 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaying the network backward: A Game Theoretic Attribution Framework
May 07, 2026Attribution methods explain which input features drive a model's prediction, making them central to model debugging and mechanistic interpretability. Yet backward attribution methods, including gradients, LRP, and transformer-specific rules, lack a shared framework in which to compare the underlying backward calculations. We introduce such a framework by recasting backward attribution as a two-player game on an extended network graph, building on Gaubert and Vlassopoulos' ReLU Net Game. Gradients and the full alpha-beta-LRP family arise as integrals over game trajectories under specific equilibria, so attribution maps become projections of trajectory distributions rather than the primary object. Desired explanation properties, such as localisation focus, robustness to input noise, or stable attention routing, can be specified as game-theoretic concepts, including policy regularization, risk aversion, and extended action sets, and translate directly into novel adaptations of the well-known backward rules. On ViT-B/16, one such selected adaptation of alpha-beta-LRP outperforms prior transformer-specific backward methods across all considered localisation metrics.
Contrastive Semantic Projection: Faithful Neuron Labeling with Contrastive Examples
Apr 24, 2026Neuron labeling assigns textual descriptions to internal units of deep networks. Existing approaches typically rely on highly activating examples, often yielding broad or misleading labels by focusing on dominant but incidental visual factors. Prior work such as FALCON introduced contrastive examples -- inputs that are semantically similar to activating examples but elicit low activations -- to sharpen explanations, but it primarily addresses subspace-level interpretability rather than scalable neuron-level labeling. We revisit contrastive explanations for neuron-level labeling in two stages: (1) candidate label generation with vision language models (VLMs) and (2) label assignment with CLIP-like encoders. First, we show that providing contrastive image sets to VLMs yields candidate labels that are more specific and more faithful. Second, we introduce Contrastive Semantic Projection (CSP), an extension of SemanticLens that incorporates contrastive examples directly into its CLIP-based scoring and selection pipeline. Across extensive experiments and a case study on melanoma detection, contrastive labeling improves both faithfulness and semantic granularity over state-of-the-art baselines. Our results demonstrate that contrastive examples are a simple yet powerful and currently underutilized component of neuron labeling and analysis pipelines.
X-SYS: A Reference Architecture for Interactive Explanation Systems
Feb 13, 2026The explainable AI (XAI) research community has proposed numerous technical methods, yet deploying explainability as systems remains challenging: Interactive explanation systems require both suitable algorithms and system capabilities that maintain explanation usability across repeated queries, evolving models and data, and governance constraints. We argue that operationalizing XAI requires treating explainability as an information systems problem where user interaction demands induce specific system requirements. We introduce X-SYS, a reference architecture for interactive explanation systems, that guides (X)AI researchers, developers and practitioners in connecting interactive explanation user interfaces (XUI) with system capabilities. X-SYS organizes around four quality attributes named STAR (scalability, traceability, responsiveness, and adaptability), and specifies a five-component decomposition (XUI Services, Explanation Services, Model Services, Data Services, Orchestration and Governance). It maps interaction patterns to system capabilities to decouple user interface evolution from backend computation. We implement X-SYS through SemanticLens, a system for semantic search and activation steering in vision-language models. SemanticLens demonstrates how contract-based service boundaries enable independent evolution, offline/online separation ensures responsiveness, and persistent state management supports traceability. Together, this work provides a reusable blueprint and concrete instantiation for interactive explanation systems supporting end-to-end design under operational constraints.
Atlas-Alignment: Making Interpretability Transferable Across Language Models
Oct 31, 2025Interpretability is crucial for building safe, reliable, and controllable language models, yet existing interpretability pipelines remain costly and difficult to scale. Interpreting a new model typically requires costly training of model-specific sparse autoencoders, manual or semi-automated labeling of SAE components, and their subsequent validation. We introduce Atlas-Alignment, a framework for transferring interpretability across language models by aligning unknown latent spaces to a Concept Atlas - a labeled, human-interpretable latent space - using only shared inputs and lightweight representational alignment techniques. Once aligned, this enables two key capabilities in previously opaque models: (1) semantic feature search and retrieval, and (2) steering generation along human-interpretable atlas concepts. Through quantitative and qualitative evaluations, we show that simple representational alignment methods enable robust semantic retrieval and steerable generation without the need for labeled concept data. Atlas-Alignment thus amortizes the cost of explainable AI and mechanistic interpretability: by investing in one high-quality Concept Atlas, we can make many new models transparent and controllable at minimal marginal cost.
From What to How: Attributing CLIP's Latent Components Reveals Unexpected Semantic Reliance
May 26, 2025



Transformer-based CLIP models are widely used for text-image probing and feature extraction, making it relevant to understand the internal mechanisms behind their predictions. While recent works show that Sparse Autoencoders (SAEs) yield interpretable latent components, they focus on what these encode and miss how they drive predictions. We introduce a scalable framework that reveals what latent components activate for, how they align with expected semantics, and how important they are to predictions. To achieve this, we adapt attribution patching for instance-wise component attributions in CLIP and highlight key faithfulness limitations of the widely used Logit Lens technique. By combining attributions with semantic alignment scores, we can automatically uncover reliance on components that encode semantically unexpected or spurious concepts. Applied across multiple CLIP variants, our method uncovers hundreds of surprising components linked to polysemous words, compound nouns, visual typography and dataset artifacts. While text embeddings remain prone to semantic ambiguity, they are more robust to spurious correlations compared to linear classifiers trained on image embeddings. A case study on skin lesion detection highlights how such classifiers can amplify hidden shortcuts, underscoring the need for holistic, mechanistic interpretability. We provide code at https://github.com/maxdreyer/attributing-clip.
Mechanistic understanding and validation of large AI models with SemanticLens
Jan 09, 2025

Unlike human-engineered systems such as aeroplanes, where each component's role and dependencies are well understood, the inner workings of AI models remain largely opaque, hindering verifiability and undermining trust. This paper introduces SemanticLens, a universal explanation method for neural networks that maps hidden knowledge encoded by components (e.g., individual neurons) into the semantically structured, multimodal space of a foundation model such as CLIP. In this space, unique operations become possible, including (i) textual search to identify neurons encoding specific concepts, (ii) systematic analysis and comparison of model representations, (iii) automated labelling of neurons and explanation of their functional roles, and (iv) audits to validate decision-making against requirements. Fully scalable and operating without human input, SemanticLens is shown to be effective for debugging and validation, summarizing model knowledge, aligning reasoning with expectations (e.g., adherence to the ABCDE-rule in melanoma classification), and detecting components tied to spurious correlations and their associated training data. By enabling component-level understanding and validation, the proposed approach helps bridge the "trust gap" between AI models and traditional engineered systems. We provide code for SemanticLens on https://github.com/jim-berend/semanticlens and a demo on https://semanticlens.hhi-research-insights.eu.
Beyond Scalars: Concept-Based Alignment Analysis in Vision Transformers
Dec 09, 2024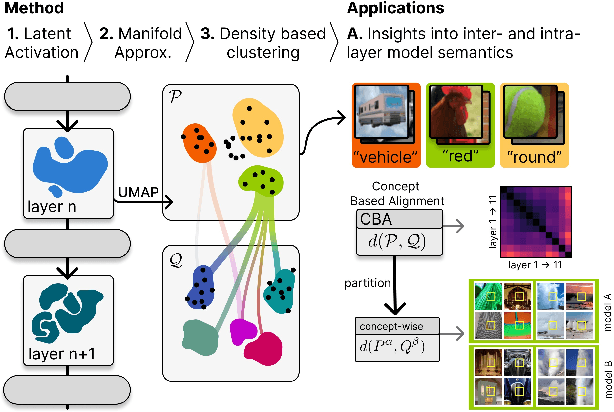
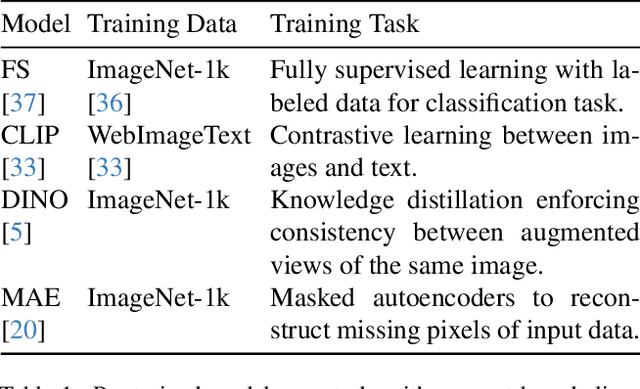
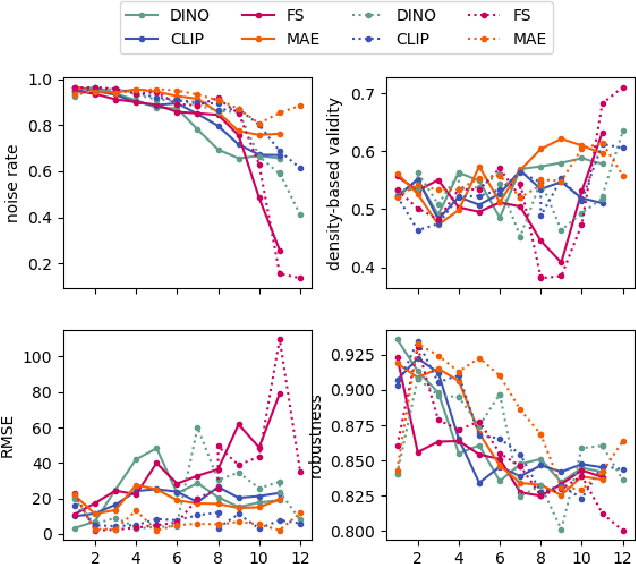
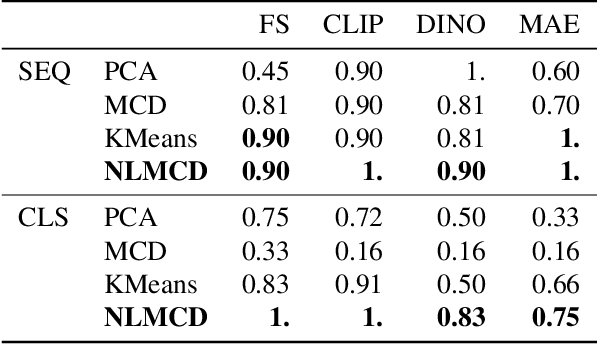
Vision transformers (ViTs) can be trained using various learning paradigms, from fully supervised to self-supervised. Diverse training protocols often result in significantly different feature spaces, which are usually compared through alignment analysis. However, current alignment measures quantify this relationship in terms of a single scalar value, obscuring the distinctions between common and unique features in pairs of representations that share the same scalar alignment. We address this limitation by combining alignment analysis with concept discovery, which enables a breakdown of alignment into single concepts encoded in feature space. This fine-grained comparison reveals both universal and unique concepts across different representations, as well as the internal structure of concepts within each of them. Our methodological contributions address two key prerequisites for concept-based alignment: 1) For a description of the representation in terms of concepts that faithfully capture the geometry of the feature space, we define concepts as the most general structure they can possibly form - arbitrary manifolds, allowing hidden features to be described by their proximity to these manifolds. 2) To measure distances between concept proximity scores of two representations, we use a generalized Rand index and partition it for alignment between pairs of concepts. We confirm the superiority of our novel concept definition for alignment analysis over existing linear baselines in a sanity check. The concept-based alignment analysis of representations from four different ViTs reveals that increased supervision correlates with a reduction in the semantic structure of learned representations.
Layer-wise Feedback Propagation
Aug 23, 2023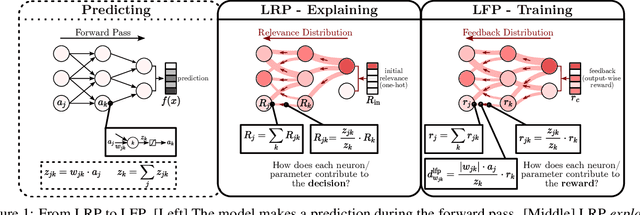
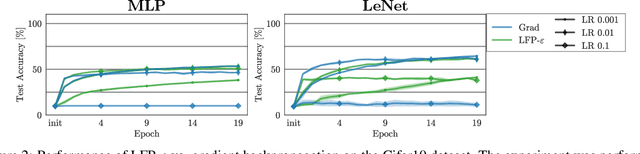
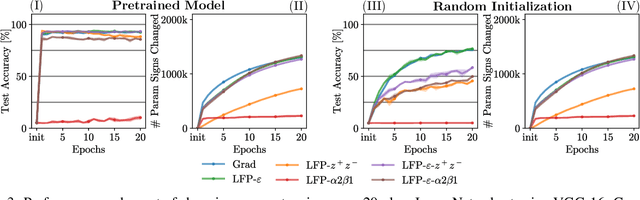
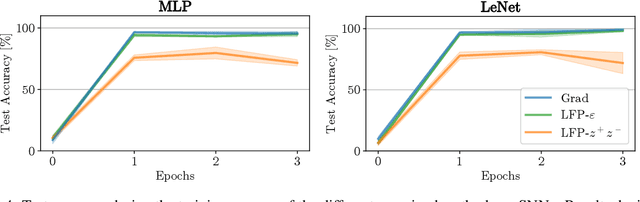
In this paper, we present Layer-wise Feedback Propagation (LFP), a novel training approach for neural-network-like predictors that utilizes explainability, specifically Layer-wise Relevance Propagation(LRP), to assign rewards to individual connections based on their respective contributions to solving a given task. This differs from traditional gradient descent, which updates parameters towards anestimated loss minimum. LFP distributes a reward signal throughout the model without the need for gradient computations. It then strengthens structures that receive positive feedback while reducingthe influence of structures that receive negative feedback. We establish the convergence of LFP theoretically and empirically, and demonstrate its effectiveness in achieving comparable performance to gradient descent on various models and datasets. Notably, LFP overcomes certain limitations associated with gradient-based methods, such as reliance on meaningful derivatives. We further investigate how the different LRP-rules can be extended to LFP, what their effects are on training, as well as potential applications, such as training models with no meaningful derivatives, e.g., step-function activated Spiking Neural Networks (SNNs), or for transfer learning, to efficiently utilize existing knowledge.