 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning By Explaining Revisited: Optimizing Attribution Methods to Prune CNNs and Transformers
Paper and Code


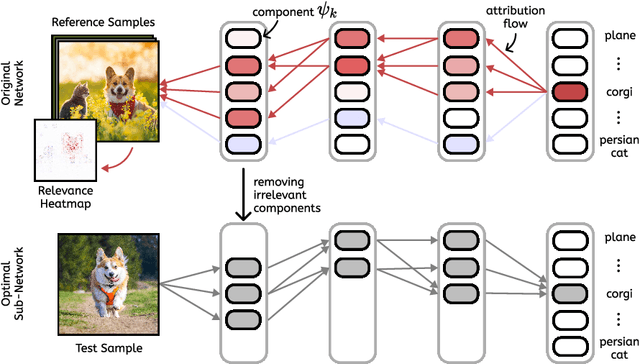

To solve ever more complex problems, Deep Neural Networks are scaled to billions of parameters, leading to huge computational costs. An effective approach to reduce computational requirements and increase efficiency is to prune unnecessary components of these often over-parameterized networks. Previous work has shown that attribution methods from the field of eXplainable AI serve as effective means to extract and prune the least relevant network components in a few-shot fashion. We extend the current state by proposing to explicitly optimize hyperparameters of attribution methods for the task of pruning, and further include transformer-based networks in our analysis. Our approach yields higher model compression rates of large transformer- and convolutional architectures (VGG, ResNet, ViT) compared to previous works, while still attaining high performance on ImageNet classification tasks. Here, our experiments indicate that transformers have a higher degree of over-parameterization compared to convolutional neural networks. Code is available at $\href{https://github.com/erfanhatefi/Pruning-by-eXplaining-in-PyTorch}{\text{this https link}}$.