 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Hidden Context Bias in Segmentation and Object Detection through Concept-specific Explanations
Paper and Code
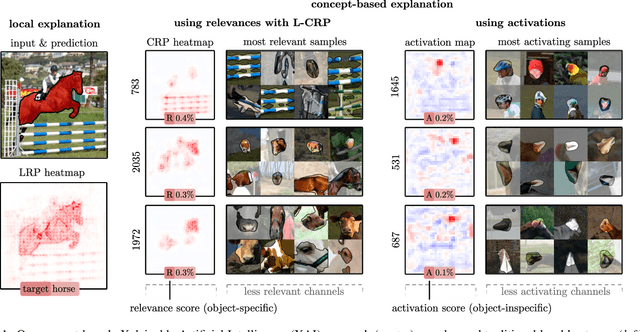


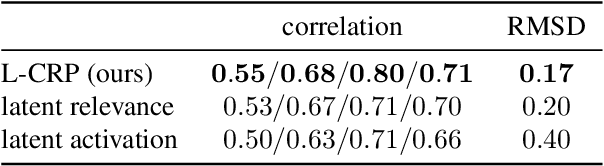
Applying traditional post-hoc attribution methods to segmentation or object detection predictors offers only limited insights, as the obtained feature attribution maps at input level typically resemble the models' predicted segmentation mask or bounding box. In this work, we address the need for more informative explanations for these predictors by proposing the post-hoc eXplainable Artificial Intelligence method L-CRP to generate explanations that automatically identify and visualize relevant concepts learned, recognized and used by the model during inference as well as precisely locate them in input space. Our method therefore goes beyond singular input-level attribution maps and, as an approach based on the recently published Concept Relevance Propagation technique, is efficiently applicable to state-of-the-art black-box architectures in segmentation and object detection, such as DeepLabV3+ and YOLOv6, among others. We verify the faithfulness of our proposed technique by quantitatively comparing different concept attribution methods, and discuss the effect on explanation complexity on popular datasets such as CityScapes, Pascal VOC and MS COCO 2017. The ability to precisely locate and communicate concepts is used to reveal and verify the use of background features, thereby highlighting possible biases of the model.