 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty quantification with approximate variational learning for wearable photoplethysmography prediction tasks
May 16, 2025Photoplethysmography (PPG) signals encode information about relative changes in blood volume that can be used to assess various aspects of cardiac health non-invasively, e.g.\ to detect atrial fibrillation (AF) or predict blood pressure (BP). Deep networks are well-equipped to handle the large quantities of data acquired from wearable measurement devices. However, they lack interpretability and are prone to overfitting, leaving considerable risk for poor performance on unseen data and misdiagnosis. Here, we describe the use of two scalable uncertainty quantification techniques: Monte Carlo Dropout and the recently proposed Improved Variational Online Newton. These techniques are used to assess the trustworthiness of models trained to perform AF classification and BP regression from raw PPG time series. We find that the choice of hyperparameters has a considerable effect on the predictive performance of the models and on the quality and composition of predicted uncertainties. E.g. the stochasticity of the model parameter sampling determines the proportion of the total uncertainty that is aleatoric, and has varying effects on predictive performance and calibration quality dependent on the chosen uncertainty quantification technique and the chosen expression of uncertainty. We find significant discrepancy in the quality of uncertainties over the predicted classes, emphasising the need for a thorough evaluation protocol that assesses local and adaptive calibration. This work suggests that the choice of hyperparameters must be carefully tuned to balance predictive performance and calibration quality, and that the optimal parameterisation may vary depending on the chosen expression of uncertainty.
Machine-learning for photoplethysmography analysis: Benchmarking feature, image, and signal-based approaches
Feb 27, 2025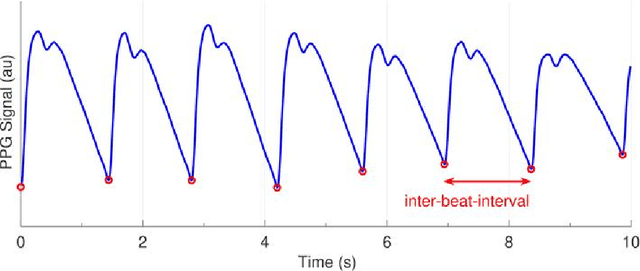

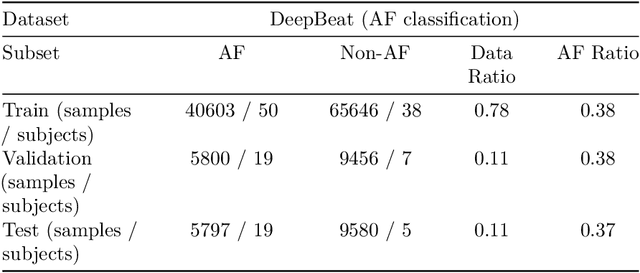
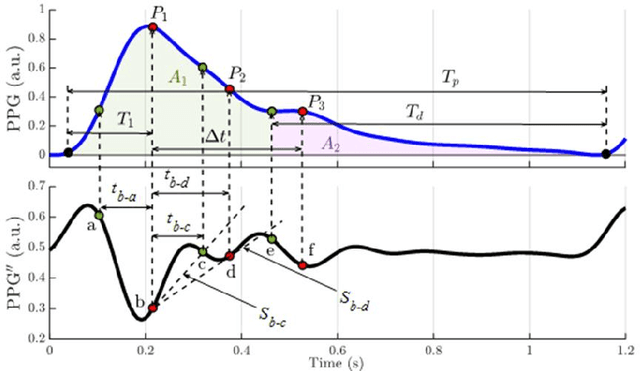
Photoplethysmography (PPG) is a widely used non-invasive physiological sensing technique, suitable for various clinical applications. Such clinical applications are increasingly supported by machine learning methods, raising the question of the most appropriate input representation and model choice. Comprehensive comparisons, in particular across different input representations, are scarce. We address this gap in the research landscape by a comprehensive benchmarking study covering three kinds of input representations, interpretable features, image representations and raw waveforms, across prototypical regression and classification use cases: blood pressure and atrial fibrillation prediction. In both cases, the best results are achieved by deep neural networks operating on raw time series as input representations. Within this model class, best results are achieved by modern convolutional neural networks (CNNs). but depending on the task setup, shallow CNNs are often also very competitive. We envision that these results will be insightful for researchers to guide their choice on machine learning tasks for PPG data, even beyond the use cases presented in this work.
Generalizable deep learning for photoplethysmography-based blood pressure estimation -- A Benchmarking Study
Feb 26, 2025Photoplethysmography (PPG)-based blood pressure (BP) estimation represents a promising alternative to cuff-based BP measurements. Recently, an increasing number of deep learning models have been proposed to infer BP from the raw PPG waveform. However, these models have been predominantly evaluated on in-distribution test sets, which immediately raises the question of the generalizability of these models to external datasets. To investigate this question, we trained five deep learning models on the recently released PulseDB dataset, provided in-distribution benchmarking results on this dataset, and then assessed out-of-distribution performance on several external datasets. The best model (XResNet1d101) achieved in-distribution MAEs of 9.4 and 6.0 mmHg for systolic and diastolic BP respectively on PulseDB (with subject-specific calibration), and 14.0 and 8.5 mmHg respectively without calibration. Equivalent MAEs on external test datasets without calibration ranged from 15.0 to 25.1 mmHg (SBP) and 7.0 to 10.4 mmHg (DBP). Our results indicate that the performance is strongly influenced by the differences in BP distributions between datasets. We investigated a simple way of improving performance through sample-based domain adaptation and put forward recommendations for training models with good generalization properties. With this work, we hope to educate more researchers for the importance and challenges of out-of-distribution generalization.