 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAppleGrowthVision: A large-scale stereo dataset for phenological analysis, fruit detection, and 3D reconstruction in apple orchards
May 20, 2025Deep learning has transformed computer vision for precision agriculture, yet apple orchard monitoring remains limited by dataset constraints. The lack of diverse, realistic datasets and the difficulty of annotating dense, heterogeneous scenes. Existing datasets overlook different growth stages and stereo imagery, both essential for realistic 3D modeling of orchards and tasks like fruit localization, yield estimation, and structural analysis. To address these gaps, we present AppleGrowthVision, a large-scale dataset comprising two subsets. The first includes 9,317 high resolution stereo images collected from a farm in Brandenburg (Germany), covering six agriculturally validated growth stages over a full growth cycle. The second subset consists of 1,125 densely annotated images from the same farm in Brandenburg and one in Pillnitz (Germany), containing a total of 31,084 apple labels. AppleGrowthVision provides stereo-image data with agriculturally validated growth stages, enabling precise phenological analysis and 3D reconstructions. Extending MinneApple with our data improves YOLOv8 performance by 7.69 % in terms of F1-score, while adding it to MinneApple and MAD boosts Faster R-CNN F1-score by 31.06 %. Additionally, six BBCH stages were predicted with over 95 % accuracy using VGG16, ResNet152, DenseNet201, and MobileNetv2. AppleGrowthVision bridges the gap between agricultural science and computer vision, by enabling the development of robust models for fruit detection, growth modeling, and 3D analysis in precision agriculture. Future work includes improving annotation, enhancing 3D reconstruction, and extending multimodal analysis across all growth stages.
EEG-Features for Generalized Deepfake Detection
May 14, 2024

Since the advent of Deepfakes in digital media, the development of robust and reliable detection mechanism is urgently called for. In this study, we explore a novel approach to Deepfake detection by utilizing electroencephalography (EEG) measured from the neural processing of a human participant who viewed and categorized Deepfake stimuli from the FaceForensics++ datset. These measurements serve as input features to a binary support vector classifier, trained to discriminate between real and manipulated facial images. We examine whether EEG data can inform Deepfake detection and also if it can provide a generalized representation capable of identifying Deepfakes beyond the training domain. Our preliminary results indicate that human neural processing signals can be successfully integrated into Deepfake detection frameworks and hint at the potential for a generalized neural representation of artifacts in computer generated faces. Moreover, our study provides next steps towards the understanding of how digital realism is embedded in the human cognitive system, possibly enabling the development of more realistic digital avatars in the future.
Human-Centered Evaluation of XAI Methods
Oct 16, 2023In the ever-evolving field of Artificial Intelligence, a critical challenge has been to decipher the decision-making processes within the so-called "black boxes" in deep learning. Over recent years, a plethora of methods have emerged, dedicated to explaining decisions across diverse tasks. Particularly in tasks like image classification, these methods typically identify and emphasize the pivotal pixels that most influence a classifier's prediction. Interestingly, this approach mirrors human behavior: when asked to explain our rationale for classifying an image, we often point to the most salient features or aspects. Capitalizing on this parallel, our research embarked on a user-centric study. We sought to objectively measure the interpretability of three leading explanation methods: (1) Prototypical Part Network, (2) Occlusion, and (3) Layer-wise Relevance Propagation. Intriguingly, our results highlight that while the regions spotlighted by these methods can vary widely, they all offer humans a nearly equivalent depth of understanding. This enables users to discern and categorize images efficiently, reinforcing the value of these methods in enhancing AI transparency.
A differentiable Gaussian Prototype Layer for explainable Segmentation
Jun 25, 2023We introduce a Gaussian Prototype Layer for gradient-based prototype learning and demonstrate two novel network architectures for explainable segmentation one of which relies on region proposals. Both models are evaluated on agricultural datasets. While Gaussian Mixture Models (GMMs) have been used to model latent distributions of neural networks before, they are typically fitted using the EM algorithm. Instead, the proposed prototype layer relies on gradient-based optimization and hence allows for end-to-end training. This facilitates development and allows to use the full potential of a trainable deep feature extractor. We show that it can be used as a novel building block for explainable neural networks. We employ our Gaussian Prototype Layer in (1) a model where prototypes are detected in the latent grid and (2) a model inspired by Fast-RCNN with SLIC superpixels as region proposals. The earlier achieves a similar performance as compared to the state-of-the art while the latter has the benefit of a more precise prototype localization that comes at the cost of slightly lower accuracies. By introducing a gradient-based GMM layer we combine the benefits of end-to-end training with the simplicity and theoretical foundation of GMMs which will allow to adapt existing semi-supervised learning strategies for prototypical part models in future.
From "Where" to "What": Towards Human-Understandable Explanations through Concept Relevance Propagation
Jun 07, 2022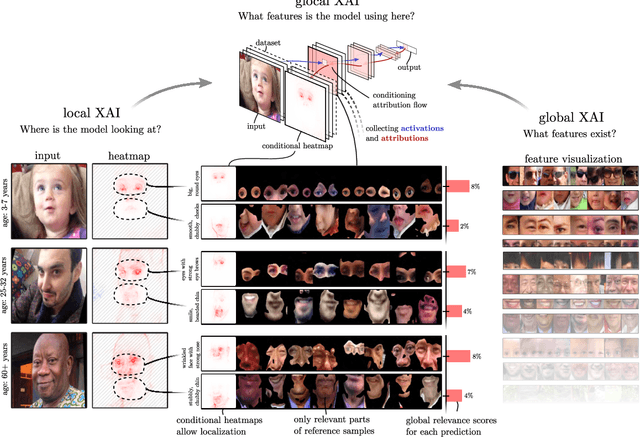

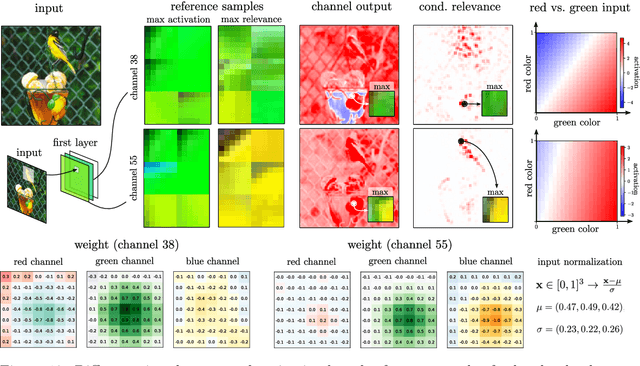

The emerging field of eXplainable Artificial Intelligence (XAI) aims to bring transparency to today's powerful but opaque deep learning models. While local XAI methods explain individual predictions in form of attribution maps, thereby identifying where important features occur (but not providing information about what they represent), global explanation techniques visualize what concepts a model has generally learned to encode. Both types of methods thus only provide partial insights and leave the burden of interpreting the model's reasoning to the user. Only few contemporary techniques aim at combining the principles behind both local and global XAI for obtaining more informative explanations. Those methods, however, are often limited to specific model architectures or impose additional requirements on training regimes or data and label availability, which renders the post-hoc application to arbitrarily pre-trained models practically impossible. In this work we introduce the Concept Relevance Propagation (CRP) approach, which combines the local and global perspectives of XAI and thus allows answering both the "where" and "what" questions for individual predictions, without additional constraints imposed. We further introduce the principle of Relevance Maximization for finding representative examples of encoded concepts based on their usefulness to the model. We thereby lift the dependency on the common practice of Activation Maximization and its limitations. We demonstrate the capabilities of our methods in various settings, showcasing that Concept Relevance Propagation and Relevance Maximization lead to more human interpretable explanations and provide deep insights into the model's representations and reasoning through concept atlases, concept composition analyses, and quantitative investigations of concept subspaces and their role in fine-grained decision making.
But that's not why: Inference adjustment by interactive prototype deselection
Mar 18, 2022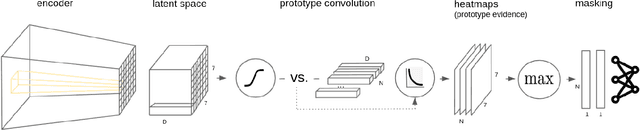
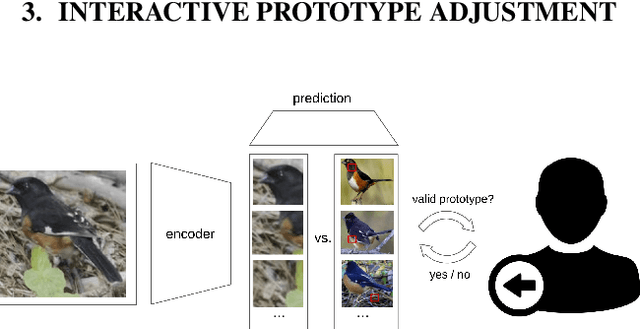
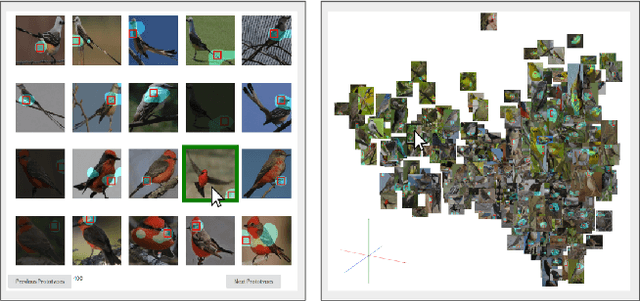
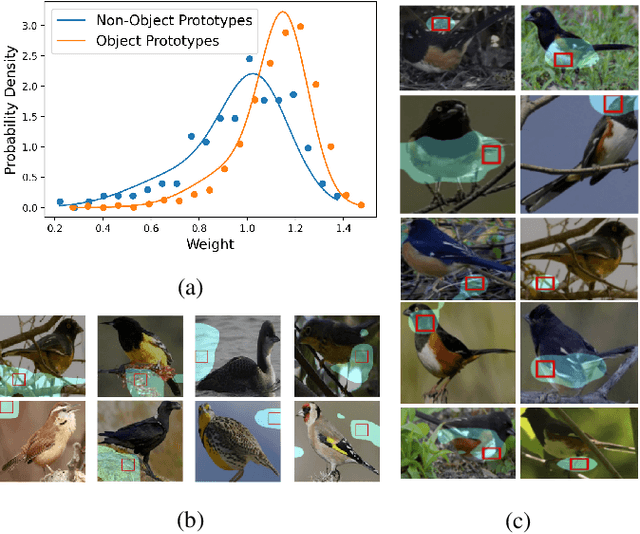
Despite significant advances in machine learning, decision-making of artificial agents is still not perfect and often requires post-hoc human interventions. If the prediction of a model relies on unreasonable factors it is desirable to remove their effect. Deep interactive prototype adjustment enables the user to give hints and correct the model's reasoning. In this paper, we demonstrate that prototypical-part models are well suited for this task as their prediction is based on prototypical image patches that can be interpreted semantically by the user. It shows that even correct classifications can rely on unreasonable prototypes that result from confounding variables in a dataset. Hence, we propose simple yet effective interaction schemes for inference adjustment: The user is consulted interactively to identify faulty prototypes. Non-object prototypes can be removed by prototype masking or a custom mode of deselection training. Interactive prototype rejection allows machine learning na\"{i}ve users to adjust the logic of reasoning without compromising the accuracy.
Curiously Effective Features for Image Quality Prediction
Jun 10, 2021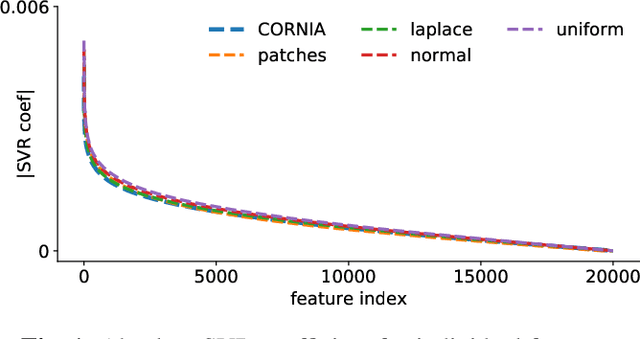
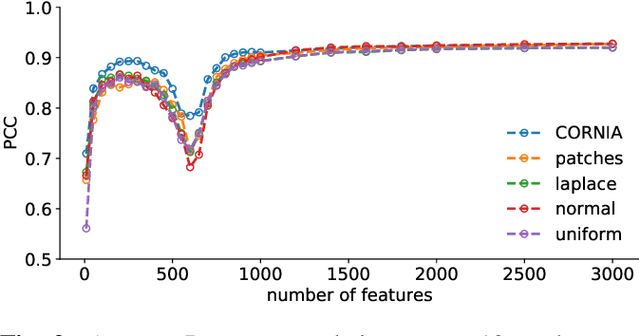
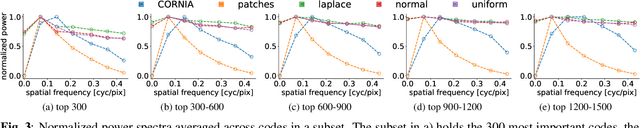
The performance of visual quality prediction models is commonly assumed to be closely tied to their ability to capture perceptually relevant image aspects. Models are thus either based on sophisticated feature extractors carefully designed from extensive domain knowledge or optimized through feature learning. In contrast to this, we find feature extractors constructed from random noise to be sufficient to learn a linear regression model whose quality predictions reach high correlations with human visual quality ratings, on par with a model with learned features. We analyze this curious result and show that besides the quality of feature extractors also their quantity plays a crucial role - with top performances only being achieved in highly overparameterized models.
Deep Neural Networks for No-Reference and Full-Reference Image Quality Assessment
Dec 07, 2017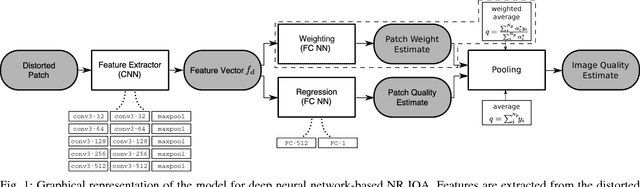
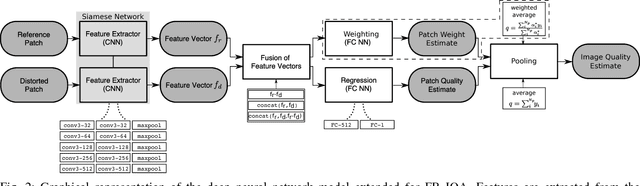
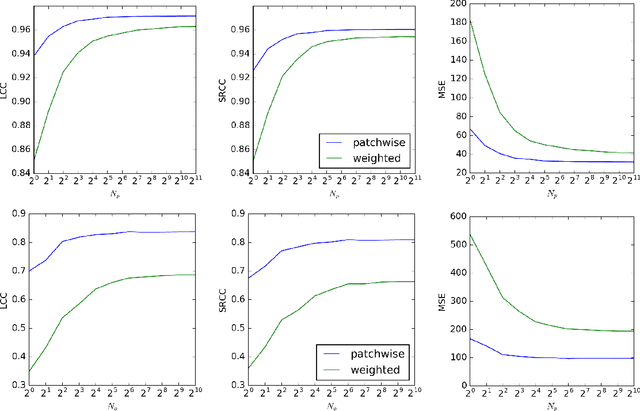

We present a deep neural network-based approach to image quality assessment (IQA). The network is trained end-to-end and comprises ten convolutional layers and five pooling layers for feature extraction, and two fully connected layers for regression, which makes it significantly deeper than related IQA models. Unique features of the proposed architecture are that: 1) with slight adaptations it can be used in a no-reference (NR) as well as in a full-reference (FR) IQA setting and 2) it allows for joint learning of local quality and local weights, i.e., relative importance of local quality to the global quality estimate, in an unified framework. Our approach is purely data-driven and does not rely on hand-crafted features or other types of prior domain knowledge about the human visual system or image statistics. We evaluate the proposed approach on the LIVE, CISQ, and TID2013 databases as well as the LIVE In the wild image quality challenge database and show superior performance to state-of-the-art NR and FR IQA methods. Finally, cross-database evaluation shows a high ability to generalize between different databases, indicating a high robustness of the learned features.
A Haar Wavelet-Based Perceptual Similarity Index for Image Quality Assessment
Nov 06, 2017
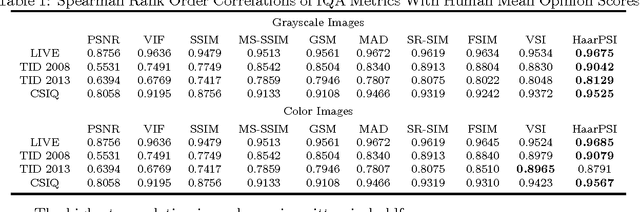

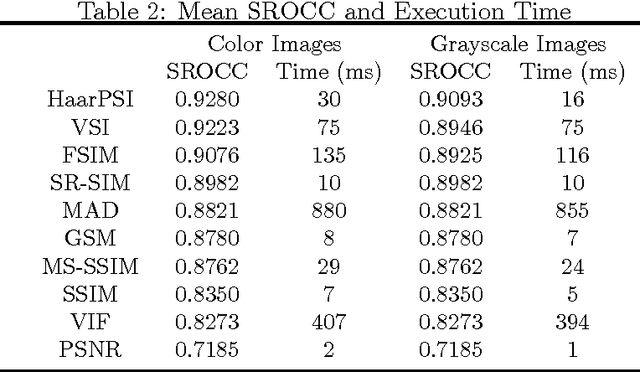
In most practical situations, the compression or transmission of images and videos creates distortions that will eventually be perceived by a human observer. Vice versa, image and video restoration techniques, such as inpainting or denoising, aim to enhance the quality of experience of human viewers. Correctly assessing the similarity between an image and an undistorted reference image as subjectively experienced by a human viewer can thus lead to significant improvements in any transmission, compression, or restoration system. This paper introduces the Haar wavelet-based perceptual similarity index (HaarPSI), a novel and computationally inexpensive similarity measure for full reference image quality assessment. The HaarPSI utilizes the coefficients obtained from a Haar wavelet decomposition to assess local similarities between two images, as well as the relative importance of image areas. The consistency of the HaarPSI with the human quality of experience was validated on four large benchmark databases containing thousands of differently distorted images. On these databases, the HaarPSI achieves higher correlations with human opinion scores than state-of-the-art full reference similarity measures like the structural similarity index (SSIM), the feature similarity index (FSIM), and the visual saliency-based index (VSI). Along with the simple computational structure and the short execution time, these experimental results suggest a high applicability of the HaarPSI in real world tasks.