 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribution-guided Pruning for Compression, Circuit Discovery, and Targeted Correction in LLMs
Jun 16, 2025Large Language Models (LLMs) are central to many contemporary AI applications, yet their extensive parameter counts pose significant challenges for deployment in memory- and compute-constrained environments. Recent works in eXplainable AI (XAI), particularly on attribution methods, suggest that interpretability can also enable model compression by identifying and removing components irrelevant to inference. In this paper, we leverage Layer-wise Relevance Propagation (LRP) to perform attribution-guided pruning of LLMs. While LRP has shown promise in structured pruning for vision models, we extend it to unstructured pruning in LLMs and demonstrate that it can substantially reduce model size with minimal performance loss. Our method is especially effective in extracting task-relevant subgraphs -- so-called ``circuits'' -- which can represent core functions (e.g., indirect object identification). Building on this, we introduce a technique for model correction, by selectively removing circuits responsible for spurious behaviors (e.g., toxic outputs). All in all, we gather these techniques as a uniform holistic framework and showcase its effectiveness and limitations through extensive experiments for compression, circuit discovery and model correction on Llama and OPT models, highlighting its potential for improving both model efficiency and safety. Our code is publicly available at https://github.com/erfanhatefi/SparC3.
The Atlas of In-Context Learning: How Attention Heads Shape In-Context Retrieval Augmentation
May 21, 2025Large language models are able to exploit in-context learning to access external knowledge beyond their training data through retrieval-augmentation. While promising, its inner workings remain unclear. In this work, we shed light on the mechanism of in-context retrieval augmentation for question answering by viewing a prompt as a composition of informational components. We propose an attribution-based method to identify specialized attention heads, revealing in-context heads that comprehend instructions and retrieve relevant contextual information, and parametric heads that store entities' relational knowledge. To better understand their roles, we extract function vectors and modify their attention weights to show how they can influence the answer generation process. Finally, we leverage the gained insights to trace the sources of knowledge used during inference, paving the way towards more safe and transparent language models.
Pruning By Explaining Revisited: Optimizing Attribution Methods to Prune CNNs and Transformers
Aug 22, 2024

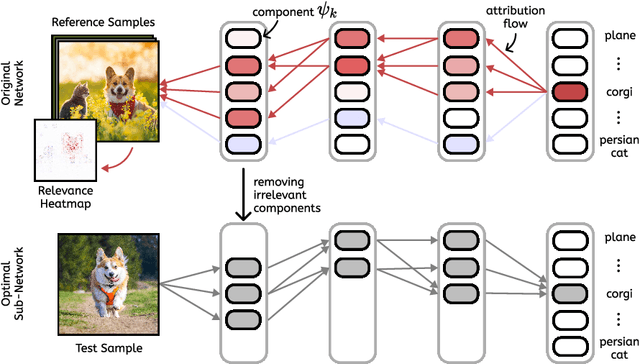

To solve ever more complex problems, Deep Neural Networks are scaled to billions of parameters, leading to huge computational costs. An effective approach to reduce computational requirements and increase efficiency is to prune unnecessary components of these often over-parameterized networks. Previous work has shown that attribution methods from the field of eXplainable AI serve as effective means to extract and prune the least relevant network components in a few-shot fashion. We extend the current state by proposing to explicitly optimize hyperparameters of attribution methods for the task of pruning, and further include transformer-based networks in our analysis. Our approach yields higher model compression rates of large transformer- and convolutional architectures (VGG, ResNet, ViT) compared to previous works, while still attaining high performance on ImageNet classification tasks. Here, our experiments indicate that transformers have a higher degree of over-parameterization compared to convolutional neural networks. Code is available at $\href{https://github.com/erfanhatefi/Pruning-by-eXplaining-in-PyTorch}{\text{this https link}}$.
Explainable concept mappings of MRI: Revealing the mechanisms underlying deep learning-based brain disease classification
Apr 16, 2024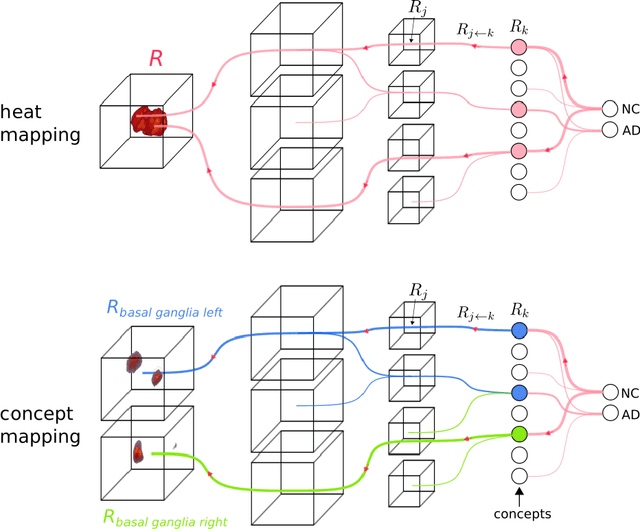
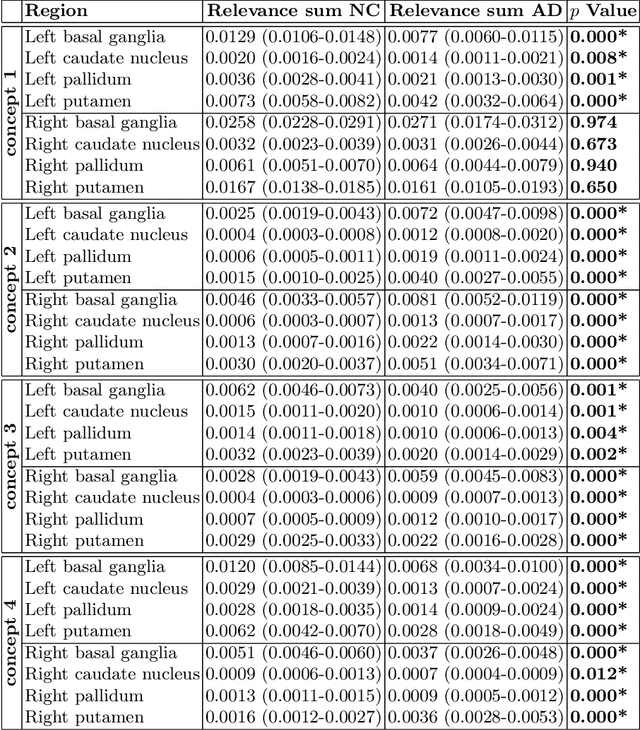
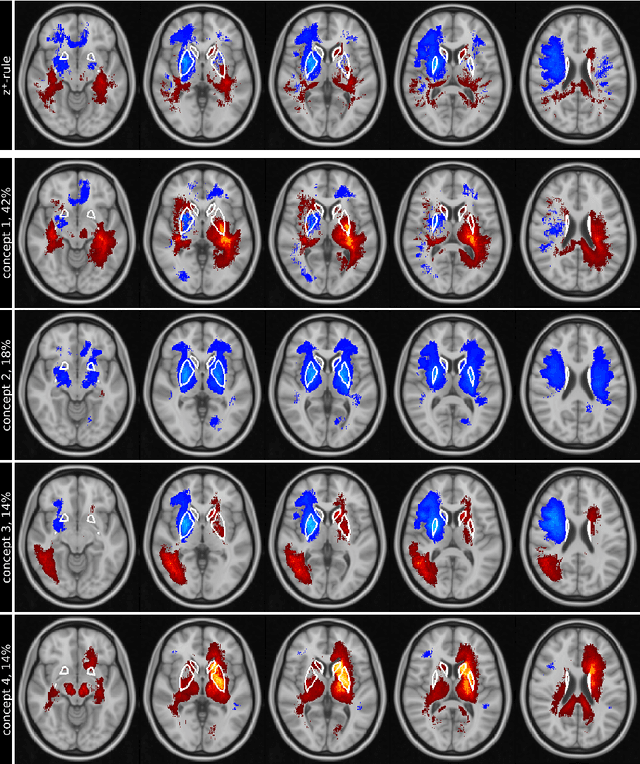
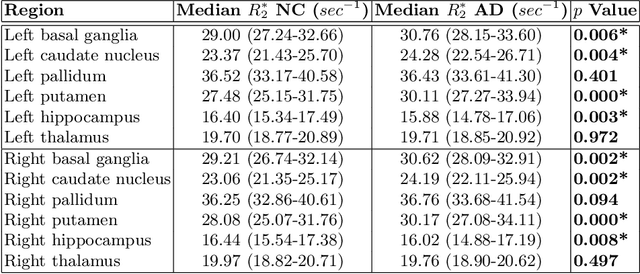
Motivation. While recent studies show high accuracy in the classification of Alzheimer's disease using deep neural networks, the underlying learned concepts have not been investigated. Goals. To systematically identify changes in brain regions through concepts learned by the deep neural network for model validation. Approach. Using quantitative R2* maps we separated Alzheimer's patients (n=117) from normal controls (n=219) by using a convolutional neural network and systematically investigated the learned concepts using Concept Relevance Propagation and compared these results to a conventional region of interest-based analysis. Results. In line with established histological findings and the region of interest-based analyses, highly relevant concepts were primarily found in and adjacent to the basal ganglia. Impact. The identification of concepts learned by deep neural networks for disease classification enables validation of the models and could potentially improve reliability.
AttnLRP: Attention-Aware Layer-wise Relevance Propagation for Transformers
Feb 08, 2024
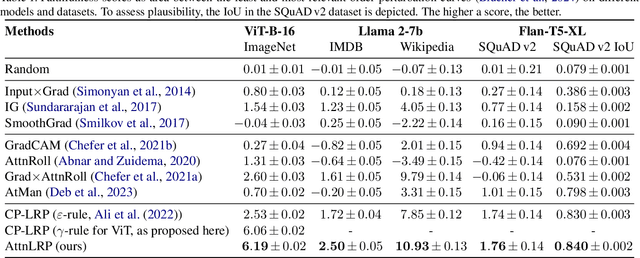
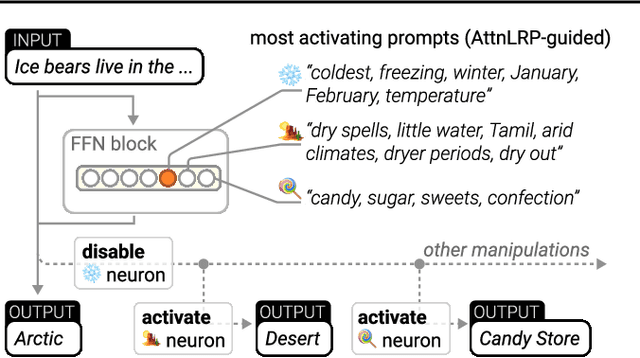

Large Language Models are prone to biased predictions and hallucinations, underlining the paramount importance of understanding their model-internal reasoning process. However, achieving faithful attributions for the entirety of a black-box transformer model and maintaining computational efficiency is an unsolved challenge. By extending the Layer-wise Relevance Propagation attribution method to handle attention layers, we address these challenges effectively. While partial solutions exist, our method is the first to faithfully and holistically attribute not only input but also latent representations of transformer models with the computational efficiency similar to a singular backward pass. Through extensive evaluations against existing methods on Llama 2, Flan-T5 and the Vision Transformer architecture, we demonstrate that our proposed approach surpasses alternative methods in terms of faithfulness and enables the understanding of latent representations, opening up the door for concept-based explanations. We provide an open-source implementation on GitHub https://github.com/rachtibat/LRP-for-Transformers.
Understanding the (Extra-)Ordinary: Validating Deep Model Decisions with Prototypical Concept-based Explanations
Nov 28, 2023



Ensuring both transparency and safety is critical when deploying Deep Neural Networks (DNNs) in high-risk applications, such as medicine. The field of explainable AI (XAI) has proposed various methods to comprehend the decision-making processes of opaque DNNs. However, only few XAI methods are suitable of ensuring safety in practice as they heavily rely on repeated labor-intensive and possibly biased human assessment. In this work, we present a novel post-hoc concept-based XAI framework that conveys besides instance-wise (local) also class-wise (global) decision-making strategies via prototypes. What sets our approach apart is the combination of local and global strategies, enabling a clearer understanding of the (dis-)similarities in model decisions compared to the expected (prototypical) concept use, ultimately reducing the dependence on human long-term assessment. Quantifying the deviation from prototypical behavior not only allows to associate predictions with specific model sub-strategies but also to detect outlier behavior. As such, our approach constitutes an intuitive and explainable tool for model validation. We demonstrate the effectiveness of our approach in identifying out-of-distribution samples, spurious model behavior and data quality issues across three datasets (ImageNet, CUB-200, and CIFAR-10) utilizing VGG, ResNet, and EfficientNet architectures. Code is available on https://github.com/maxdreyer/pcx.
Revealing Hidden Context Bias in Segmentation and Object Detection through Concept-specific Explanations
Nov 21, 2022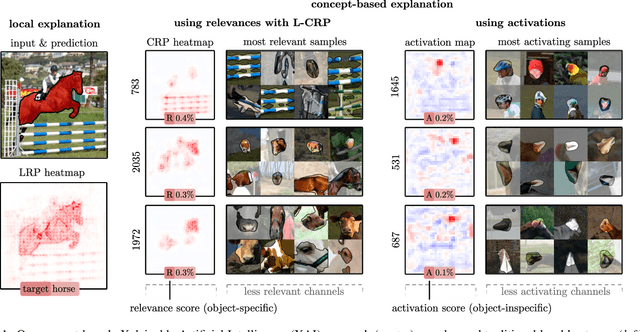


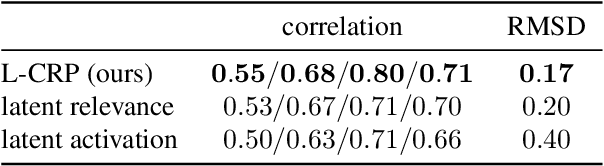
Applying traditional post-hoc attribution methods to segmentation or object detection predictors offers only limited insights, as the obtained feature attribution maps at input level typically resemble the models' predicted segmentation mask or bounding box. In this work, we address the need for more informative explanations for these predictors by proposing the post-hoc eXplainable Artificial Intelligence method L-CRP to generate explanations that automatically identify and visualize relevant concepts learned, recognized and used by the model during inference as well as precisely locate them in input space. Our method therefore goes beyond singular input-level attribution maps and, as an approach based on the recently published Concept Relevance Propagation technique, is efficiently applicable to state-of-the-art black-box architectures in segmentation and object detection, such as DeepLabV3+ and YOLOv6, among others. We verify the faithfulness of our proposed technique by quantitatively comparing different concept attribution methods, and discuss the effect on explanation complexity on popular datasets such as CityScapes, Pascal VOC and MS COCO 2017. The ability to precisely locate and communicate concepts is used to reveal and verify the use of background features, thereby highlighting possible biases of the model.
From "Where" to "What": Towards Human-Understandable Explanations through Concept Relevance Propagation
Jun 07, 2022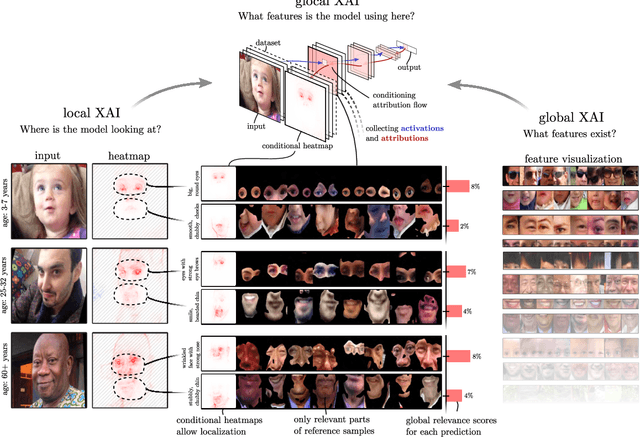

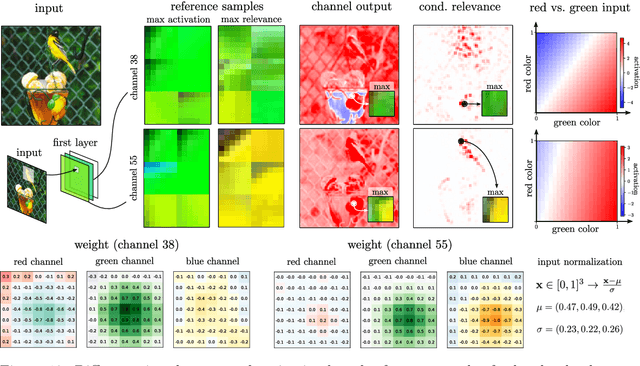

The emerging field of eXplainable Artificial Intelligence (XAI) aims to bring transparency to today's powerful but opaque deep learning models. While local XAI methods explain individual predictions in form of attribution maps, thereby identifying where important features occur (but not providing information about what they represent), global explanation techniques visualize what concepts a model has generally learned to encode. Both types of methods thus only provide partial insights and leave the burden of interpreting the model's reasoning to the user. Only few contemporary techniques aim at combining the principles behind both local and global XAI for obtaining more informative explanations. Those methods, however, are often limited to specific model architectures or impose additional requirements on training regimes or data and label availability, which renders the post-hoc application to arbitrarily pre-trained models practically impossible. In this work we introduce the Concept Relevance Propagation (CRP) approach, which combines the local and global perspectives of XAI and thus allows answering both the "where" and "what" questions for individual predictions, without additional constraints imposed. We further introduce the principle of Relevance Maximization for finding representative examples of encoded concepts based on their usefulness to the model. We thereby lift the dependency on the common practice of Activation Maximization and its limitations. We demonstrate the capabilities of our methods in various settings, showcasing that Concept Relevance Propagation and Relevance Maximization lead to more human interpretable explanations and provide deep insights into the model's representations and reasoning through concept atlases, concept composition analyses, and quantitative investigations of concept subspaces and their role in fine-grained decision making.