 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPNeRF: Open Vocabulary 3D Neural Scene Segmentation with Superpoints
Mar 19, 2025



Open-vocabulary segmentation, powered by large visual-language models like CLIP, has expanded 2D segmentation capabilities beyond fixed classes predefined by the dataset, enabling zero-shot understanding across diverse scenes. Extending these capabilities to 3D segmentation introduces challenges, as CLIP's image-based embeddings often lack the geometric detail necessary for 3D scene segmentation. Recent methods tend to address this by introducing additional segmentation models or replacing CLIP with variations trained on segmentation data, which lead to redundancy or loss on CLIP's general language capabilities. To overcome this limitation, we introduce SPNeRF, a NeRF based zero-shot 3D segmentation approach that leverages geometric priors. We integrate geometric primitives derived from the 3D scene into NeRF training to produce primitive-wise CLIP features, avoiding the ambiguity of point-wise features. Additionally, we propose a primitive-based merging mechanism enhanced with affinity scores. Without relying on additional segmentation models, our method further explores CLIP's capability for 3D segmentation and achieves notable improvements over original LERF.
Adaptive and Temporally Consistent Gaussian Surfels for Multi-view Dynamic Reconstruction
Nov 10, 20243D Gaussian Splatting has recently achieved notable success in novel view synthesis for dynamic scenes and geometry reconstruction in static scenes. Building on these advancements, early methods have been developed for dynamic surface reconstruction by globally optimizing entire sequences. However, reconstructing dynamic scenes with significant topology changes, emerging or disappearing objects, and rapid movements remains a substantial challenge, particularly for long sequences. To address these issues, we propose AT-GS, a novel method for reconstructing high-quality dynamic surfaces from multi-view videos through per-frame incremental optimization. To avoid local minima across frames, we introduce a unified and adaptive gradient-aware densification strategy that integrates the strengths of conventional cloning and splitting techniques. Additionally, we reduce temporal jittering in dynamic surfaces by ensuring consistency in curvature maps across consecutive frames. Our method achieves superior accuracy and temporal coherence in dynamic surface reconstruction, delivering high-fidelity space-time novel view synthesis, even in complex and challenging scenes. Extensive experiments on diverse multi-view video datasets demonstrate the effectiveness of our approach, showing clear advantages over baseline methods. Project page: \url{https://fraunhoferhhi.github.io/AT-GS}
Dynamic Multi-View Scene Reconstruction Using Neural Implicit Surface
Feb 28, 2023Reconstructing general dynamic scenes is important for many computer vision and graphics applications. Recent works represent the dynamic scene with neural radiance fields for photorealistic view synthesis, while their surface geometry is under-constrained and noisy. Other works introduce surface constraints to the implicit neural representation to disentangle the ambiguity of geometry and appearance field for static scene reconstruction. To bridge the gap between rendering dynamic scenes and recovering static surface geometry, we propose a template-free method to reconstruct surface geometry and appearance using neural implicit representations from multi-view videos. We leverage topology-aware deformation and the signed distance field to learn complex dynamic surfaces via differentiable volume rendering without scene-specific prior knowledge like template models. Furthermore, we propose a novel mask-based ray selection strategy to significantly boost the optimization on challenging time-varying regions. Experiments on different multi-view video datasets demonstrate that our method achieves high-fidelity surface reconstruction as well as photorealistic novel view synthesis.
Multi-View Mesh Reconstruction with Neural Deferred Shading
Dec 08, 2022



We propose an analysis-by-synthesis method for fast multi-view 3D reconstruction of opaque objects with arbitrary materials and illumination. State-of-the-art methods use both neural surface representations and neural rendering. While flexible, neural surface representations are a significant bottleneck in optimization runtime. Instead, we represent surfaces as triangle meshes and build a differentiable rendering pipeline around triangle rasterization and neural shading. The renderer is used in a gradient descent optimization where both a triangle mesh and a neural shader are jointly optimized to reproduce the multi-view images. We evaluate our method on a public 3D reconstruction dataset and show that it can match the reconstruction accuracy of traditional baselines and neural approaches while surpassing them in optimization runtime. Additionally, we investigate the shader and find that it learns an interpretable representation of appearance, enabling applications such as 3D material editing.
Recovering Fine Details for Neural Implicit Surface Reconstruction
Nov 21, 2022



Recent works on implicit neural representations have made significant strides. Learning implicit neural surfaces using volume rendering has gained popularity in multi-view reconstruction without 3D supervision. However, accurately recovering fine details is still challenging, due to the underlying ambiguity of geometry and appearance representation. In this paper, we present D-NeuS, a volume rendering-base neural implicit surface reconstruction method capable to recover fine geometry details, which extends NeuS by two additional loss functions targeting enhanced reconstruction quality. First, we encourage the rendered surface points from alpha compositing to have zero signed distance values, alleviating the geometry bias arising from transforming SDF to density for volume rendering. Second, we impose multi-view feature consistency on the surface points, derived by interpolating SDF zero-crossings from sampled points along rays. Extensive quantitative and qualitative results demonstrate that our method reconstructs high-accuracy surfaces with details, and outperforms the state of the art.
Accurate Human Body Reconstruction for Volumetric Video
Feb 26, 2022



In this work, we enhance a professional end-to-end volumetric video production pipeline to achieve high-fidelity human body reconstruction using only passive cameras. While current volumetric video approaches estimate depth maps using traditional stereo matching techniques, we introduce and optimize deep learning-based multi-view stereo networks for depth map estimation in the context of professional volumetric video reconstruction. Furthermore, we propose a novel depth map post-processing approach including filtering and fusion, by taking into account photometric confidence, cross-view geometric consistency, foreground masks as well as camera viewing frustums. We show that our method can generate high levels of geometric detail for reconstructed human bodies.
Going beyond Free Viewpoint: Creating Animatable Volumetric Video of Human Performances
Sep 02, 2020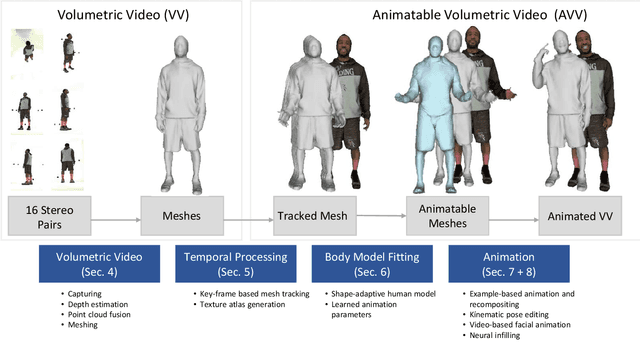

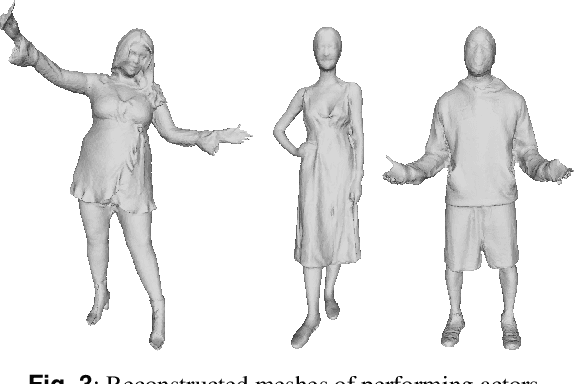
In this paper, we present an end-to-end pipeline for the creation of high-quality animatable volumetric video content of human performances. Going beyond the application of free-viewpoint volumetric video, we allow re-animation and alteration of an actor's performance through (i) the enrichment of the captured data with semantics and animation properties and (ii) applying hybrid geometry- and video-based animation methods that allow a direct animation of the high-quality data itself instead of creating an animatable model that resembles the captured data. Semantic enrichment and geometric animation ability are achieved by establishing temporal consistency in the 3D data, followed by an automatic rigging of each frame using a parametric shape-adaptive full human body model. Our hybrid geometry- and video-based animation approaches combine the flexibility of classical CG animation with the realism of real captured data. For pose editing, we exploit the captured data as much as possible and kinematically deform the captured frames to fit a desired pose. Further, we treat the face differently from the body in a hybrid geometry- and video-based animation approach where coarse movements and poses are modeled in the geometry only, while very fine and subtle details in the face, often lacking in purely geometric methods, are captured in video-based textures. These are processed to be interactively combined to form new facial expressions. On top of that, we learn the appearance of regions that are challenging to synthesize, such as the teeth or the eyes, and fill in missing regions realistically in an autoencoder-based approach. This paper covers the full pipeline from capturing and producing high-quality video content, over the enrichment with semantics and deformation properties for re-animation and processing of the data for the final hybrid animation.