 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR3GW: Relightable 3D Gaussians for Outdoor Scenes in the Wild
Mar 03, 20263D Gaussian Splatting (3DGS) has established itself as a leading technique for 3D reconstruction and novel view synthesis of static scenes, achieving outstanding rendering quality and fast training. However, the method does not explicitly model the scene illumination, making it unsuitable for relighting tasks. Furthermore, 3DGS struggles to reconstruct scenes captured in the wild by unconstrained photo collections featuring changing lighting conditions. In this paper, we present R3GW, a novel method that learns a relightable 3DGS representation of an outdoor scene captured in the wild. Our approach separates the scene into a relightable foreground and a non-reflective background (the sky), using two distinct sets of Gaussians. R3GW models view-dependent lighting effects in the foreground reflections by combining Physically Based Rendering with the 3DGS scene representation in a varying illumination setting. We evaluate our method quantitatively and qualitatively on the NeRF-OSR dataset, offering state-of-the-art performance and enhanced support for physically-based relighting of unconstrained scenes. Our method synthesizes photorealistic novel views under arbitrary illumination conditions. Additionally, our representation of the sky mitigates depth reconstruction artifacts, improving rendering quality at the sky-foreground boundary
* Accepted at VISAPP 2026
CGS-GAN: 3D Consistent Gaussian Splatting GANs for High Resolution Human Head Synthesis
May 23, 2025



Recently, 3D GANs based on 3D Gaussian splatting have been proposed for high quality synthesis of human heads. However, existing methods stabilize training and enhance rendering quality from steep viewpoints by conditioning the random latent vector on the current camera position. This compromises 3D consistency, as we observe significant identity changes when re-synthesizing the 3D head with each camera shift. Conversely, fixing the camera to a single viewpoint yields high-quality renderings for that perspective but results in poor performance for novel views. Removing view-conditioning typically destabilizes GAN training, often causing the training to collapse. In response to these challenges, we introduce CGS-GAN, a novel 3D Gaussian Splatting GAN framework that enables stable training and high-quality 3D-consistent synthesis of human heads without relying on view-conditioning. To ensure training stability, we introduce a multi-view regularization technique that enhances generator convergence with minimal computational overhead. Additionally, we adapt the conditional loss used in existing 3D Gaussian splatting GANs and propose a generator architecture designed to not only stabilize training but also facilitate efficient rendering and straightforward scaling, enabling output resolutions up to $2048^2$. To evaluate the capabilities of CGS-GAN, we curate a new dataset derived from FFHQ. This dataset enables very high resolutions, focuses on larger portions of the human head, reduces view-dependent artifacts for improved 3D consistency, and excludes images where subjects are obscured by hands or other objects. As a result, our approach achieves very high rendering quality, supported by competitive FID scores, while ensuring consistent 3D scene generation. Check our our project page here: https://fraunhoferhhi.github.io/cgs-gan/
Gaussian Splatting Decoder for 3D-aware Generative Adversarial Networks
Apr 16, 2024
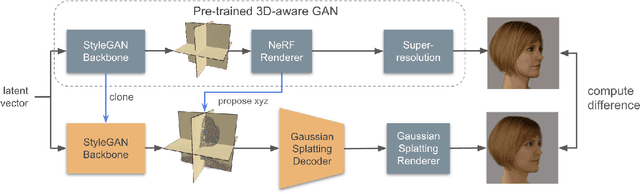
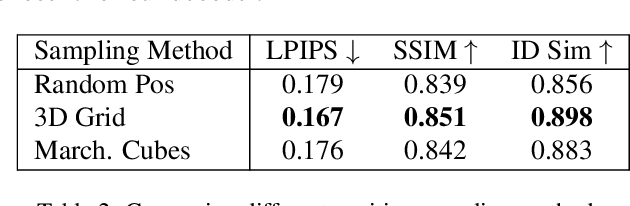
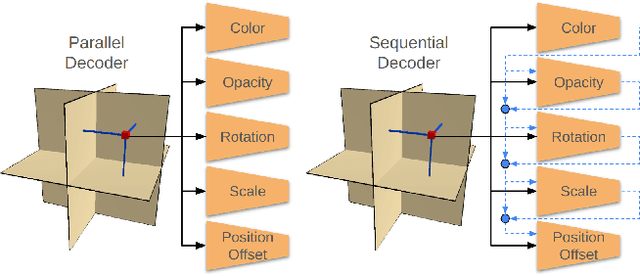
NeRF-based 3D-aware Generative Adversarial Networks (GANs) like EG3D or GIRAFFE have shown very high rendering quality under large representational variety. However, rendering with Neural Radiance Fields poses challenges for 3D applications: First, the significant computational demands of NeRF rendering preclude its use on low-power devices, such as mobiles and VR/AR headsets. Second, implicit representations based on neural networks are difficult to incorporate into explicit 3D scenes, such as VR environments or video games. 3D Gaussian Splatting (3DGS) overcomes these limitations by providing an explicit 3D representation that can be rendered efficiently at high frame rates. In this work, we present a novel approach that combines the high rendering quality of NeRF-based 3D-aware GANs with the flexibility and computational advantages of 3DGS. By training a decoder that maps implicit NeRF representations to explicit 3D Gaussian Splatting attributes, we can integrate the representational diversity and quality of 3D GANs into the ecosystem of 3D Gaussian Splatting for the first time. Additionally, our approach allows for a high resolution GAN inversion and real-time GAN editing with 3D Gaussian Splatting scenes.
X-maps: Direct Depth Lookup for Event-based Structured Light Systems
Feb 15, 2024

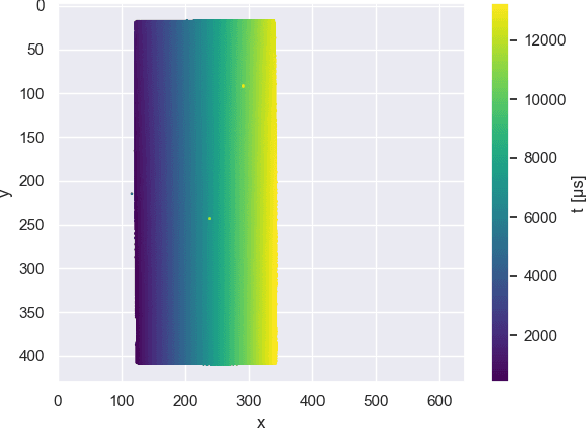
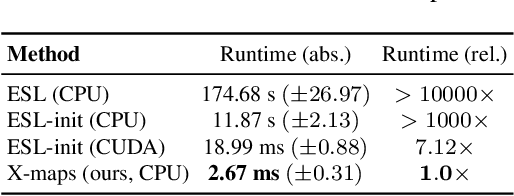
We present a new approach to direct depth estimation for Spatial Augmented Reality (SAR) applications using event cameras. These dynamic vision sensors are a great fit to be paired with laser projectors for depth estimation in a structured light approach. Our key contributions involve a conversion of the projector time map into a rectified X-map, capturing x-axis correspondences for incoming events and enabling direct disparity lookup without any additional search. Compared to previous implementations, this significantly simplifies depth estimation, making it more efficient, while the accuracy is similar to the time map-based process. Moreover, we compensate non-linear temporal behavior of cheap laser projectors by a simple time map calibration, resulting in improved performance and increased depth estimation accuracy. Since depth estimation is executed by two lookups only, it can be executed almost instantly (less than 3 ms per frame with a Python implementation) for incoming events. This allows for real-time interactivity and responsiveness, which makes our approach especially suitable for SAR experiences where low latency, high frame rates and direct feedback are crucial. We present valuable insights gained into data transformed into X-maps and evaluate our depth from disparity estimation against the state of the art time map-based results. Additional results and code are available on our project page: https://fraunhoferhhi.github.io/X-maps/
* Accepted at the CVPR 2023 Workshop on Event-based Vision: https://tub-rip.github.io/eventvision2023/
Compact 3D Scene Representation via Self-Organizing Gaussian Grids
Dec 19, 20233D Gaussian Splatting has recently emerged as a highly promising technique for modeling of static 3D scenes. In contrast to Neural Radiance Fields, it utilizes efficient rasterization allowing for very fast rendering at high-quality. However, the storage size is significantly higher, which hinders practical deployment, e.g.~on resource constrained devices. In this paper, we introduce a compact scene representation organizing the parameters of 3D Gaussian Splatting (3DGS) into a 2D grid with local homogeneity, ensuring a drastic reduction in storage requirements without compromising visual quality during rendering. Central to our idea is the explicit exploitation of perceptual redundancies present in natural scenes. In essence, the inherent nature of a scene allows for numerous permutations of Gaussian parameters to equivalently represent it. To this end, we propose a novel highly parallel algorithm that regularly arranges the high-dimensional Gaussian parameters into a 2D grid while preserving their neighborhood structure. During training, we further enforce local smoothness between the sorted parameters in the grid. The uncompressed Gaussians use the same structure as 3DGS, ensuring a seamless integration with established renderers. Our method achieves a reduction factor of 8x to 26x in size for complex scenes with no increase in training time, marking a substantial leap forward in the domain of 3D scene distribution and consumption. Additional information can be found on our project page: https://fraunhoferhhi.github.io/Self-Organizing-Gaussians/
Animating NeRFs from Texture Space: A Framework for Pose-Dependent Rendering of Human Performances
Nov 06, 2023
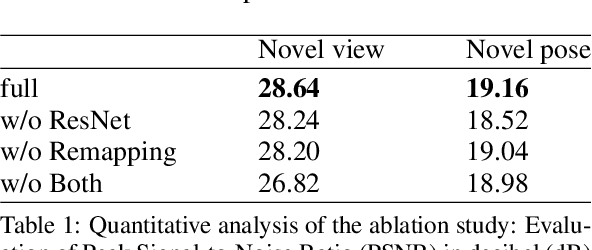
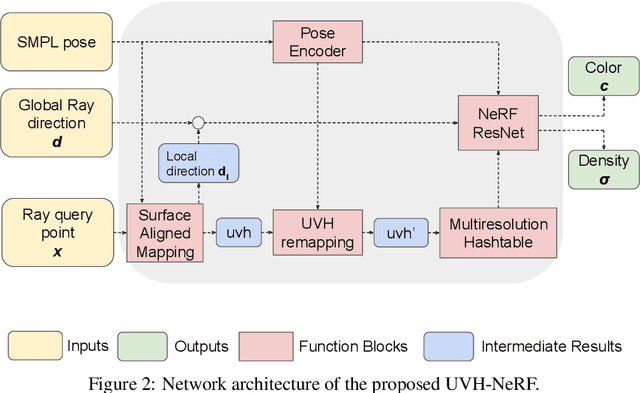
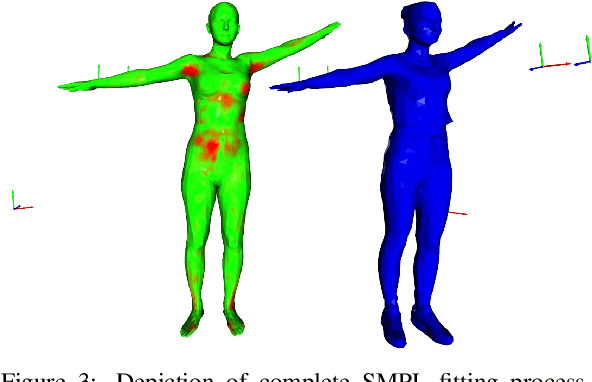
Creating high-quality controllable 3D human models from multi-view RGB videos poses a significant challenge. Neural radiance fields (NeRFs) have demonstrated remarkable quality in reconstructing and free-viewpoint rendering of static as well as dynamic scenes. The extension to a controllable synthesis of dynamic human performances poses an exciting research question. In this paper, we introduce a novel NeRF-based framework for pose-dependent rendering of human performances. In our approach, the radiance field is warped around an SMPL body mesh, thereby creating a new surface-aligned representation. Our representation can be animated through skeletal joint parameters that are provided to the NeRF in addition to the viewpoint for pose dependent appearances. To achieve this, our representation includes the corresponding 2D UV coordinates on the mesh texture map and the distance between the query point and the mesh. To enable efficient learning despite mapping ambiguities and random visual variations, we introduce a novel remapping process that refines the mapped coordinates. Experiments demonstrate that our approach results in high-quality renderings for novel-view and novel-pose synthesis.
Animatable Virtual Humans: Learning pose-dependent human representations in UV space for interactive performance synthesis
Oct 05, 2023



We propose a novel representation of virtual humans for highly realistic real-time animation and rendering in 3D applications. We learn pose dependent appearance and geometry from highly accurate dynamic mesh sequences obtained from state-of-the-art multiview-video reconstruction. Learning pose-dependent appearance and geometry from mesh sequences poses significant challenges, as it requires the network to learn the intricate shape and articulated motion of a human body. However, statistical body models like SMPL provide valuable a-priori knowledge which we leverage in order to constrain the dimension of the search space enabling more efficient and targeted learning and define pose-dependency. Instead of directly learning absolute pose-dependent geometry, we learn the difference between the observed geometry and the fitted SMPL model. This allows us to encode both pose-dependent appearance and geometry in the consistent UV space of the SMPL model. This approach not only ensures a high level of realism but also facilitates streamlined processing and rendering of virtual humans in real-time scenarios.
Imposing Temporal Consistency on Deep Monocular Body Shape and Pose Estimation
Feb 08, 2022Accurate and temporally consistent modeling of human bodies is essential for a wide range of applications, including character animation, understanding human social behavior and AR/VR interfaces. Capturing human motion accurately from a monocular image sequence is still challenging and the modeling quality is strongly influenced by the temporal consistency of the captured body motion. Our work presents an elegant solution for the integration of temporal constraints in the fitting process. This does not only increase temporal consistency but also robustness during the optimization. In detail, we derive parameters of a sequence of body models, representing shape and motion of a person, including jaw poses, facial expressions, and finger poses. We optimize these parameters over the complete image sequence, fitting one consistent body shape while imposing temporal consistency on the body motion, assuming linear body joint trajectories over a short time. Our approach enables the derivation of realistic 3D body models from image sequences, including facial expression and articulated hands. In extensive experiments, we show that our approach results in accurately estimated body shape and motion, also for challenging movements and poses. Further, we apply it to the special application of sign language analysis, where accurate and temporal consistent motion modelling is essential, and show that the approach is well-suited for this kind of application.
Going beyond Free Viewpoint: Creating Animatable Volumetric Video of Human Performances
Sep 02, 2020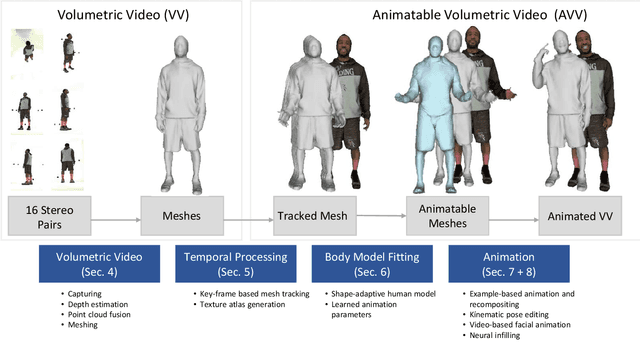

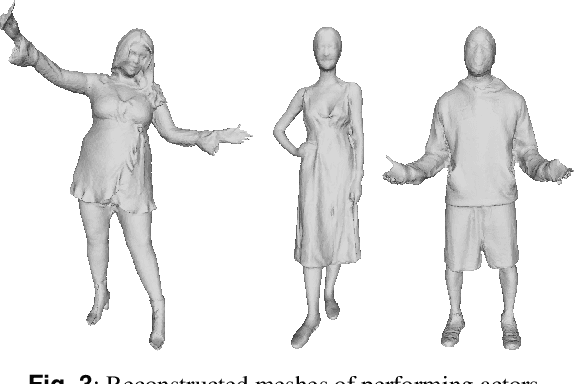
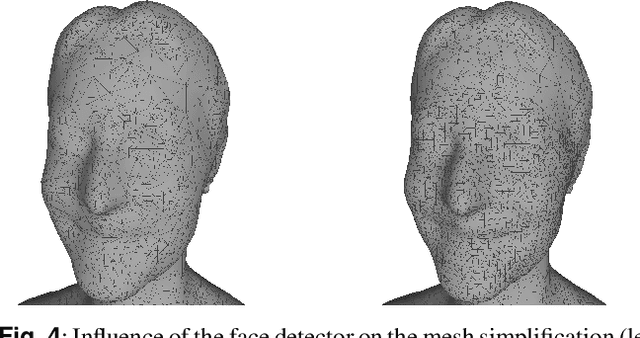
In this paper, we present an end-to-end pipeline for the creation of high-quality animatable volumetric video content of human performances. Going beyond the application of free-viewpoint volumetric video, we allow re-animation and alteration of an actor's performance through (i) the enrichment of the captured data with semantics and animation properties and (ii) applying hybrid geometry- and video-based animation methods that allow a direct animation of the high-quality data itself instead of creating an animatable model that resembles the captured data. Semantic enrichment and geometric animation ability are achieved by establishing temporal consistency in the 3D data, followed by an automatic rigging of each frame using a parametric shape-adaptive full human body model. Our hybrid geometry- and video-based animation approaches combine the flexibility of classical CG animation with the realism of real captured data. For pose editing, we exploit the captured data as much as possible and kinematically deform the captured frames to fit a desired pose. Further, we treat the face differently from the body in a hybrid geometry- and video-based animation approach where coarse movements and poses are modeled in the geometry only, while very fine and subtle details in the face, often lacking in purely geometric methods, are captured in video-based textures. These are processed to be interactively combined to form new facial expressions. On top of that, we learn the appearance of regions that are challenging to synthesize, such as the teeth or the eyes, and fill in missing regions realistically in an autoencoder-based approach. This paper covers the full pipeline from capturing and producing high-quality video content, over the enrichment with semantics and deformation properties for re-animation and processing of the data for the final hybrid animation.