 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFADE: Why Bad Descriptions Happen to Good Features
Feb 24, 2025Recent advances in mechanistic interpretability have highlighted the potential of automating interpretability pipelines in analyzing the latent representations within LLMs. While they may enhance our understanding of internal mechanisms, the field lacks standardized evaluation methods for assessing the validity of discovered features. We attempt to bridge this gap by introducing FADE: Feature Alignment to Description Evaluation, a scalable model-agnostic framework for evaluating feature-description alignment. FADE evaluates alignment across four key metrics - Clarity, Responsiveness, Purity, and Faithfulness - and systematically quantifies the causes for the misalignment of feature and their description. We apply FADE to analyze existing open-source feature descriptions, and assess key components of automated interpretability pipelines, aiming to enhance the quality of descriptions. Our findings highlight fundamental challenges in generating feature descriptions, particularly for SAEs as compared to MLP neurons, providing insights into the limitations and future directions of automated interpretability. We release FADE as an open-source package at: https://github.com/brunibrun/FADE.
AttnLRP: Attention-Aware Layer-wise Relevance Propagation for Transformers
Feb 08, 2024
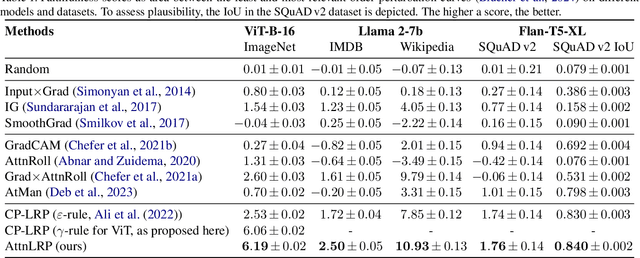
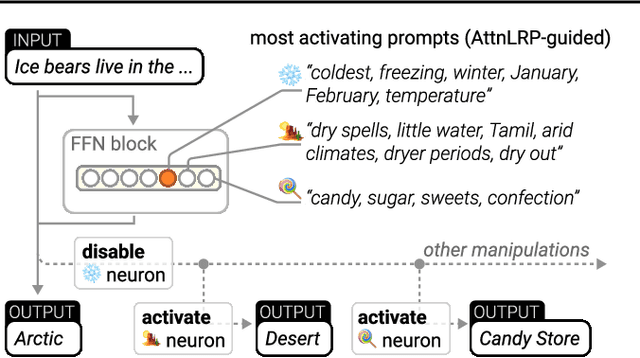

Large Language Models are prone to biased predictions and hallucinations, underlining the paramount importance of understanding their model-internal reasoning process. However, achieving faithful attributions for the entirety of a black-box transformer model and maintaining computational efficiency is an unsolved challenge. By extending the Layer-wise Relevance Propagation attribution method to handle attention layers, we address these challenges effectively. While partial solutions exist, our method is the first to faithfully and holistically attribute not only input but also latent representations of transformer models with the computational efficiency similar to a singular backward pass. Through extensive evaluations against existing methods on Llama 2, Flan-T5 and the Vision Transformer architecture, we demonstrate that our proposed approach surpasses alternative methods in terms of faithfulness and enables the understanding of latent representations, opening up the door for concept-based explanations. We provide an open-source implementation on GitHub https://github.com/rachtibat/LRP-for-Transformers.