 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark Problems and Benchmark Datasets for the evaluation of Machine and Deep Learning methods on Photoplethysmography signals: the D4 report from the QUMPHY project
Apr 01, 2026This report is part of the Qumphy project (22HLT01 Qumphy) that is funded by the European Union and is dedicated to the development of measures to quantify the uncertainties associated with Machine Learning algorithms applied to medical problems, in particular the analysis and processing of Photoplethysmography (PPG) signals. In this report, a list of six medical problems that are related to PPG signals and serve as Benchmark Problems is given. Suitable Benchmark datasets and their usage are described also.
Deriving Health Metrics from the Photoplethysmogram: Benchmarks and Insights from MIMIC-III-Ext-PPG
Mar 23, 2026Photoplethysmography (PPG) is one of the most widely captured biosignals for clinical prediction tasks, yet PPG-based algorithms are typically trained on small-scale datasets of uncertain quality, which hinders meaningful algorithm comparisons. We present a comprehensive benchmark for PPG-based clinical prediction using the \dbname~dataset, establishing baselines across the full spectrum of clinically relevant applications: multi-class heart rhythm classification, and regression of physiological parameters including respiratory rate (RR), heart rate (HR), and blood pressure (BP). Most notably, we provide the first comprehensive assessment of PPG for general arrhythmia detection beyond atrial fibrillation (AF) and atrial flutter (AFLT), with performance stratified by BP, HR, and demographic subgroups. Using established deep learning architectures, we achieved strong performance for AF detection (AUROC = 0.96) and accurate physiological parameter estimation (RR MAE: 2.97 bpm; HR MAE: 1.13 bpm; SBP/DBP MAE: 16.13/8.70 mmHg). Cross-dataset validation demonstrates excellent generalizability for AF detection (AUROC = 0.97), while clinical subgroup analysis reveals marked performance differences across subgroups by BP, HR, and demographic strata. These variations appear to reflect population-specific waveform differences rather than systematic bias in model behavior. This framework establishes the first integrated benchmark for multi-task PPG-based clinical prediction, demonstrating that PPG signals can effectively support multiple simultaneous monitoring tasks and providing essential baselines for future algorithm development.
ProtoMask: Segmentation-Guided Prototype Learning
Oct 01, 2025



XAI gained considerable importance in recent years. Methods based on prototypical case-based reasoning have shown a promising improvement in explainability. However, these methods typically rely on additional post-hoc saliency techniques to explain the semantics of learned prototypes. Multiple critiques have been raised about the reliability and quality of such techniques. For this reason, we study the use of prominent image segmentation foundation models to improve the truthfulness of the mapping between embedding and input space. We aim to restrict the computation area of the saliency map to a predefined semantic image patch to reduce the uncertainty of such visualizations. To perceive the information of an entire image, we use the bounding box from each generated segmentation mask to crop the image. Each mask results in an individual input in our novel model architecture named ProtoMask. We conduct experiments on three popular fine-grained classification datasets with a wide set of metrics, providing a detailed overview on explainability characteristics. The comparison with other popular models demonstrates competitive performance and unique explainability features of our model. https://github.com/uos-sis/quanproto
FeatInv: Spatially resolved mapping from feature space to input space using conditional diffusion models
May 27, 2025



Internal representations are crucial for understanding deep neural networks, such as their properties and reasoning patterns, but remain difficult to interpret. While mapping from feature space to input space aids in interpreting the former, existing approaches often rely on crude approximations. We propose using a conditional diffusion model - a pretrained high-fidelity diffusion model conditioned on spatially resolved feature maps - to learn such a mapping in a probabilistic manner. We demonstrate the feasibility of this approach across various pretrained image classifiers from CNNs to ViTs, showing excellent reconstruction capabilities. Through qualitative comparisons and robustness analysis, we validate our method and showcase possible applications, such as the visualization of concept steering in input space or investigations of the composite nature of the feature space. This approach has broad potential for improving feature space understanding in computer vision models.
Uncertainty quantification with approximate variational learning for wearable photoplethysmography prediction tasks
May 16, 2025Photoplethysmography (PPG) signals encode information about relative changes in blood volume that can be used to assess various aspects of cardiac health non-invasively, e.g.\ to detect atrial fibrillation (AF) or predict blood pressure (BP). Deep networks are well-equipped to handle the large quantities of data acquired from wearable measurement devices. However, they lack interpretability and are prone to overfitting, leaving considerable risk for poor performance on unseen data and misdiagnosis. Here, we describe the use of two scalable uncertainty quantification techniques: Monte Carlo Dropout and the recently proposed Improved Variational Online Newton. These techniques are used to assess the trustworthiness of models trained to perform AF classification and BP regression from raw PPG time series. We find that the choice of hyperparameters has a considerable effect on the predictive performance of the models and on the quality and composition of predicted uncertainties. E.g. the stochasticity of the model parameter sampling determines the proportion of the total uncertainty that is aleatoric, and has varying effects on predictive performance and calibration quality dependent on the chosen uncertainty quantification technique and the chosen expression of uncertainty. We find significant discrepancy in the quality of uncertainties over the predicted classes, emphasising the need for a thorough evaluation protocol that assesses local and adaptive calibration. This work suggests that the choice of hyperparameters must be carefully tuned to balance predictive performance and calibration quality, and that the optimal parameterisation may vary depending on the chosen expression of uncertainty.
Machine-learning for photoplethysmography analysis: Benchmarking feature, image, and signal-based approaches
Feb 27, 2025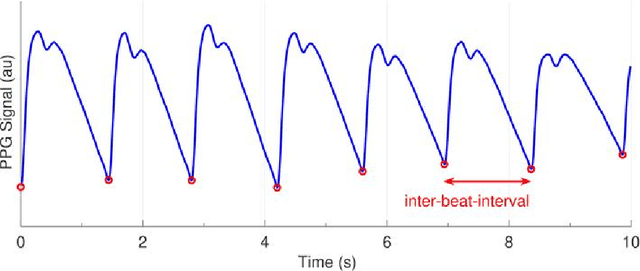

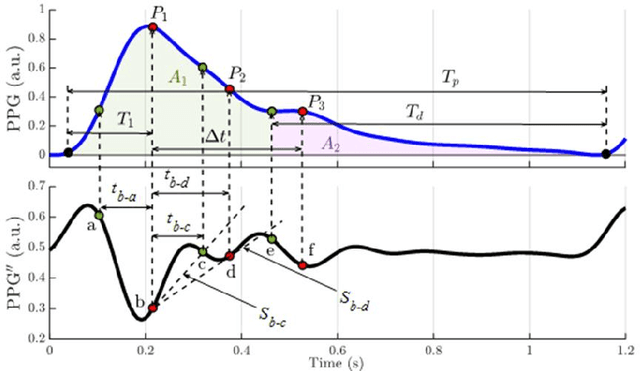
Photoplethysmography (PPG) is a widely used non-invasive physiological sensing technique, suitable for various clinical applications. Such clinical applications are increasingly supported by machine learning methods, raising the question of the most appropriate input representation and model choice. Comprehensive comparisons, in particular across different input representations, are scarce. We address this gap in the research landscape by a comprehensive benchmarking study covering three kinds of input representations, interpretable features, image representations and raw waveforms, across prototypical regression and classification use cases: blood pressure and atrial fibrillation prediction. In both cases, the best results are achieved by deep neural networks operating on raw time series as input representations. Within this model class, best results are achieved by modern convolutional neural networks (CNNs). but depending on the task setup, shallow CNNs are often also very competitive. We envision that these results will be insightful for researchers to guide their choice on machine learning tasks for PPG data, even beyond the use cases presented in this work.
Generalizable deep learning for photoplethysmography-based blood pressure estimation -- A Benchmarking Study
Feb 26, 2025Photoplethysmography (PPG)-based blood pressure (BP) estimation represents a promising alternative to cuff-based BP measurements. Recently, an increasing number of deep learning models have been proposed to infer BP from the raw PPG waveform. However, these models have been predominantly evaluated on in-distribution test sets, which immediately raises the question of the generalizability of these models to external datasets. To investigate this question, we trained five deep learning models on the recently released PulseDB dataset, provided in-distribution benchmarking results on this dataset, and then assessed out-of-distribution performance on several external datasets. The best model (XResNet1d101) achieved in-distribution MAEs of 9.4 and 6.0 mmHg for systolic and diastolic BP respectively on PulseDB (with subject-specific calibration), and 14.0 and 8.5 mmHg respectively without calibration. Equivalent MAEs on external test datasets without calibration ranged from 15.0 to 25.1 mmHg (SBP) and 7.0 to 10.4 mmHg (DBP). Our results indicate that the performance is strongly influenced by the differences in BP distributions between datasets. We investigated a simple way of improving performance through sample-based domain adaptation and put forward recommendations for training models with good generalization properties. With this work, we hope to educate more researchers for the importance and challenges of out-of-distribution generalization.
Benchmarking machine learning for bowel sound pattern classification from tabular features to pretrained models
Feb 21, 2025The development of electronic stethoscopes and wearable recording sensors opened the door to the automated analysis of bowel sound (BS) signals. This enables a data-driven analysis of bowel sound patterns, their interrelations, and their correlation to different pathologies. This work leverages a BS dataset collected from 16 healthy subjects that was annotated according to four established BS patterns. This dataset is used to evaluate the performance of machine learning models to detect and/or classify BS patterns. The selection of considered models covers models using tabular features, convolutional neural networks based on spectrograms and models pre-trained on large audio datasets. The results highlight the clear superiority of pre-trained models, particularly in detecting classes with few samples, achieving an AUC of 0.89 in distinguishing BS from non-BS using a HuBERT model and an AUC of 0.89 in differentiating bowel sound patterns using a Wav2Vec 2.0 model. These results pave the way for an improved understanding of bowel sounds in general and future machine-learning-driven diagnostic applications for gastrointestinal examinations
Explainable and externally validated machine learning for neuropsychiatric diagnosis via electrocardiograms
Feb 07, 2025



Electrocardiogram (ECG) analysis has emerged as a promising tool for identifying physiological changes associated with neuropsychiatric conditions. The relationship between cardiovascular health and neuropsychiatric disorders suggests that ECG abnormalities could serve as valuable biomarkers for more efficient detection, therapy monitoring, and risk stratification. However, the potential of the ECG to accurately distinguish neuropsychiatric conditions, particularly among diverse patient populations, remains underexplored. This study utilized ECG markers and basic demographic data to predict neuropsychiatric conditions using machine learning models, with targets defined through ICD-10 codes. Both internal and external validation were performed using the MIMIC-IV and ECG-View datasets respectively. Performance was assessed using AUROC scores. To enhance model interpretability, Shapley values were applied to provide insights into the contributions of individual ECG features to the predictions. Significant predictive performance was observed for conditions within the neurological and psychiatric groups. For the neurological group, Alzheimer's disease (G30) achieved an internal AUROC of 0.813 (0.812-0.814) and an external AUROC of 0.868 (0.867-0.868). In the psychiatric group, unspecified dementia (F03) showed an internal AUROC of 0.849 (0.848-0.849) and an external AUROC of 0.862 (0.861-0.863). Discriminative features align with known ECG markers but also provide hints on potentially new markers. ECG offers significant promise for diagnosing and monitoring neuropsychiatric conditions, with robust predictive performance across internal and external cohorts. Future work should focus on addressing potential confounders, such as therapy-related cardiotoxicity, and expanding the scope of ECG applications, including personalized care and early intervention strategies.
Explainable machine learning for neoplasms diagnosis via electrocardiograms: an externally validated study
Dec 10, 2024



Background: Neoplasms remains a leading cause of mortality worldwide, with timely diagnosis being crucial for improving patient outcomes. Current diagnostic methods are often invasive, costly, and inaccessible to many populations. Electrocardiogram (ECG) data, widely available and non-invasive, has the potential to serve as a tool for neoplasms diagnosis by using physiological changes in cardiovascular function associated with neoplastic prescences. Methods: This study explores the application of machine learning models to analyze ECG features for the diagnosis of neoplasms. We developed a pipeline integrating tree-based models with Shapley values for explainability. The model was trained and internally validated and externally validated on a second large-scale independent external cohort to ensure robustness and generalizability. Findings: The results demonstrate that ECG data can effectively capture neoplasms-associated cardiovascular changes, achieving high performance in both internal testing and external validation cohorts. Shapley values identified key ECG features influencing model predictions, revealing established and novel cardiovascular markers linked to neoplastic conditions. This non-invasive approach provides a cost-effective and scalable alternative for the diagnosis of neoplasms, particularly in resource-limited settings. Similarly, useful for the management of secondary cardiovascular effects given neoplasms therapies. Interpretation: This study highlights the feasibility of leveraging ECG signals and machine learning to enhance neoplasms diagnostics. By offering interpretable insights into cardio-neoplasms interactions, this approach bridges existing gaps in non-invasive diagnostics and has implications for integrating ECG-based tools into broader neoplasms diagnostic frameworks, as well as neoplasms therapy management.