 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Semantic Projection: Faithful Neuron Labeling with Contrastive Examples
Apr 24, 2026Neuron labeling assigns textual descriptions to internal units of deep networks. Existing approaches typically rely on highly activating examples, often yielding broad or misleading labels by focusing on dominant but incidental visual factors. Prior work such as FALCON introduced contrastive examples -- inputs that are semantically similar to activating examples but elicit low activations -- to sharpen explanations, but it primarily addresses subspace-level interpretability rather than scalable neuron-level labeling. We revisit contrastive explanations for neuron-level labeling in two stages: (1) candidate label generation with vision language models (VLMs) and (2) label assignment with CLIP-like encoders. First, we show that providing contrastive image sets to VLMs yields candidate labels that are more specific and more faithful. Second, we introduce Contrastive Semantic Projection (CSP), an extension of SemanticLens that incorporates contrastive examples directly into its CLIP-based scoring and selection pipeline. Across extensive experiments and a case study on melanoma detection, contrastive labeling improves both faithfulness and semantic granularity over state-of-the-art baselines. Our results demonstrate that contrastive examples are a simple yet powerful and currently underutilized component of neuron labeling and analysis pipelines.
From Attribution to Action: A Human-Centered Application of Activation Steering
Apr 13, 2026Explainable AI (XAI) methods reveal which features influence model predictions, yet provide limited means for practitioners to act on these explanations. Activation steering of components identified via XAI offers a path toward actionable explanations, although its practical utility remains understudied. We introduce an interactive workflow combining SAE-based attribution with activation steering for instance-level analysis of concept usage in vision models, implemented as a web-based tool. Based on this workflow, we conduct semi-structured expert interviews (N=8) with debugging tasks on CLIP to investigate how practitioners reason about, trust, and apply activation steering. We find that steering enables a shift from inspection to intervention-based hypothesis testing (8/8 participants), with most grounding trust in observed model responses rather than explanation plausibility alone (6/8). Participants adopted systematic debugging strategies dominated by component suppression (7/8) and highlighted risks including ripple effects and limited generalization of instance-level corrections. Overall, activation steering renders interpretability more actionable while raising important considerations for safe and effective use.
X-SYS: A Reference Architecture for Interactive Explanation Systems
Feb 13, 2026The explainable AI (XAI) research community has proposed numerous technical methods, yet deploying explainability as systems remains challenging: Interactive explanation systems require both suitable algorithms and system capabilities that maintain explanation usability across repeated queries, evolving models and data, and governance constraints. We argue that operationalizing XAI requires treating explainability as an information systems problem where user interaction demands induce specific system requirements. We introduce X-SYS, a reference architecture for interactive explanation systems, that guides (X)AI researchers, developers and practitioners in connecting interactive explanation user interfaces (XUI) with system capabilities. X-SYS organizes around four quality attributes named STAR (scalability, traceability, responsiveness, and adaptability), and specifies a five-component decomposition (XUI Services, Explanation Services, Model Services, Data Services, Orchestration and Governance). It maps interaction patterns to system capabilities to decouple user interface evolution from backend computation. We implement X-SYS through SemanticLens, a system for semantic search and activation steering in vision-language models. SemanticLens demonstrates how contract-based service boundaries enable independent evolution, offline/online separation ensures responsiveness, and persistent state management supports traceability. Together, this work provides a reusable blueprint and concrete instantiation for interactive explanation systems supporting end-to-end design under operational constraints.
Attribution-guided Pruning for Compression, Circuit Discovery, and Targeted Correction in LLMs
Jun 16, 2025Large Language Models (LLMs) are central to many contemporary AI applications, yet their extensive parameter counts pose significant challenges for deployment in memory- and compute-constrained environments. Recent works in eXplainable AI (XAI), particularly on attribution methods, suggest that interpretability can also enable model compression by identifying and removing components irrelevant to inference. In this paper, we leverage Layer-wise Relevance Propagation (LRP) to perform attribution-guided pruning of LLMs. While LRP has shown promise in structured pruning for vision models, we extend it to unstructured pruning in LLMs and demonstrate that it can substantially reduce model size with minimal performance loss. Our method is especially effective in extracting task-relevant subgraphs -- so-called ``circuits'' -- which can represent core functions (e.g., indirect object identification). Building on this, we introduce a technique for model correction, by selectively removing circuits responsible for spurious behaviors (e.g., toxic outputs). All in all, we gather these techniques as a uniform holistic framework and showcase its effectiveness and limitations through extensive experiments for compression, circuit discovery and model correction on Llama and OPT models, highlighting its potential for improving both model efficiency and safety. Our code is publicly available at https://github.com/erfanhatefi/SparC3.
From What to How: Attributing CLIP's Latent Components Reveals Unexpected Semantic Reliance
May 26, 2025



Transformer-based CLIP models are widely used for text-image probing and feature extraction, making it relevant to understand the internal mechanisms behind their predictions. While recent works show that Sparse Autoencoders (SAEs) yield interpretable latent components, they focus on what these encode and miss how they drive predictions. We introduce a scalable framework that reveals what latent components activate for, how they align with expected semantics, and how important they are to predictions. To achieve this, we adapt attribution patching for instance-wise component attributions in CLIP and highlight key faithfulness limitations of the widely used Logit Lens technique. By combining attributions with semantic alignment scores, we can automatically uncover reliance on components that encode semantically unexpected or spurious concepts. Applied across multiple CLIP variants, our method uncovers hundreds of surprising components linked to polysemous words, compound nouns, visual typography and dataset artifacts. While text embeddings remain prone to semantic ambiguity, they are more robust to spurious correlations compared to linear classifiers trained on image embeddings. A case study on skin lesion detection highlights how such classifiers can amplify hidden shortcuts, underscoring the need for holistic, mechanistic interpretability. We provide code at https://github.com/maxdreyer/attributing-clip.
Mechanistic understanding and validation of large AI models with SemanticLens
Jan 09, 2025

Unlike human-engineered systems such as aeroplanes, where each component's role and dependencies are well understood, the inner workings of AI models remain largely opaque, hindering verifiability and undermining trust. This paper introduces SemanticLens, a universal explanation method for neural networks that maps hidden knowledge encoded by components (e.g., individual neurons) into the semantically structured, multimodal space of a foundation model such as CLIP. In this space, unique operations become possible, including (i) textual search to identify neurons encoding specific concepts, (ii) systematic analysis and comparison of model representations, (iii) automated labelling of neurons and explanation of their functional roles, and (iv) audits to validate decision-making against requirements. Fully scalable and operating without human input, SemanticLens is shown to be effective for debugging and validation, summarizing model knowledge, aligning reasoning with expectations (e.g., adherence to the ABCDE-rule in melanoma classification), and detecting components tied to spurious correlations and their associated training data. By enabling component-level understanding and validation, the proposed approach helps bridge the "trust gap" between AI models and traditional engineered systems. We provide code for SemanticLens on https://github.com/jim-berend/semanticlens and a demo on https://semanticlens.hhi-research-insights.eu.
Pruning By Explaining Revisited: Optimizing Attribution Methods to Prune CNNs and Transformers
Aug 22, 2024

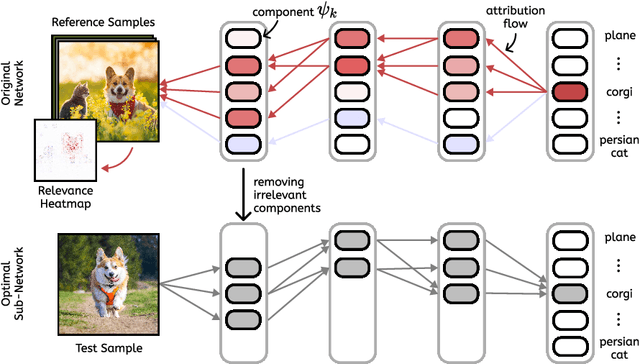

To solve ever more complex problems, Deep Neural Networks are scaled to billions of parameters, leading to huge computational costs. An effective approach to reduce computational requirements and increase efficiency is to prune unnecessary components of these often over-parameterized networks. Previous work has shown that attribution methods from the field of eXplainable AI serve as effective means to extract and prune the least relevant network components in a few-shot fashion. We extend the current state by proposing to explicitly optimize hyperparameters of attribution methods for the task of pruning, and further include transformer-based networks in our analysis. Our approach yields higher model compression rates of large transformer- and convolutional architectures (VGG, ResNet, ViT) compared to previous works, while still attaining high performance on ImageNet classification tasks. Here, our experiments indicate that transformers have a higher degree of over-parameterization compared to convolutional neural networks. Code is available at $\href{https://github.com/erfanhatefi/Pruning-by-eXplaining-in-PyTorch}{\text{this https link}}$.
Explainable concept mappings of MRI: Revealing the mechanisms underlying deep learning-based brain disease classification
Apr 16, 2024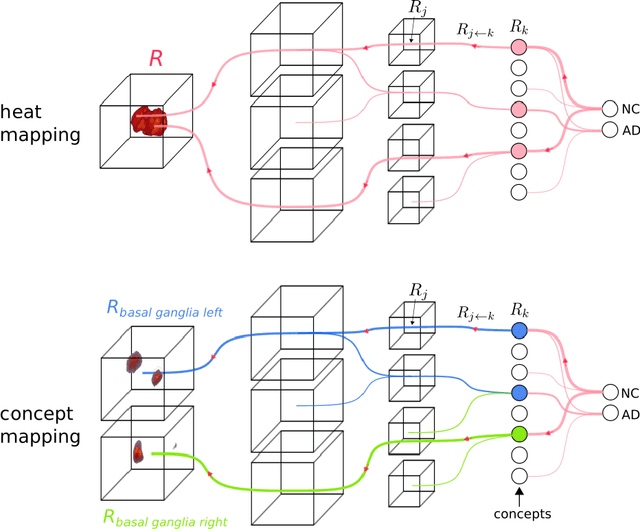
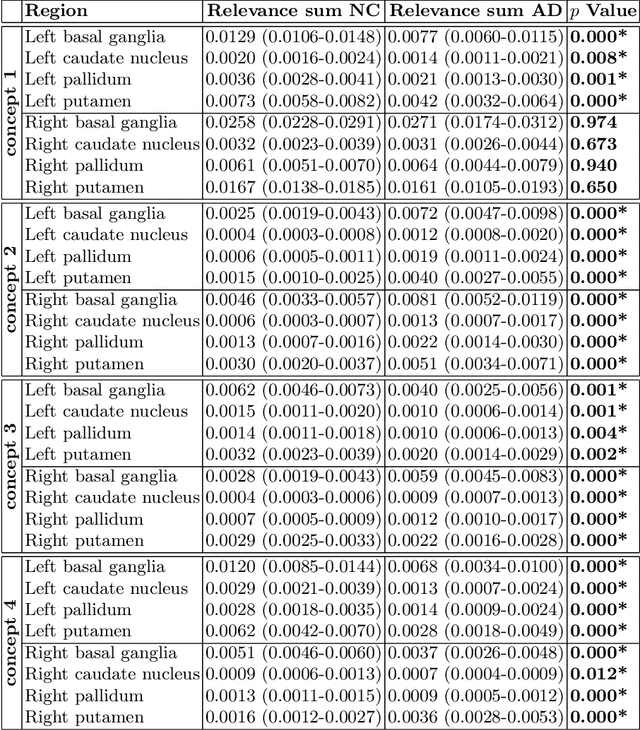
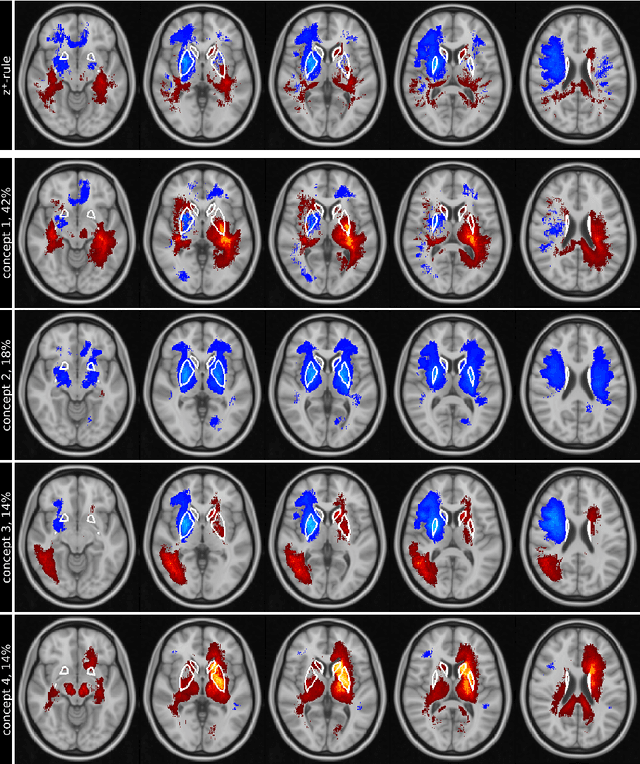
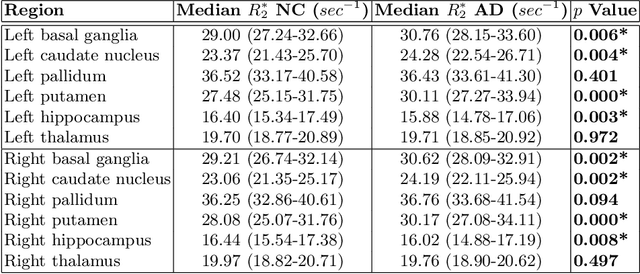
Motivation. While recent studies show high accuracy in the classification of Alzheimer's disease using deep neural networks, the underlying learned concepts have not been investigated. Goals. To systematically identify changes in brain regions through concepts learned by the deep neural network for model validation. Approach. Using quantitative R2* maps we separated Alzheimer's patients (n=117) from normal controls (n=219) by using a convolutional neural network and systematically investigated the learned concepts using Concept Relevance Propagation and compared these results to a conventional region of interest-based analysis. Results. In line with established histological findings and the region of interest-based analyses, highly relevant concepts were primarily found in and adjacent to the basal ganglia. Impact. The identification of concepts learned by deep neural networks for disease classification enables validation of the models and could potentially improve reliability.
Reactive Model Correction: Mitigating Harm to Task-Relevant Features via Conditional Bias Suppression
Apr 15, 2024



Deep Neural Networks are prone to learning and relying on spurious correlations in the training data, which, for high-risk applications, can have fatal consequences. Various approaches to suppress model reliance on harmful features have been proposed that can be applied post-hoc without additional training. Whereas those methods can be applied with efficiency, they also tend to harm model performance by globally shifting the distribution of latent features. To mitigate unintended overcorrection of model behavior, we propose a reactive approach conditioned on model-derived knowledge and eXplainable Artificial Intelligence (XAI) insights. While the reactive approach can be applied to many post-hoc methods, we demonstrate the incorporation of reactivity in particular for P-ClArC (Projective Class Artifact Compensation), introducing a new method called R-ClArC (Reactive Class Artifact Compensation). Through rigorous experiments in controlled settings (FunnyBirds) and with a real-world dataset (ISIC2019), we show that introducing reactivity can minimize the detrimental effect of the applied correction while simultaneously ensuring low reliance on spurious features.
PURE: Turning Polysemantic Neurons Into Pure Features by Identifying Relevant Circuits
Apr 09, 2024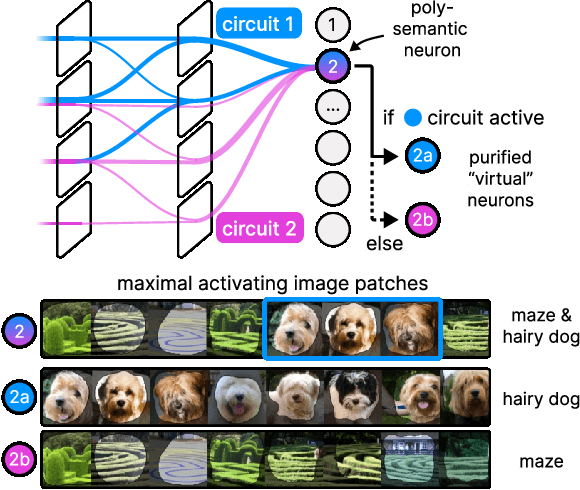
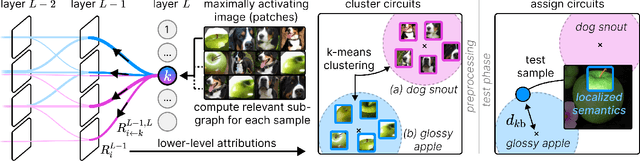

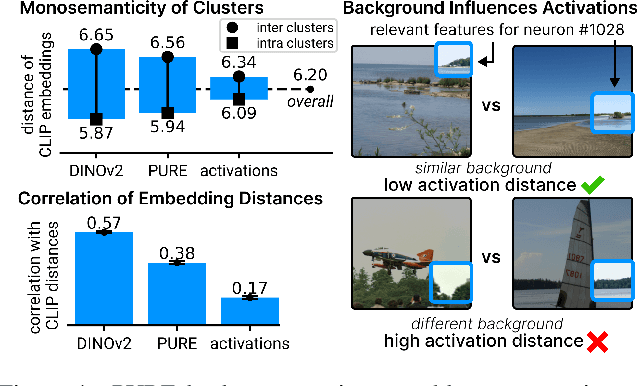
The field of mechanistic interpretability aims to study the role of individual neurons in Deep Neural Networks. Single neurons, however, have the capability to act polysemantically and encode for multiple (unrelated) features, which renders their interpretation difficult. We present a method for disentangling polysemanticity of any Deep Neural Network by decomposing a polysemantic neuron into multiple monosemantic "virtual" neurons. This is achieved by identifying the relevant sub-graph ("circuit") for each "pure" feature. We demonstrate how our approach allows us to find and disentangle various polysemantic units of ResNet models trained on ImageNet. While evaluating feature visualizations using CLIP, our method effectively disentangles representations, improving upon methods based on neuron activations. Our code is available at https://github.com/maxdreyer/PURE.