 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuriously Effective Features for Image Quality Prediction
Paper and Code
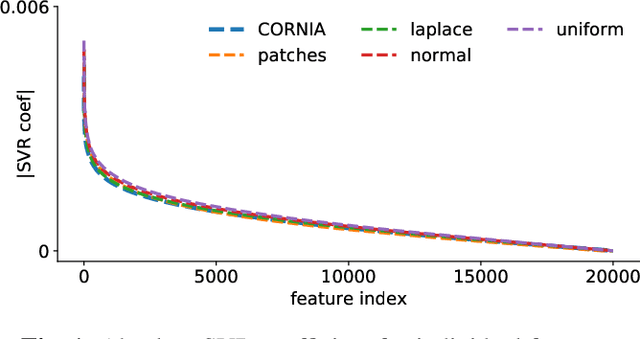
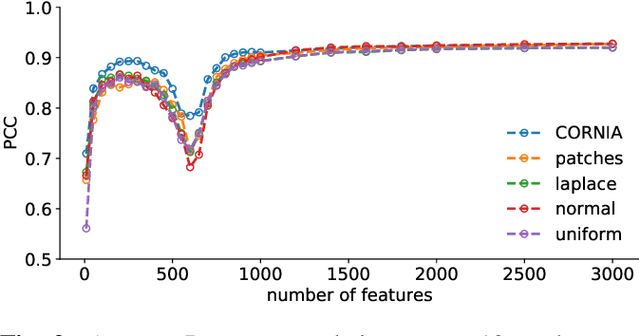
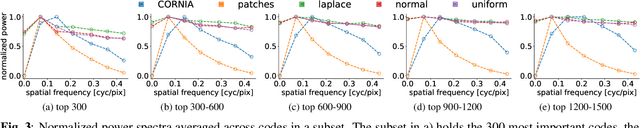
The performance of visual quality prediction models is commonly assumed to be closely tied to their ability to capture perceptually relevant image aspects. Models are thus either based on sophisticated feature extractors carefully designed from extensive domain knowledge or optimized through feature learning. In contrast to this, we find feature extractors constructed from random noise to be sufficient to learn a linear regression model whose quality predictions reach high correlations with human visual quality ratings, on par with a model with learned features. We analyze this curious result and show that besides the quality of feature extractors also their quantity plays a crucial role - with top performances only being achieved in highly overparameterized models.