 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Drywall Analysis for Progress Tracking and Quality Control in Construction
Mar 05, 2025



Digitalization in the construction industry has become essential, enabling centralized, easy access to all relevant information of a building. Automated systems can facilitate the timely and resource-efficient documentation of changes, which is crucial for key processes such as progress tracking and quality control. This paper presents a method for image-based automated drywall analysis enabling construction progress and quality assessment through on-site camera systems. Our proposed solution integrates a deep learning-based instance segmentation model to detect and classify various drywall elements with an analysis module to cluster individual wall segments, estimate camera perspective distortions, and apply the corresponding corrections. This system extracts valuable information from images, enabling more accurate progress tracking and quality assessment on construction sites. Our main contributions include a fully automated pipeline for drywall analysis, improving instance segmentation accuracy through architecture modifications and targeted data augmentation, and a novel algorithm to extract important information from the segmentation results. Our modified model, enhanced with data augmentation, achieves significantly higher accuracy compared to other architectures, offering more detailed and precise information than existing approaches. Combined with the proposed drywall analysis steps, it enables the reliable automation of construction progress and quality assessment.
SPVLoc: Semantic Panoramic Viewport Matching for 6D Camera Localization in Unseen Environments
Apr 16, 2024In this paper, we present SPVLoc, a global indoor localization method that accurately determines the six-dimensional (6D) camera pose of a query image and requires minimal scene-specific prior knowledge and no scene-specific training. Our approach employs a novel matching procedure to localize the perspective camera's viewport, given as an RGB image, within a set of panoramic semantic layout representations of the indoor environment. The panoramas are rendered from an untextured 3D reference model, which only comprises approximate structural information about room shapes, along with door and window annotations. We demonstrate that a straightforward convolutional network structure can successfully achieve image-to-panorama and ultimately image-to-model matching. Through a viewport classification score, we rank reference panoramas and select the best match for the query image. Then, a 6D relative pose is estimated between the chosen panorama and query image. Our experiments demonstrate that this approach not only efficiently bridges the domain gap but also generalizes well to previously unseen scenes that are not part of the training data. Moreover, it achieves superior localization accuracy compared to the state of the art methods and also estimates more degrees of freedom of the camera pose. We will make our source code publicly available at https://github.com/fraunhoferhhi/spvloc .
X-maps: Direct Depth Lookup for Event-based Structured Light Systems
Feb 15, 2024

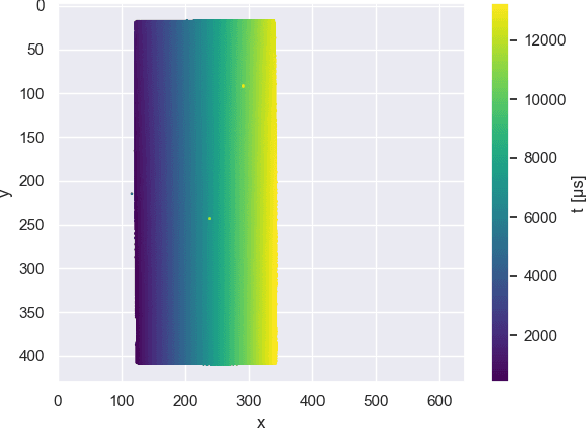
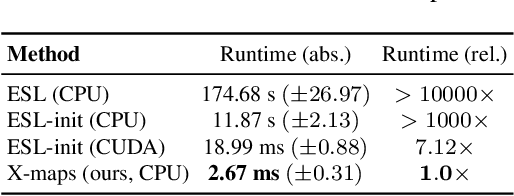
We present a new approach to direct depth estimation for Spatial Augmented Reality (SAR) applications using event cameras. These dynamic vision sensors are a great fit to be paired with laser projectors for depth estimation in a structured light approach. Our key contributions involve a conversion of the projector time map into a rectified X-map, capturing x-axis correspondences for incoming events and enabling direct disparity lookup without any additional search. Compared to previous implementations, this significantly simplifies depth estimation, making it more efficient, while the accuracy is similar to the time map-based process. Moreover, we compensate non-linear temporal behavior of cheap laser projectors by a simple time map calibration, resulting in improved performance and increased depth estimation accuracy. Since depth estimation is executed by two lookups only, it can be executed almost instantly (less than 3 ms per frame with a Python implementation) for incoming events. This allows for real-time interactivity and responsiveness, which makes our approach especially suitable for SAR experiences where low latency, high frame rates and direct feedback are crucial. We present valuable insights gained into data transformed into X-maps and evaluate our depth from disparity estimation against the state of the art time map-based results. Additional results and code are available on our project page: https://fraunhoferhhi.github.io/X-maps/
* Accepted at the CVPR 2023 Workshop on Event-based Vision: https://tub-rip.github.io/eventvision2023/
CASAPose: Class-Adaptive and Semantic-Aware Multi-Object Pose Estimation
Oct 11, 2022



Applications in the field of augmented reality or robotics often require joint localisation and 6d pose estimation of multiple objects. However, most algorithms need one network per object class to be trained in order to provide the best results. Analysing all visible objects demands multiple inferences, which is memory and time-consuming. We present a new single-stage architecture called CASAPose that determines 2D-3D correspondences for pose estimation of multiple different objects in RGB images in one pass. It is fast and memory efficient, and achieves high accuracy for multiple objects by exploiting the output of a semantic segmentation decoder as control input to a keypoint recognition decoder via local class-adaptive normalisation. Our new differentiable regression of keypoint locations significantly contributes to a faster closing of the domain gap between real test and synthetic training data. We apply segmentation-aware convolutions and upsampling operations to increase the focus inside the object mask and to reduce mutual interference of occluding objects. For each inserted object, the network grows by only one output segmentation map and a negligible number of parameters. We outperform state-of-the-art approaches in challenging multi-object scenes with inter-object occlusion and synthetic training.
Combining Local and Global Pose Estimation for Precise Tracking of Similar Objects
Jan 31, 2022
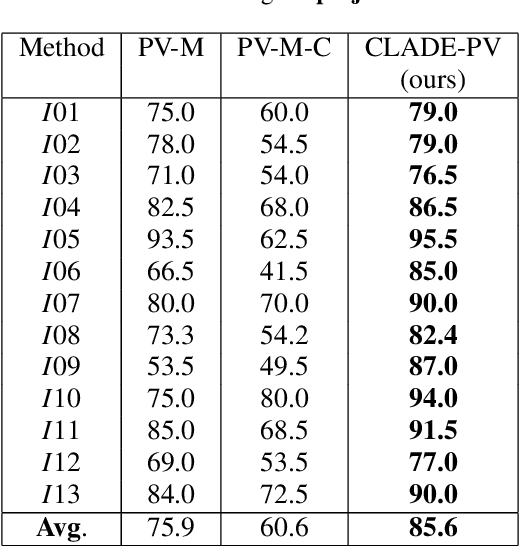


In this paper, we present a multi-object 6D detection and tracking pipeline for potentially similar and non-textured objects. The combination of a convolutional neural network for object classification and rough pose estimation with a local pose refinement and an automatic mismatch detection enables direct application in real-time AR scenarios. A new network architecture, trained solely with synthetic images, allows simultaneous pose estimation of multiple objects with reduced GPU memory consumption and enhanced performance. In addition, the pose estimates are further improved by a local edge-based refinement step that explicitly exploits known object geometry information. For continuous movements, the sole use of local refinement reduces pose mismatches due to geometric ambiguities or occlusions. We showcase the entire tracking pipeline and demonstrate the benefits of the combined approach. Experiments on a challenging set of non-textured similar objects demonstrate the enhanced quality compared to the baseline method. Finally, we illustrate how the system can be used in a real AR assistance application within the field of construction.
Zero in on Shape: A Generic 2D-3D Instance Similarity Metric learned from Synthetic Data
Aug 09, 2021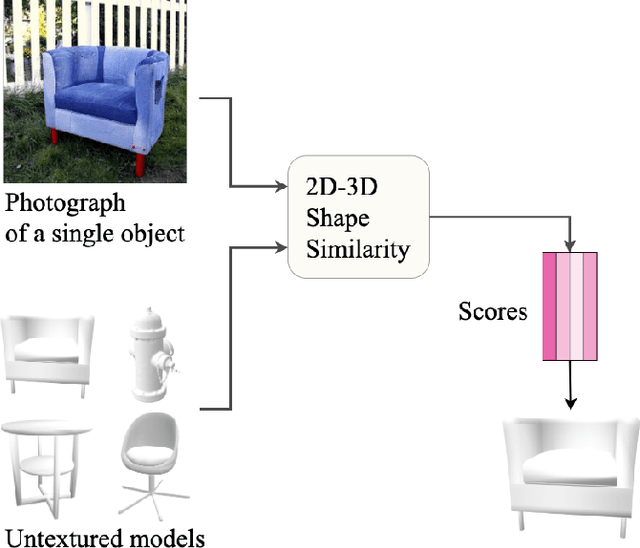

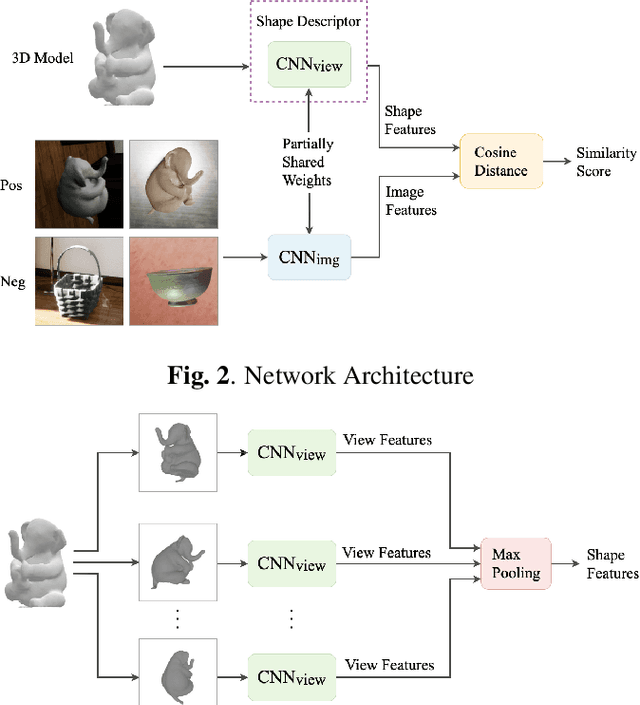
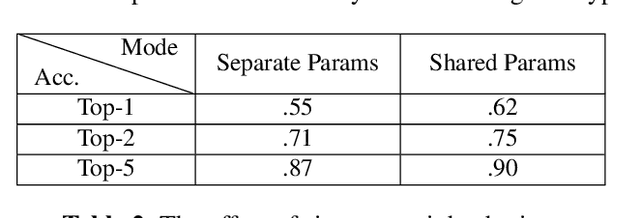
We present a network architecture which compares RGB images and untextured 3D models by the similarity of the represented shape. Our system is optimised for zero-shot retrieval, meaning it can recognise shapes never shown in training. We use a view-based shape descriptor and a siamese network to learn object geometry from pairs of 3D models and 2D images. Due to scarcity of datasets with exact photograph-mesh correspondences, we train our network with only synthetic data. Our experiments investigate the effect of different qualities and quantities of training data on retrieval accuracy and present insights from bridging the domain gap. We show that increasing the variety of synthetic data improves retrieval accuracy and that our system's performance in zero-shot mode can match that of the instance-aware mode, as far as narrowing down the search to the top 10% of objects.
Stereo Correspondence and Reconstruction of Endoscopic Data Challenge
Jan 28, 2021

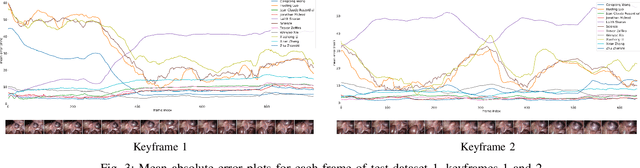
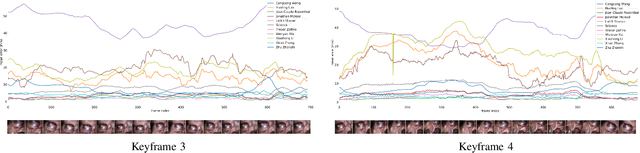
The stereo correspondence and reconstruction of endoscopic data sub-challenge was organized during the Endovis challenge at MICCAI 2019 in Shenzhen, China. The task was to perform dense depth estimation using 7 training datasets and 2 test sets of structured light data captured using porcine cadavers. These were provided by a team at Intuitive Surgical. 10 teams participated in the challenge day. This paper contains 3 additional methods which were submitted after the challenge finished as well as a supplemental section from these teams on issues they found with the dataset.