 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXAI-based Comparison of Input Representations for Audio Event Classification
Apr 27, 2023
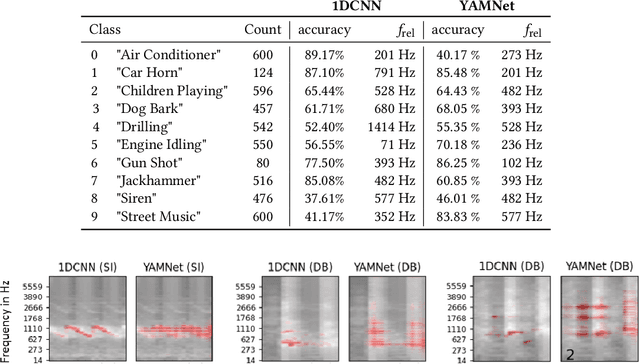
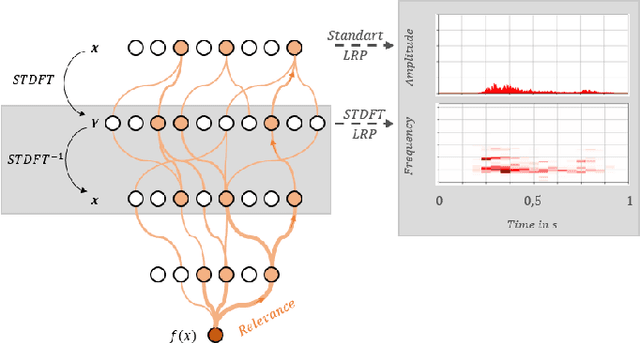

Deep neural networks are a promising tool for Audio Event Classification. In contrast to other data like natural images, there are many sensible and non-obvious representations for audio data, which could serve as input to these models. Due to their black-box nature, the effect of different input representations has so far mostly been investigated by measuring classification performance. In this work, we leverage eXplainable AI (XAI), to understand the underlying classification strategies of models trained on different input representations. Specifically, we compare two model architectures with regard to relevant input features used for Audio Event Detection: one directly processes the signal as the raw waveform, and the other takes in its time-frequency spectrogram representation. We show how relevance heatmaps obtained via "Siren"{Layer-wise Relevance Propagation} uncover representation-dependent decision strategies. With these insights, we can make a well-informed decision about the best input representation in terms of robustness and representativity and confirm that the model's classification strategies align with human requirements.
From CNNs to Vision Transformers -- A Comprehensive Evaluation of Deep Learning Models for Histopathology
Apr 11, 2022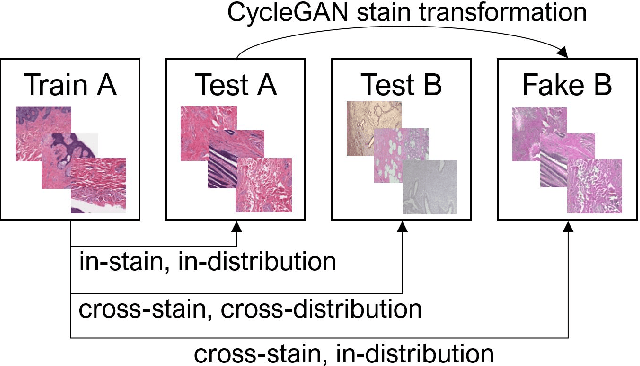



While machine learning is currently transforming the field of histopathology, the domain lacks a comprehensive evaluation of state-of-the-art models based on essential but complementary quality requirements beyond a mere classification accuracy. In order to fill this gap, we conducted an extensive evaluation by benchmarking a wide range of classification models, including recent vision transformers, convolutional neural networks and hybrid models comprising transformer and convolutional models. We thoroughly tested the models on five widely used histopathology datasets containing whole slide images of breast, gastric, and colorectal cancer and developed a novel approach using an image-to-image translation model to assess the robustness of a cancer classification model against stain variations. Further, we extended existing interpretability methods to previously unstudied models and systematically reveal insights of the models' classification strategies that allow for plausibility checks and systematic comparisons. The study resulted in specific model recommendations for practitioners as well as putting forward a general methodology to quantify a model's quality according to complementary requirements that can be transferred to future model architectures.