between positive samples is the key to learn robust video representations. Specifically, we propose two tasks to learn the appearance and speed consistency, separately. The appearance consistency task aims to maximize the similarity between two clips of the same video with different playback speeds. The speed consistency task aims to maximize the similarity between two clips with the same playback speed but different appearance information. We show that joint optimization of the two tasks consistently improves the performance on downstream tasks, e.g., action recognition and video retrieval. Remarkably, for action recognition on the UCF-101 dataset, we achieve 90.8% accuracy without using any additional modalities or negative pairs for unsupervised pretraining, outperforming the ImageNet supervised pre-trained model. Codes and models will be available.