 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOSY: Compositional 3DGS Synthesis for Disentangled Human Head Editing
May 22, 2026Recent 3D Gaussian Splatting (3DGS) GANs for human heads synthesize and render photorealistic 3D models in real-time and offer a vast variety in identity and appearance. However, controlling specific semantic attributes such as hair color or glasses remains challenging, as edits in the entangled latent space often induce unintended changes in identity or appearance. Although there are several methods that aim to disentangle the latent space post training by estimating directions that only modify certain features, these methods cannot guarantee complete disentanglement and often require pre-trained classifiers. In our approach, we propose a new generator architecture that synthesizes components, such as hair, skin, glasses, and torso, completely independently. This allows for changing the latent vector for one region while keeping the remaining parts fixed. Further, we achieve this separation using only sparse information such as the hair or skin color, eliminating the requirement of segmentation masks or geometric priors, often seen in prior work. To ensure matching shape and lighting conditions during editing, we allow minimal shared information via context tokens between the independent generators. These tokens even allow us to control the shape and light, without any prior annotation. Compared to existing works on GAN-based generation and editing, our method shows better disentanglement, more precise editing control, and competitive visual quality.
Video-based Locomotion Analysis for Fish Health Monitoring
Mar 05, 2026Monitoring the health conditions of fish is essential, as it enables the early detection of disease, safeguards animal welfare, and contributes to sustainable aquaculture practices. Physiological and pathological conditions of cultivated fish can be inferred by analyzing locomotion activities. In this paper, we present a system that estimates the locomotion activities from videos using multi object tracking. The core of our approach is a YOLOv11 detector embedded in a tracking-by-detection framework. We investigate various configurations of the YOLOv11-architecture as well as extensions that incorporate multiple frames to improve detection accuracy. Our system is evaluated on a manually annotated dataset of Sulawesi ricefish recorded in a home-aquarium-like setup, demonstrating its ability to reliably measure swimming direction and speed for fish health monitoring. The dataset will be made publicly available upon publication.
R3GW: Relightable 3D Gaussians for Outdoor Scenes in the Wild
Mar 03, 20263D Gaussian Splatting (3DGS) has established itself as a leading technique for 3D reconstruction and novel view synthesis of static scenes, achieving outstanding rendering quality and fast training. However, the method does not explicitly model the scene illumination, making it unsuitable for relighting tasks. Furthermore, 3DGS struggles to reconstruct scenes captured in the wild by unconstrained photo collections featuring changing lighting conditions. In this paper, we present R3GW, a novel method that learns a relightable 3DGS representation of an outdoor scene captured in the wild. Our approach separates the scene into a relightable foreground and a non-reflective background (the sky), using two distinct sets of Gaussians. R3GW models view-dependent lighting effects in the foreground reflections by combining Physically Based Rendering with the 3DGS scene representation in a varying illumination setting. We evaluate our method quantitatively and qualitatively on the NeRF-OSR dataset, offering state-of-the-art performance and enhanced support for physically-based relighting of unconstrained scenes. Our method synthesizes photorealistic novel views under arbitrary illumination conditions. Additionally, our representation of the sky mitigates depth reconstruction artifacts, improving rendering quality at the sky-foreground boundary
* Accepted at VISAPP 2026
Phys-3D: Physics-Constrained Real-Time Crowd Tracking and Counting on Railway Platforms
Feb 26, 2026Accurate, real-time crowd counting on railway platforms is essential for safety and capacity management. We propose to use a single camera mounted in a train, scanning the platform while arriving. While hardware constraints are simple, counting remains challenging due to dense occlusions, camera motion, and perspective distortions during train arrivals. Most existing tracking-by-detection approaches assume static cameras or ignore physical consistency in motion modeling, leading to unreliable counting under dynamic conditions. We propose a physics-constrained tracking framework that unifies detection, appearance, and 3D motion reasoning in a real-time pipeline. Our approach integrates a transfer-learned YOLOv11m detector with EfficientNet-B0 appearance encoding within DeepSORT, while introducing a physics-constrained Kalman model (Phys-3D) that enforces physically plausible 3D motion dynamics through pinhole geometry. To address counting brittleness under occlusions, we implement a virtual counting band with persistence. On our platform benchmark, MOT-RailwayPlatformCrowdHead Dataset(MOT-RPCH), our method reduces counting error to 2.97%, demonstrating robust performance despite motion and occlusions. Our results show that incorporating first-principles geometry and motion priors enables reliable crowd counting in safety-critical transportation scenarios, facilitating effective train scheduling and platform safety management.
* published at VISAPP 2026
CGS-GAN: 3D Consistent Gaussian Splatting GANs for High Resolution Human Head Synthesis
May 23, 2025



Recently, 3D GANs based on 3D Gaussian splatting have been proposed for high quality synthesis of human heads. However, existing methods stabilize training and enhance rendering quality from steep viewpoints by conditioning the random latent vector on the current camera position. This compromises 3D consistency, as we observe significant identity changes when re-synthesizing the 3D head with each camera shift. Conversely, fixing the camera to a single viewpoint yields high-quality renderings for that perspective but results in poor performance for novel views. Removing view-conditioning typically destabilizes GAN training, often causing the training to collapse. In response to these challenges, we introduce CGS-GAN, a novel 3D Gaussian Splatting GAN framework that enables stable training and high-quality 3D-consistent synthesis of human heads without relying on view-conditioning. To ensure training stability, we introduce a multi-view regularization technique that enhances generator convergence with minimal computational overhead. Additionally, we adapt the conditional loss used in existing 3D Gaussian splatting GANs and propose a generator architecture designed to not only stabilize training but also facilitate efficient rendering and straightforward scaling, enabling output resolutions up to $2048^2$. To evaluate the capabilities of CGS-GAN, we curate a new dataset derived from FFHQ. This dataset enables very high resolutions, focuses on larger portions of the human head, reduces view-dependent artifacts for improved 3D consistency, and excludes images where subjects are obscured by hands or other objects. As a result, our approach achieves very high rendering quality, supported by competitive FID scores, while ensuring consistent 3D scene generation. Check our our project page here: https://fraunhoferhhi.github.io/cgs-gan/
AppleGrowthVision: A large-scale stereo dataset for phenological analysis, fruit detection, and 3D reconstruction in apple orchards
May 20, 2025

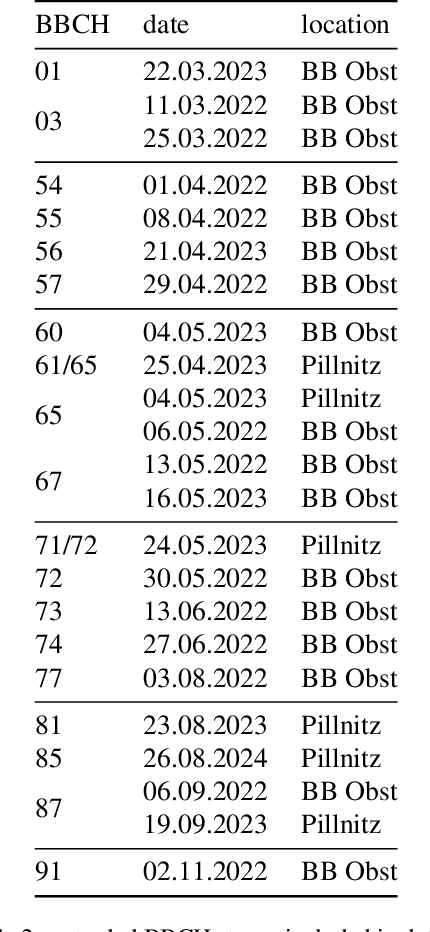
Deep learning has transformed computer vision for precision agriculture, yet apple orchard monitoring remains limited by dataset constraints. The lack of diverse, realistic datasets and the difficulty of annotating dense, heterogeneous scenes. Existing datasets overlook different growth stages and stereo imagery, both essential for realistic 3D modeling of orchards and tasks like fruit localization, yield estimation, and structural analysis. To address these gaps, we present AppleGrowthVision, a large-scale dataset comprising two subsets. The first includes 9,317 high resolution stereo images collected from a farm in Brandenburg (Germany), covering six agriculturally validated growth stages over a full growth cycle. The second subset consists of 1,125 densely annotated images from the same farm in Brandenburg and one in Pillnitz (Germany), containing a total of 31,084 apple labels. AppleGrowthVision provides stereo-image data with agriculturally validated growth stages, enabling precise phenological analysis and 3D reconstructions. Extending MinneApple with our data improves YOLOv8 performance by 7.69 % in terms of F1-score, while adding it to MinneApple and MAD boosts Faster R-CNN F1-score by 31.06 %. Additionally, six BBCH stages were predicted with over 95 % accuracy using VGG16, ResNet152, DenseNet201, and MobileNetv2. AppleGrowthVision bridges the gap between agricultural science and computer vision, by enabling the development of robust models for fruit detection, growth modeling, and 3D analysis in precision agriculture. Future work includes improving annotation, enhancing 3D reconstruction, and extending multimodal analysis across all growth stages.
Intraoperative perfusion assessment by continuous, low-latency hyperspectral light-field imaging: development, methodology, and clinical application
Apr 15, 2025Accurate assessment of tissue perfusion is crucial in visceral surgery, especially during anastomosis. Currently, subjective visual judgment is commonly employed in clinical settings. Hyperspectral imaging (HSI) offers a non-invasive, quantitative alternative. However, HSI imaging lacks continuous integration into the clinical workflow. This study presents a hyperspectral light field system for intraoperative tissue oxygen saturation (SO2) analysis and visualization. We present a correlation method for determining SO2 saturation with low computational demands. We demonstrate clinical application, with our results aligning with the perfusion boundaries determined by the surgeon. We perform and compare continuous perfusion analysis using two hyperspectral cameras (Cubert S5, Cubert X20), achieving processing times of < 170 ms and < 400 ms, respectively. We discuss camera characteristics, system parameters, and the suitability for clinical use and real-time applications.
* 6 pages, 4 figures
Improving Adaptive Density Control for 3D Gaussian Splatting
Mar 18, 2025

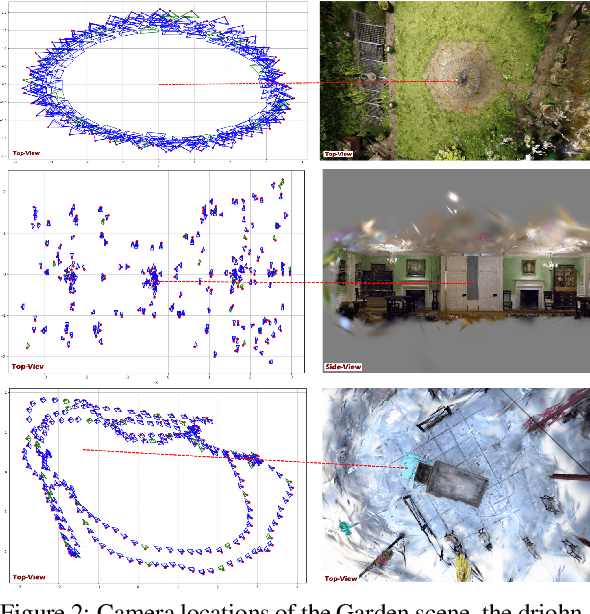

3D Gaussian Splatting (3DGS) has become one of the most influential works in the past year. Due to its efficient and high-quality novel view synthesis capabilities, it has been widely adopted in many research fields and applications. Nevertheless, 3DGS still faces challenges to properly manage the number of Gaussian primitives that are used during scene reconstruction. Following the adaptive density control (ADC) mechanism of 3D Gaussian Splatting, new Gaussians in under-reconstructed regions are created, while Gaussians that do not contribute to the rendering quality are pruned. We observe that those criteria for densifying and pruning Gaussians can sometimes lead to worse rendering by introducing artifacts. We especially observe under-reconstructed background or overfitted foreground regions. To encounter both problems, we propose three new improvements to the adaptive density control mechanism. Those include a correction for the scene extent calculation that does not only rely on camera positions, an exponentially ascending gradient threshold to improve training convergence, and significance-aware pruning strategy to avoid background artifacts. With these adaptions, we show that the rendering quality improves while using the same number of Gaussians primitives. Furthermore, with our improvements, the training converges considerably faster, allowing for more than twice as fast training times while yielding better quality than 3DGS. Finally, our contributions are easily compatible with most existing derivative works of 3DGS making them relevant for future works.
Improving Geometric Consistency for 360-Degree Neural Radiance Fields in Indoor Scenarios
Mar 17, 2025
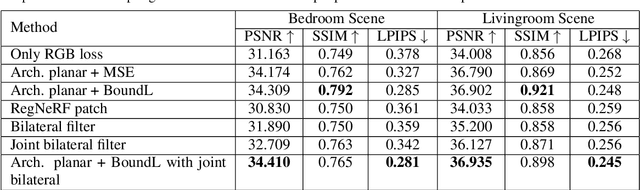

Photo-realistic rendering and novel view synthesis play a crucial role in human-computer interaction tasks, from gaming to path planning. Neural Radiance Fields (NeRFs) model scenes as continuous volumetric functions and achieve remarkable rendering quality. However, NeRFs often struggle in large, low-textured areas, producing cloudy artifacts known as ''floaters'' that reduce scene realism, especially in indoor environments with featureless architectural surfaces like walls, ceilings, and floors. To overcome this limitation, prior work has integrated geometric constraints into the NeRF pipeline, typically leveraging depth information derived from Structure from Motion or Multi-View Stereo. Yet, conventional RGB-feature correspondence methods face challenges in accurately estimating depth in textureless regions, leading to unreliable constraints. This challenge is further complicated in 360-degree ''inside-out'' views, where sparse visual overlap between adjacent images further hinders depth estimation. In order to address these issues, we propose an efficient and robust method for computing dense depth priors, specifically tailored for large low-textured architectural surfaces in indoor environments. We introduce a novel depth loss function to enhance rendering quality in these challenging, low-feature regions, while complementary depth-patch regularization further refines depth consistency across other areas. Experiments with Instant-NGP on two synthetic 360-degree indoor scenes demonstrate improved visual fidelity with our method compared to standard photometric loss and Mean Squared Error depth supervision.
Automatic Drywall Analysis for Progress Tracking and Quality Control in Construction
Mar 05, 2025



Digitalization in the construction industry has become essential, enabling centralized, easy access to all relevant information of a building. Automated systems can facilitate the timely and resource-efficient documentation of changes, which is crucial for key processes such as progress tracking and quality control. This paper presents a method for image-based automated drywall analysis enabling construction progress and quality assessment through on-site camera systems. Our proposed solution integrates a deep learning-based instance segmentation model to detect and classify various drywall elements with an analysis module to cluster individual wall segments, estimate camera perspective distortions, and apply the corresponding corrections. This system extracts valuable information from images, enabling more accurate progress tracking and quality assessment on construction sites. Our main contributions include a fully automated pipeline for drywall analysis, improving instance segmentation accuracy through architecture modifications and targeted data augmentation, and a novel algorithm to extract important information from the segmentation results. Our modified model, enhanced with data augmentation, achieves significantly higher accuracy compared to other architectures, offering more detailed and precise information than existing approaches. Combined with the proposed drywall analysis steps, it enables the reliable automation of construction progress and quality assessment.