 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Compactness as a Complementary Criterion for Explanation Quality
Mar 31, 2026In the evaluation of attribution quality, the quantitative assessment of explanation legibility is particularly difficult, as it is influenced by varying shapes and internal organization of attributions not captured by simple statistics. To address this issue, we introduce Minimum Spanning Tree Compactness (MST-C), a graph-based structural metric that captures higher-order geometric properties of attributions, such as spread and cohesion. These components are combined into a single score that evaluates compactness, favoring attributions with salient points spread across a small area and spatially organized into few but cohesive clusters. We show that MST-C reliably distinguishes between explanation methods, exposes fundamental structural differences between models, and provides a robust, self-contained diagnostic for explanation compactness that complements existing notions of attribution complexity.
Relevance-driven Input Dropout: an Explanation-guided Regularization Technique
May 27, 2025Overfitting is a well-known issue extending even to state-of-the-art (SOTA) Machine Learning (ML) models, resulting in reduced generalization, and a significant train-test performance gap. Mitigation measures include a combination of dropout, data augmentation, weight decay, and other regularization techniques. Among the various data augmentation strategies, occlusion is a prominent technique that typically focuses on randomly masking regions of the input during training. Most of the existing literature emphasizes randomness in selecting and modifying the input features instead of regions that strongly influence model decisions. We propose Relevance-driven Input Dropout (RelDrop), a novel data augmentation method which selectively occludes the most relevant regions of the input, nudging the model to use other important features in the prediction process, thus improving model generalization through informed regularization. We further conduct qualitative and quantitative analyses to study how Relevance-driven Input Dropout (RelDrop) affects model decision-making. Through a series of experiments on benchmark datasets, we demonstrate that our approach improves robustness towards occlusion, results in models utilizing more features within the region of interest, and boosts inference time generalization performance. Our code is available at https://github.com/Shreyas-Gururaj/LRP_Relevance_Dropout.
A Fresh Look at Sanity Checks for Saliency Maps
May 03, 2024The Model Parameter Randomisation Test (MPRT) is highly recognised in the eXplainable Artificial Intelligence (XAI) community due to its fundamental evaluative criterion: explanations should be sensitive to the parameters of the model they seek to explain. However, recent studies have raised several methodological concerns for the empirical interpretation of MPRT. In response, we propose two modifications to the original test: Smooth MPRT and Efficient MPRT. The former reduces the impact of noise on evaluation outcomes via sampling, while the latter avoids the need for biased similarity measurements by re-interpreting the test through the increase in explanation complexity after full model randomisation. Our experiments show that these modifications enhance the metric reliability, facilitating a more trustworthy deployment of explanation methods.
Sanity Checks Revisited: An Exploration to Repair the Model Parameter Randomisation Test
Jan 12, 2024The Model Parameter Randomisation Test (MPRT) is widely acknowledged in the eXplainable Artificial Intelligence (XAI) community for its well-motivated evaluative principle: that the explanation function should be sensitive to changes in the parameters of the model function. However, recent works have identified several methodological caveats for the empirical interpretation of MPRT. To address these caveats, we introduce two adaptations to the original MPRT -- Smooth MPRT and Efficient MPRT, where the former minimises the impact that noise has on the evaluation results through sampling and the latter circumvents the need for biased similarity measurements by re-interpreting the test through the explanation's rise in complexity, after full parameter randomisation. Our experimental results demonstrate that these proposed variants lead to improved metric reliability, thus enabling a more trustworthy application of XAI methods.
Layer-wise Feedback Propagation
Aug 23, 2023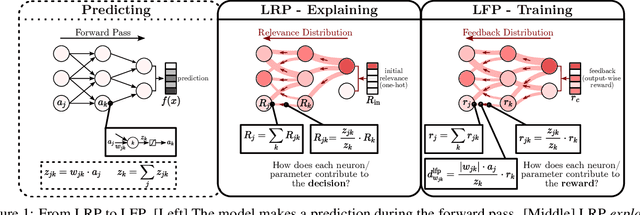
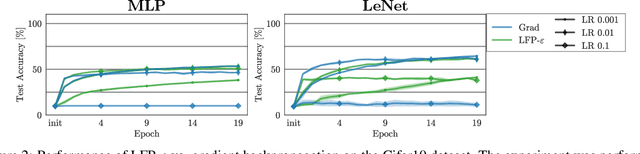
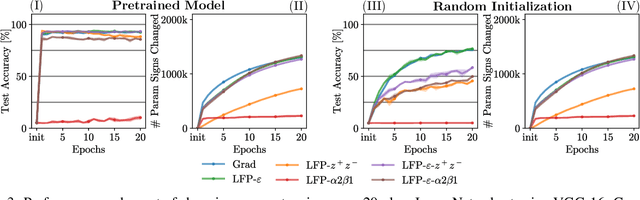
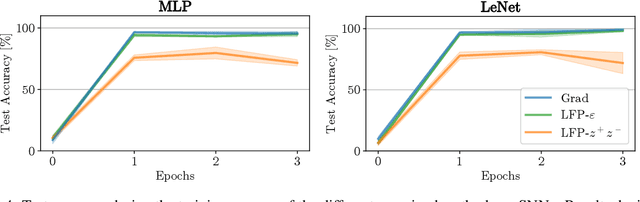
In this paper, we present Layer-wise Feedback Propagation (LFP), a novel training approach for neural-network-like predictors that utilizes explainability, specifically Layer-wise Relevance Propagation(LRP), to assign rewards to individual connections based on their respective contributions to solving a given task. This differs from traditional gradient descent, which updates parameters towards anestimated loss minimum. LFP distributes a reward signal throughout the model without the need for gradient computations. It then strengthens structures that receive positive feedback while reducingthe influence of structures that receive negative feedback. We establish the convergence of LFP theoretically and empirically, and demonstrate its effectiveness in achieving comparable performance to gradient descent on various models and datasets. Notably, LFP overcomes certain limitations associated with gradient-based methods, such as reliance on meaningful derivatives. We further investigate how the different LRP-rules can be extended to LFP, what their effects are on training, as well as potential applications, such as training models with no meaningful derivatives, e.g., step-function activated Spiking Neural Networks (SNNs), or for transfer learning, to efficiently utilize existing knowledge.
Shortcomings of Top-Down Randomization-Based Sanity Checks for Evaluations of Deep Neural Network Explanations
Nov 22, 2022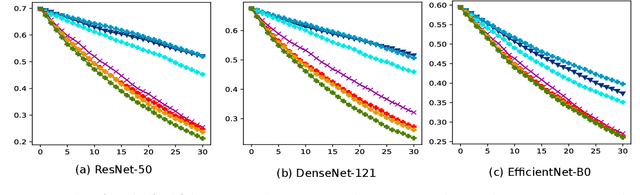
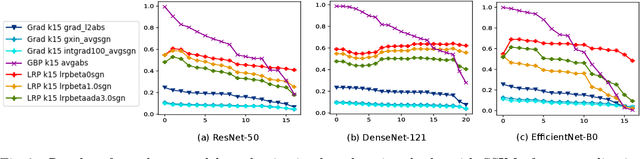
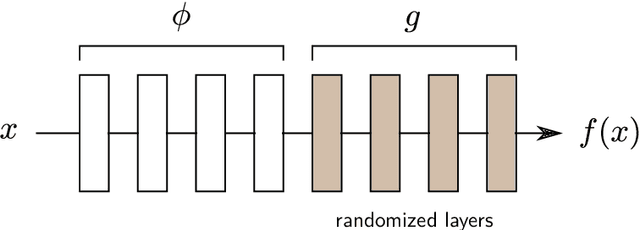
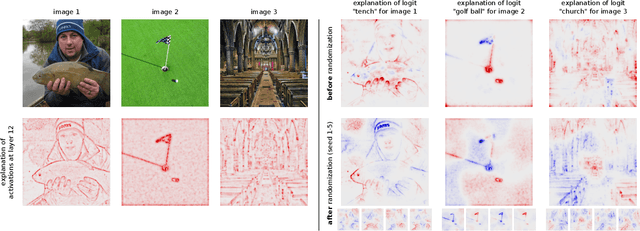
While the evaluation of explanations is an important step towards trustworthy models, it needs to be done carefully, and the employed metrics need to be well-understood. Specifically model randomization testing is often overestimated and regarded as a sole criterion for selecting or discarding certain explanation methods. To address shortcomings of this test, we start by observing an experimental gap in the ranking of explanation methods between randomization-based sanity checks [1] and model output faithfulness measures (e.g. [25]). We identify limitations of model-randomization-based sanity checks for the purpose of evaluating explanations. Firstly, we show that uninformative attribution maps created with zero pixel-wise covariance easily achieve high scores in this type of checks. Secondly, we show that top-down model randomization preserves scales of forward pass activations with high probability. That is, channels with large activations have a high probility to contribute strongly to the output, even after randomization of the network on top of them. Hence, explanations after randomization can only be expected to differ to a certain extent. This explains the observed experimental gap. In summary, these results demonstrate the inadequacy of model-randomization-based sanity checks as a criterion to rank attribution methods.
Explain to Not Forget: Defending Against Catastrophic Forgetting with XAI
May 11, 2022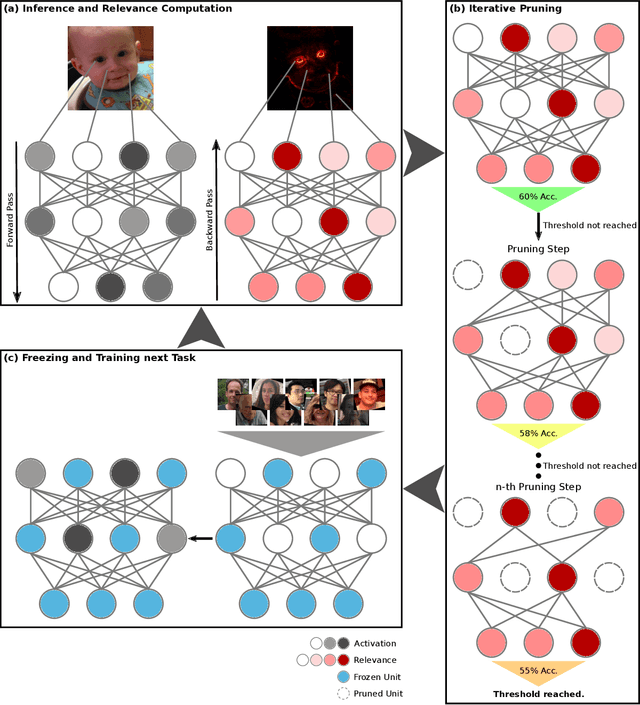
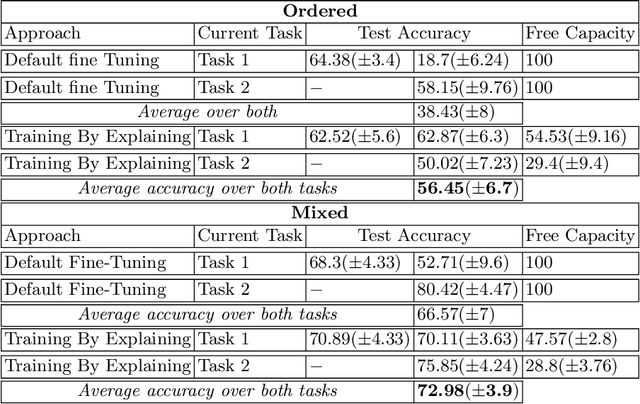
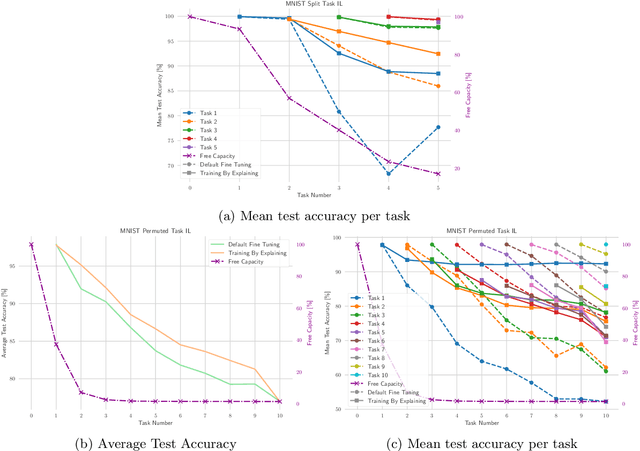
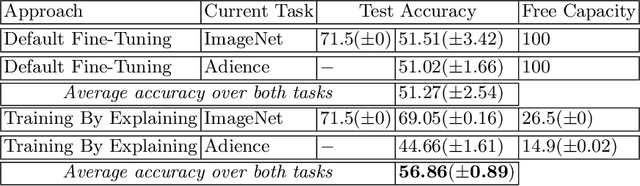
The ability to continuously process and retain new information like we do naturally as humans is a feat that is highly sought after when training neural networks. Unfortunately, the traditional optimization algorithms often require large amounts of data available during training time and updates wrt. new data are difficult after the training process has been completed. In fact, when new data or tasks arise, previous progress may be lost as neural networks are prone to catastrophic forgetting. Catastrophic forgetting describes the phenomenon when a neural network completely forgets previous knowledge when given new information. We propose a novel training algorithm called training by explaining in which we leverage Layer-wise Relevance Propagation in order to retain the information a neural network has already learned in previous tasks when training on new data. The method is evaluated on a range of benchmark datasets as well as more complex data. Our method not only successfully retains the knowledge of old tasks within the neural networks but does so more resource-efficiently than other state-of-the-art solutions.
Beyond Explaining: Opportunities and Challenges of XAI-Based Model Improvement
Mar 15, 2022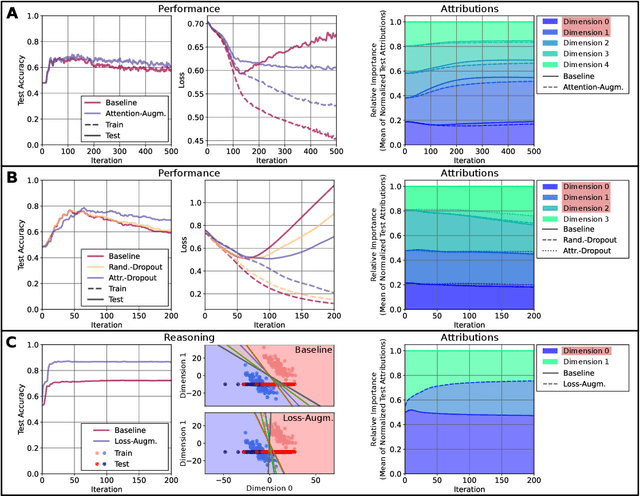

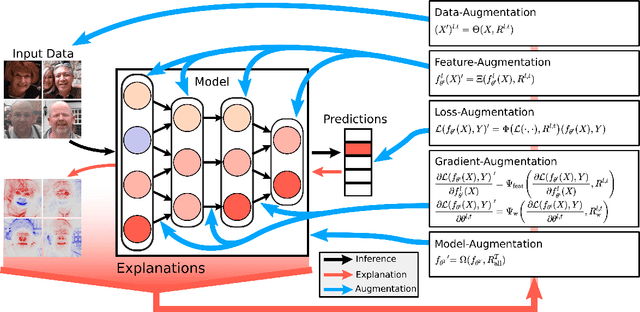

Explainable Artificial Intelligence (XAI) is an emerging research field bringing transparency to highly complex and opaque machine learning (ML) models. Despite the development of a multitude of methods to explain the decisions of black-box classifiers in recent years, these tools are seldomly used beyond visualization purposes. Only recently, researchers have started to employ explanations in practice to actually improve models. This paper offers a comprehensive overview over techniques that apply XAI practically for improving various properties of ML models, and systematically categorizes these approaches, comparing their respective strengths and weaknesses. We provide a theoretical perspective on these methods, and show empirically through experiments on toy and realistic settings how explanations can help improve properties such as model generalization ability or reasoning, among others. We further discuss potential caveats and drawbacks of these methods. We conclude that while model improvement based on XAI can have significant beneficial effects even on complex and not easily quantifyable model properties, these methods need to be applied carefully, since their success can vary depending on a multitude of factors, such as the model and dataset used, or the employed explanation method.
Quantus: An Explainable AI Toolkit for Responsible Evaluation of Neural Network Explanations
Feb 14, 2022
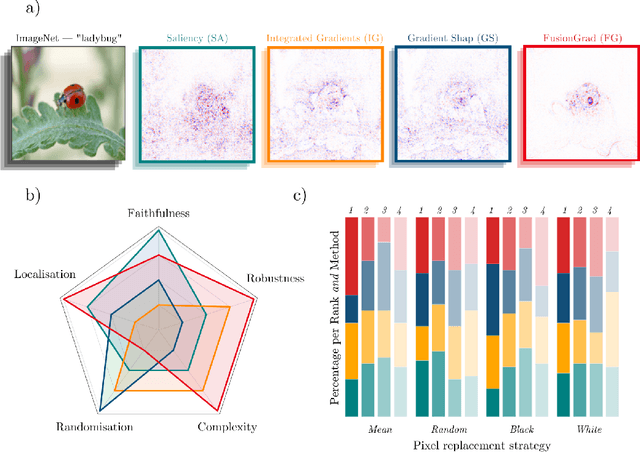
The evaluation of explanation methods is a research topic that has not yet been explored deeply, however, since explainability is supposed to strengthen trust in artificial intelligence, it is necessary to systematically review and compare explanation methods in order to confirm their correctness. Until now, no tool exists that exhaustively and speedily allows researchers to quantitatively evaluate explanations of neural network predictions. To increase transparency and reproducibility in the field, we therefore built Quantus - a comprehensive, open-source toolkit in Python that includes a growing, well-organised collection of evaluation metrics and tutorials for evaluating explainable methods. The toolkit has been thoroughly tested and is available under open source license on PyPi (or on https://github.com/understandable-machine-intelligence-lab/quantus/).
Measurably Stronger Explanation Reliability via Model Canonization
Feb 14, 2022
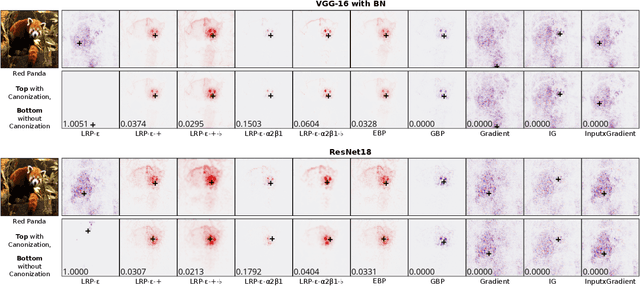

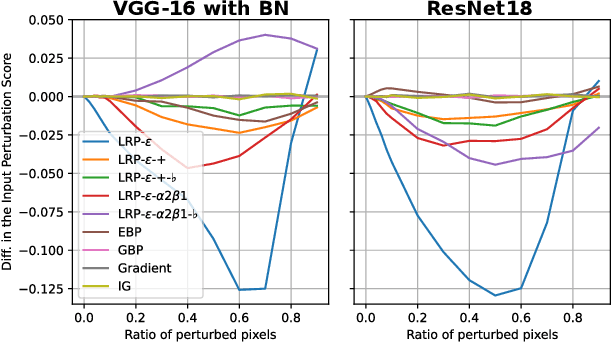
While rule-based attribution methods have proven useful for providing local explanations for Deep Neural Networks, explaining modern and more varied network architectures yields new challenges in generating trustworthy explanations, since the established rule sets might not be sufficient or applicable to novel network structures. As an elegant solution to the above issue, network canonization has recently been introduced. This procedure leverages the implementation-dependency of rule-based attributions and restructures a model into a functionally identical equivalent of alternative design to which established attribution rules can be applied. However, the idea of canonization and its usefulness have so far only been explored qualitatively. In this work, we quantitatively verify the beneficial effects of network canonization to rule-based attributions on VGG-16 and ResNet18 models with BatchNorm layers and thus extend the current best practices for obtaining reliable neural network explanations.