 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeatInv: Spatially resolved mapping from feature space to input space using conditional diffusion models
May 27, 2025



Internal representations are crucial for understanding deep neural networks, such as their properties and reasoning patterns, but remain difficult to interpret. While mapping from feature space to input space aids in interpreting the former, existing approaches often rely on crude approximations. We propose using a conditional diffusion model - a pretrained high-fidelity diffusion model conditioned on spatially resolved feature maps - to learn such a mapping in a probabilistic manner. We demonstrate the feasibility of this approach across various pretrained image classifiers from CNNs to ViTs, showing excellent reconstruction capabilities. Through qualitative comparisons and robustness analysis, we validate our method and showcase possible applications, such as the visualization of concept steering in input space or investigations of the composite nature of the feature space. This approach has broad potential for improving feature space understanding in computer vision models.
Mechanistic understanding and validation of large AI models with SemanticLens
Jan 09, 2025

Unlike human-engineered systems such as aeroplanes, where each component's role and dependencies are well understood, the inner workings of AI models remain largely opaque, hindering verifiability and undermining trust. This paper introduces SemanticLens, a universal explanation method for neural networks that maps hidden knowledge encoded by components (e.g., individual neurons) into the semantically structured, multimodal space of a foundation model such as CLIP. In this space, unique operations become possible, including (i) textual search to identify neurons encoding specific concepts, (ii) systematic analysis and comparison of model representations, (iii) automated labelling of neurons and explanation of their functional roles, and (iv) audits to validate decision-making against requirements. Fully scalable and operating without human input, SemanticLens is shown to be effective for debugging and validation, summarizing model knowledge, aligning reasoning with expectations (e.g., adherence to the ABCDE-rule in melanoma classification), and detecting components tied to spurious correlations and their associated training data. By enabling component-level understanding and validation, the proposed approach helps bridge the "trust gap" between AI models and traditional engineered systems. We provide code for SemanticLens on https://github.com/jim-berend/semanticlens and a demo on https://semanticlens.hhi-research-insights.eu.
Beyond Scalars: Concept-Based Alignment Analysis in Vision Transformers
Dec 09, 2024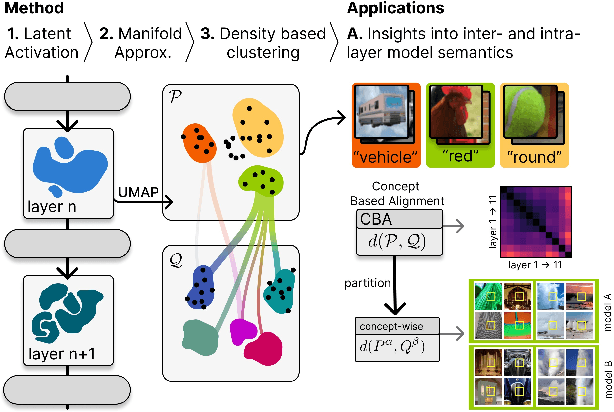
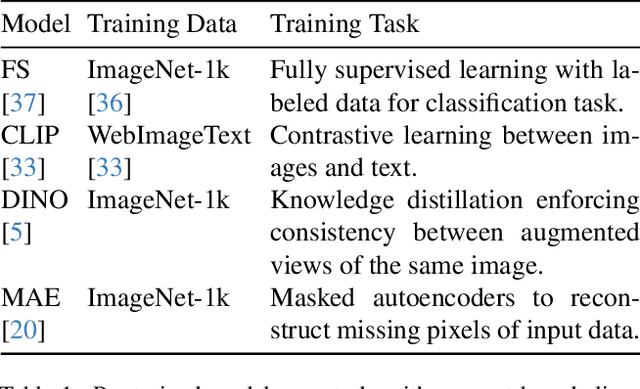
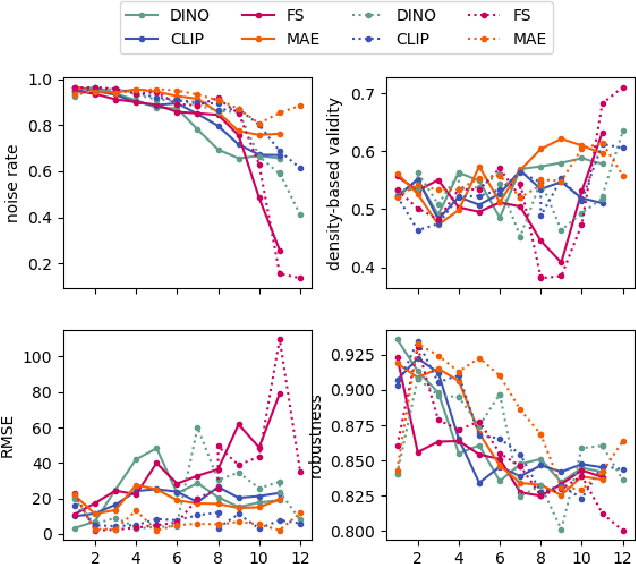
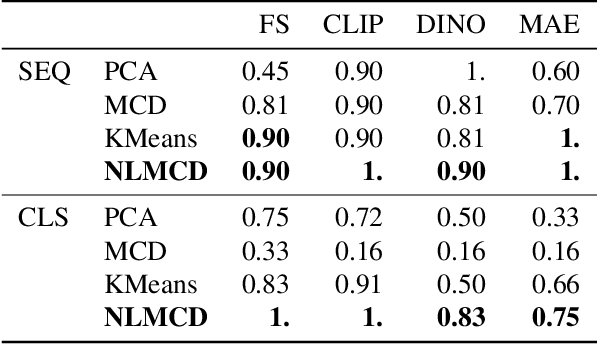
Vision transformers (ViTs) can be trained using various learning paradigms, from fully supervised to self-supervised. Diverse training protocols often result in significantly different feature spaces, which are usually compared through alignment analysis. However, current alignment measures quantify this relationship in terms of a single scalar value, obscuring the distinctions between common and unique features in pairs of representations that share the same scalar alignment. We address this limitation by combining alignment analysis with concept discovery, which enables a breakdown of alignment into single concepts encoded in feature space. This fine-grained comparison reveals both universal and unique concepts across different representations, as well as the internal structure of concepts within each of them. Our methodological contributions address two key prerequisites for concept-based alignment: 1) For a description of the representation in terms of concepts that faithfully capture the geometry of the feature space, we define concepts as the most general structure they can possibly form - arbitrary manifolds, allowing hidden features to be described by their proximity to these manifolds. 2) To measure distances between concept proximity scores of two representations, we use a generalized Rand index and partition it for alignment between pairs of concepts. We confirm the superiority of our novel concept definition for alignment analysis over existing linear baselines in a sanity check. The concept-based alignment analysis of representations from four different ViTs reveals that increased supervision correlates with a reduction in the semantic structure of learned representations.
PURE: Turning Polysemantic Neurons Into Pure Features by Identifying Relevant Circuits
Apr 09, 2024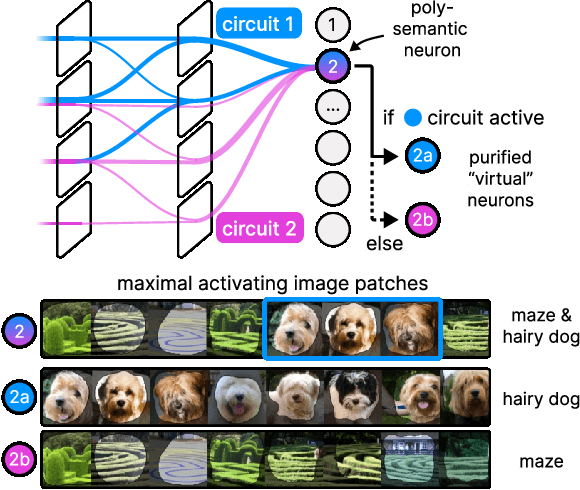
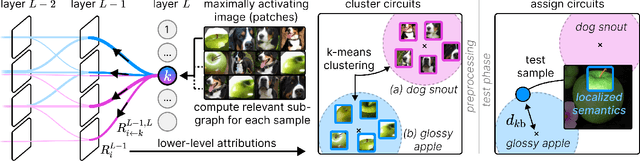

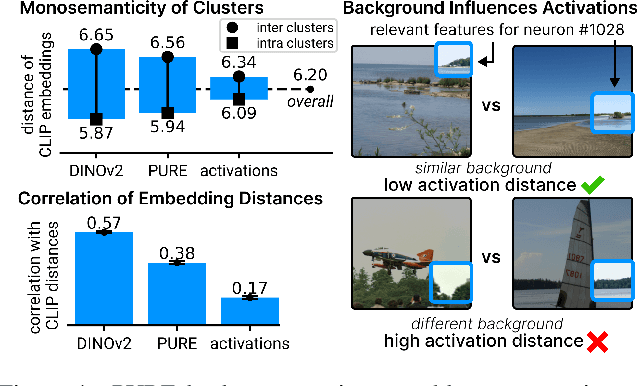
The field of mechanistic interpretability aims to study the role of individual neurons in Deep Neural Networks. Single neurons, however, have the capability to act polysemantically and encode for multiple (unrelated) features, which renders their interpretation difficult. We present a method for disentangling polysemanticity of any Deep Neural Network by decomposing a polysemantic neuron into multiple monosemantic "virtual" neurons. This is achieved by identifying the relevant sub-graph ("circuit") for each "pure" feature. We demonstrate how our approach allows us to find and disentangle various polysemantic units of ResNet models trained on ImageNet. While evaluating feature visualizations using CLIP, our method effectively disentangles representations, improving upon methods based on neuron activations. Our code is available at https://github.com/maxdreyer/PURE.
Decoupling Pixel Flipping and Occlusion Strategy for Consistent XAI Benchmarks
Jan 12, 2024
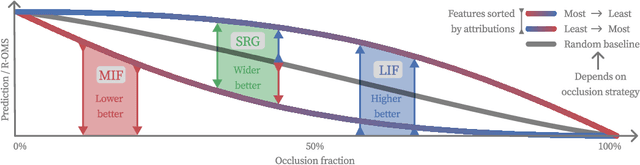


Feature removal is a central building block for eXplainable AI (XAI), both for occlusion-based explanations (Shapley values) as well as their evaluation (pixel flipping, PF). However, occlusion strategies can vary significantly from simple mean replacement up to inpainting with state-of-the-art diffusion models. This ambiguity limits the usefulness of occlusion-based approaches. For example, PF benchmarks lead to contradicting rankings. This is amplified by competing PF measures: Features are either removed starting with most influential first (MIF) or least influential first (LIF). This study proposes two complementary perspectives to resolve this disagreement problem. Firstly, we address the common criticism of occlusion-based XAI, that artificial samples lead to unreliable model evaluations. We propose to measure the reliability by the R(eference)-Out-of-Model-Scope (OMS) score. The R-OMS score enables a systematic comparison of occlusion strategies and resolves the disagreement problem by grouping consistent PF rankings. Secondly, we show that the insightfulness of MIF and LIF is conversely dependent on the R-OMS score. To leverage this, we combine the MIF and LIF measures into the symmetric relevance gain (SRG) measure. This breaks the inherent connection to the underlying occlusion strategy and leads to consistent rankings. This resolves the disagreement problem, which we verify for a set of 40 different occlusion strategies.
XAI-based Comparison of Input Representations for Audio Event Classification
Apr 27, 2023
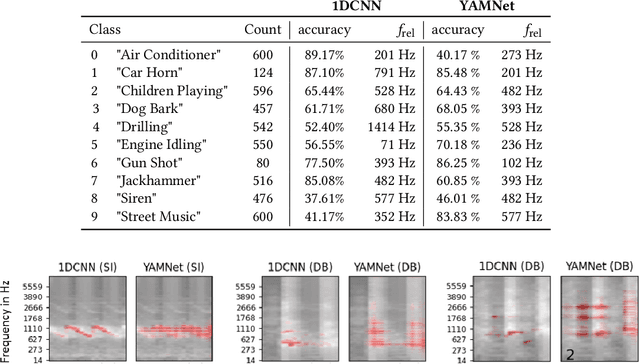

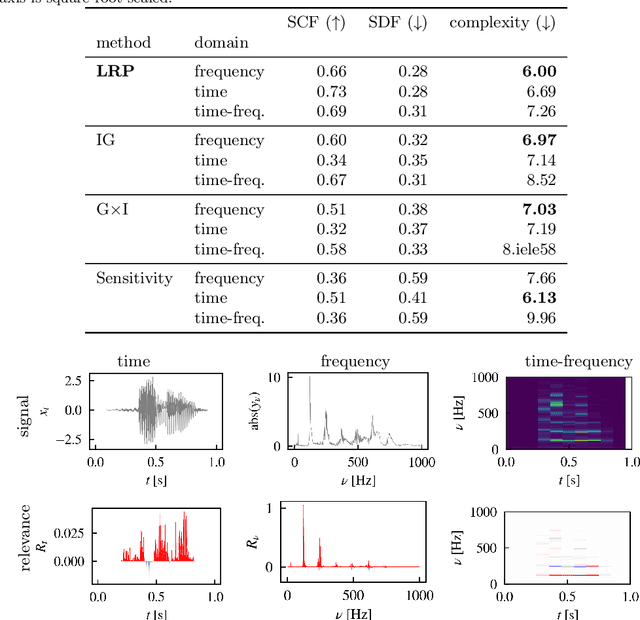
Deep neural networks are a promising tool for Audio Event Classification. In contrast to other data like natural images, there are many sensible and non-obvious representations for audio data, which could serve as input to these models. Due to their black-box nature, the effect of different input representations has so far mostly been investigated by measuring classification performance. In this work, we leverage eXplainable AI (XAI), to understand the underlying classification strategies of models trained on different input representations. Specifically, we compare two model architectures with regard to relevant input features used for Audio Event Detection: one directly processes the signal as the raw waveform, and the other takes in its time-frequency spectrogram representation. We show how relevance heatmaps obtained via "Siren"{Layer-wise Relevance Propagation} uncover representation-dependent decision strategies. With these insights, we can make a well-informed decision about the best input representation in terms of robustness and representativity and confirm that the model's classification strategies align with human requirements.
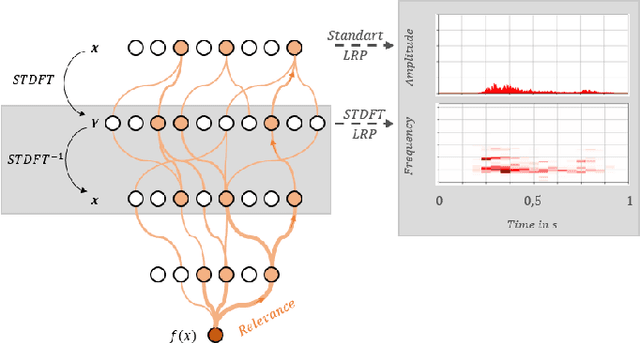
Explainable AI for Time Series via Virtual Inspection Layers
Mar 11, 2023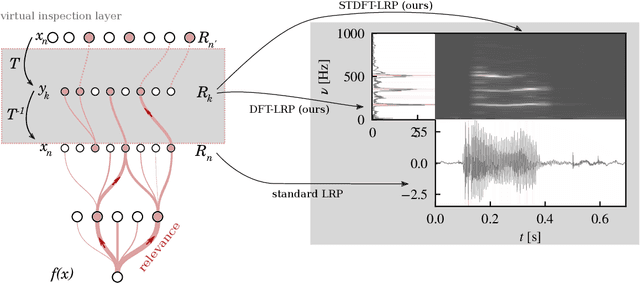
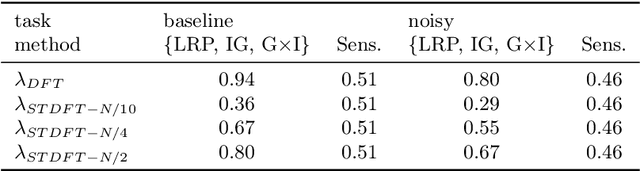
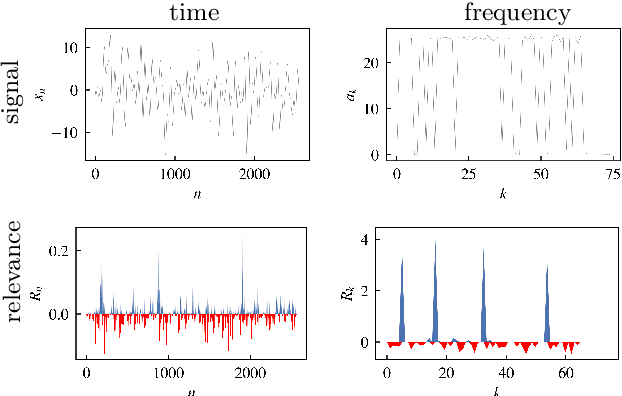
The field of eXplainable Artificial Intelligence (XAI) has greatly advanced in recent years, but progress has mainly been made in computer vision and natural language processing. For time series, where the input is often not interpretable, only limited research on XAI is available. In this work, we put forward a virtual inspection layer, that transforms the time series to an interpretable representation and allows to propagate relevance attributions to this representation via local XAI methods like layer-wise relevance propagation (LRP). In this way, we extend the applicability of a family of XAI methods to domains (e.g. speech) where the input is only interpretable after a transformation. Here, we focus on the Fourier transformation which is prominently applied in the interpretation of time series and LRP and refer to our method as DFT-LRP. We demonstrate the usefulness of DFT-LRP in various time series classification settings like audio and electronic health records. We showcase how DFT-LRP reveals differences in the classification strategies of models trained in different domains (e.g., time vs. frequency domain) or helps to discover how models act on spurious correlations in the data.
Multi-dimensional concept discovery (MCD): A unifying framework with completeness guarantees
Jan 27, 2023



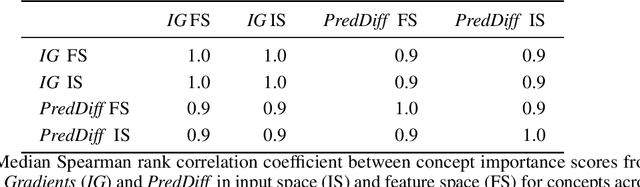
The completeness axiom renders the explanation of a post-hoc XAI method only locally faithful to the model, i.e. for a single decision. For the trustworthy application of XAI, in particular for high-stake decisions, a more global model understanding is required. Recently, concept-based methods have been proposed, which are however not guaranteed to be bound to the actual model reasoning. To circumvent this problem, we propose Multi-dimensional Concept Discovery (MCD) as an extension of previous approaches that fulfills a completeness relation on the level of concepts. Our method starts from general linear subspaces as concepts and does neither require reinforcing concept interpretability nor re-training of model parts. We propose sparse subspace clustering to discover improved concepts and fully leverage the potential of multi-dimensional subspaces. MCD offers two complementary analysis tools for concepts in input space: (1) concept activation maps, that show where a concept is expressed within a sample, allowing for concept characterization through prototypical samples, and (2) concept relevance heatmaps, that decompose the model decision into concept contributions. Both tools together enable a detailed understanding of the model reasoning, which is guaranteed to relate to the model via a completeness relation. This paves the way towards more trustworthy concept-based XAI. We empirically demonstrate the superiority of MCD against more constrained concept definitions.
Sparse Subspace Clustering for Concept Discovery (SSCCD)
Mar 11, 2022
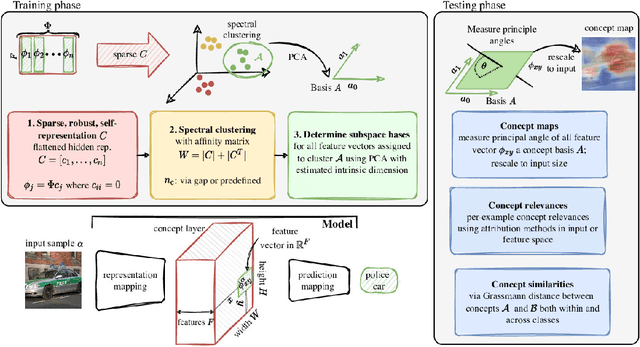

Concepts are key building blocks of higher level human understanding. Explainable AI (XAI) methods have shown tremendous progress in recent years, however, local attribution methods do not allow to identify coherent model behavior across samples and therefore miss this essential component. In this work, we study concept-based explanations and put forward a new definition of concepts as low-dimensional subspaces of hidden feature layers. We novelly apply sparse subspace clustering to discover these concept subspaces. Moving forward, we derive insights from concept subspaces in terms of localized input (concept) maps, show how to quantify concept relevances and lastly, evaluate similarities and transferability between concepts. We empirically demonstrate the soundness of the proposed Sparse Subspace Clustering for Concept Discovery (SSCCD) method for a variety of different image classification tasks. This approach allows for deeper insights into the actual model behavior that would remain hidden from conventional input-level heatmaps.
Predicting the Binding of SARS-CoV-2 Peptides to the Major Histocompatibility Complex with Recurrent Neural Networks
Apr 16, 2021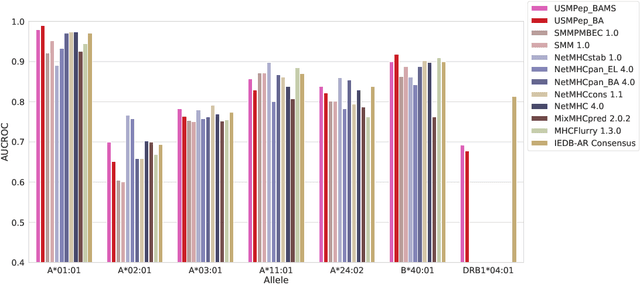
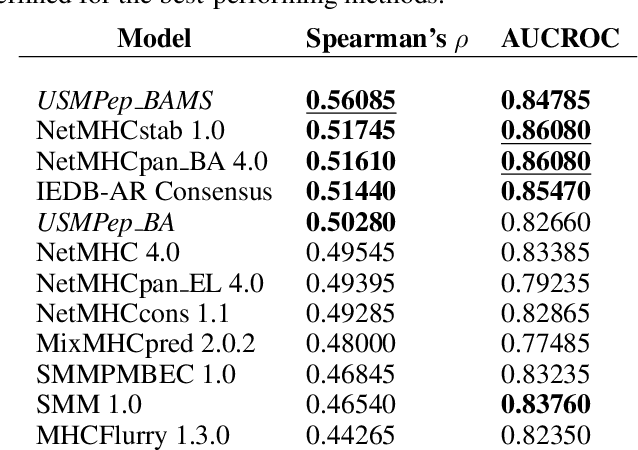
Predicting the binding of viral peptides to the major histocompatibility complex with machine learning can potentially extend the computational immunology toolkit for vaccine development, and serve as a key component in the fight against a pandemic. In this work, we adapt and extend USMPep, a recently proposed, conceptually simple prediction algorithm based on recurrent neural networks. Most notably, we combine regressors (binding affinity data) and classifiers (mass spectrometry data) from qualitatively different data sources to obtain a more comprehensive prediction tool. We evaluate the performance on a recently released SARS-CoV-2 dataset with binding stability measurements. USMPep not only sets new benchmarks on selected single alleles, but consistently turns out to be among the best-performing methods or, for some metrics, to be even the overall best-performing method for this task.