 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Scalars: Concept-Based Alignment Analysis in Vision Transformers
Paper and Code
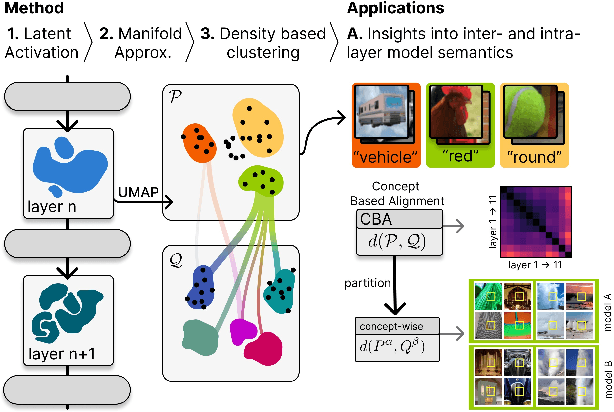
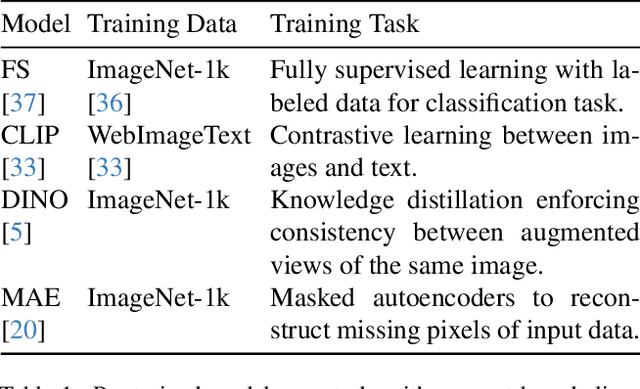
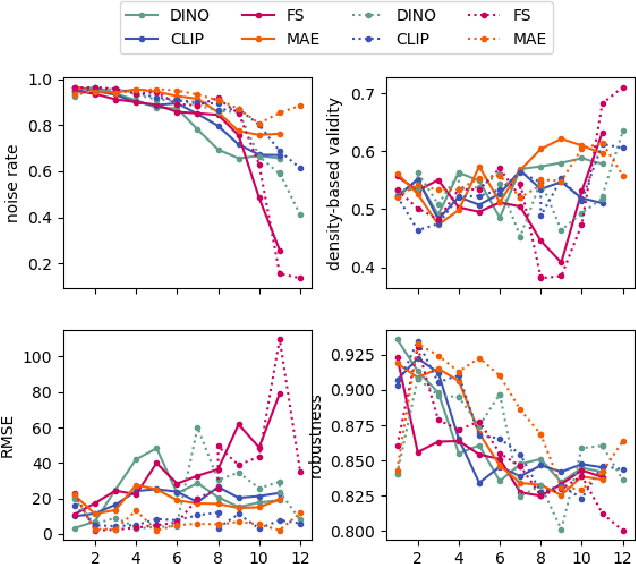
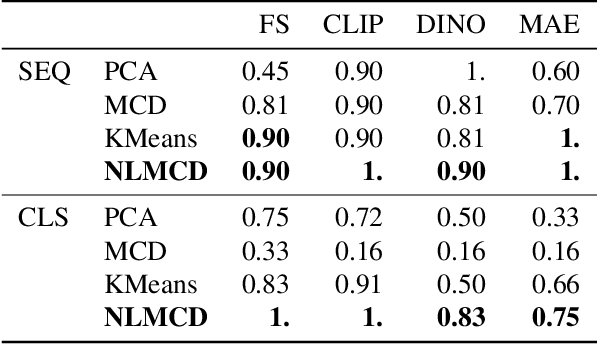
Vision transformers (ViTs) can be trained using various learning paradigms, from fully supervised to self-supervised. Diverse training protocols often result in significantly different feature spaces, which are usually compared through alignment analysis. However, current alignment measures quantify this relationship in terms of a single scalar value, obscuring the distinctions between common and unique features in pairs of representations that share the same scalar alignment. We address this limitation by combining alignment analysis with concept discovery, which enables a breakdown of alignment into single concepts encoded in feature space. This fine-grained comparison reveals both universal and unique concepts across different representations, as well as the internal structure of concepts within each of them. Our methodological contributions address two key prerequisites for concept-based alignment: 1) For a description of the representation in terms of concepts that faithfully capture the geometry of the feature space, we define concepts as the most general structure they can possibly form - arbitrary manifolds, allowing hidden features to be described by their proximity to these manifolds. 2) To measure distances between concept proximity scores of two representations, we use a generalized Rand index and partition it for alignment between pairs of concepts. We confirm the superiority of our novel concept definition for alignment analysis over existing linear baselines in a sanity check. The concept-based alignment analysis of representations from four different ViTs reveals that increased supervision correlates with a reduction in the semantic structure of learned representations.