 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
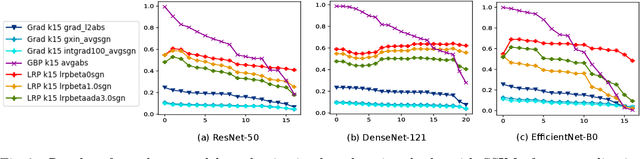
Add to EdgeValue bounds and Convergence Analysis for Averages of LRP attributions
Sep 10, 2025We analyze numerical properties of Layer-wise relevance propagation (LRP)-type attribution methods by representing them as a product of modified gradient matrices. This representation creates an analogy to matrix multiplications of Jacobi-matrices which arise from the chain rule of differentiation. In order to shed light on the distribution of attribution values, we derive upper bounds for singular values. Furthermore we derive component-wise bounds for attribution map values. As a main result, we apply these component-wise bounds to obtain multiplicative constants. These constants govern the convergence of empirical means of attributions to expectations of attribution maps. This finding has important implications for scenarios where multiple non-geometric data augmentations are applied to individual test samples, as well as for Smoothgrad-type attribution methods. In particular, our analysis reveals that the constants for LRP-beta remain independent of weight norms, a significant distinction from both gradient-based methods and LRP-epsilon.
Uncovering the Limitations of Model Inversion Evaluation -- Benchmarks and Connection to Type-I Adversarial Attacks
May 08, 2025


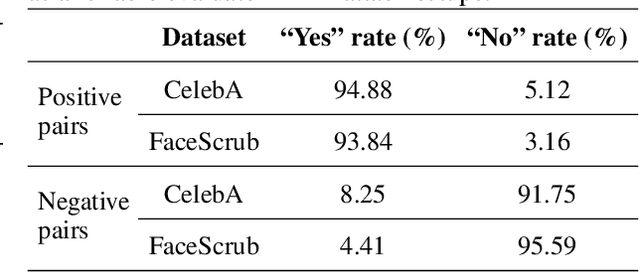
Model Inversion (MI) attacks aim to reconstruct information of private training data by exploiting access to machine learning models. The most common evaluation framework for MI attacks/defenses relies on an evaluation model that has been utilized to assess progress across almost all MI attacks and defenses proposed in recent years. In this paper, for the first time, we present an in-depth study of MI evaluation. Firstly, we construct the first comprehensive human-annotated dataset of MI attack samples, based on 28 setups of different MI attacks, defenses, private and public datasets. Secondly, using our dataset, we examine the accuracy of the MI evaluation framework and reveal that it suffers from a significant number of false positives. These findings raise questions about the previously reported success rates of SOTA MI attacks. Thirdly, we analyze the causes of these false positives, design controlled experiments, and discover the surprising effect of Type I adversarial features on MI evaluation, as well as adversarial transferability, highlighting a relationship between two previously distinct research areas. Our findings suggest that the performance of SOTA MI attacks has been overestimated, with the actual privacy leakage being significantly less than previously reported. In conclusion, we highlight critical limitations in the widely used MI evaluation framework and present our methods to mitigate false positive rates. We remark that prior research has shown that Type I adversarial attacks are very challenging, with no existing solution. Therefore, we urge to consider human evaluation as a primary MI evaluation framework rather than merely a supplement as in previous MI research. We also encourage further work on developing more robust and reliable automatic evaluation frameworks.
Are nuclear masks all you need for improved out-of-domain generalisation? A closer look at cancer classification in histopathology
Nov 14, 2024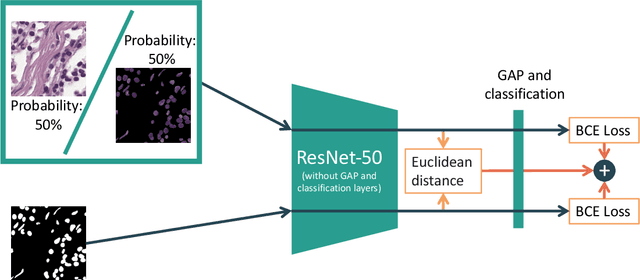


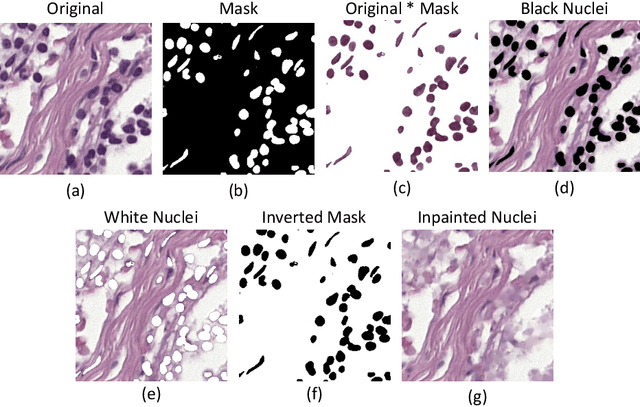
Domain generalisation in computational histopathology is challenging because the images are substantially affected by differences among hospitals due to factors like fixation and staining of tissue and imaging equipment. We hypothesise that focusing on nuclei can improve the out-of-domain (OOD) generalisation in cancer detection. We propose a simple approach to improve OOD generalisation for cancer detection by focusing on nuclear morphology and organisation, as these are domain-invariant features critical in cancer detection. Our approach integrates original images with nuclear segmentation masks during training, encouraging the model to prioritise nuclei and their spatial arrangement. Going beyond mere data augmentation, we introduce a regularisation technique that aligns the representations of masks and original images. We show, using multiple datasets, that our method improves OOD generalisation and also leads to increased robustness to image corruptions and adversarial attacks. The source code is available at https://github.com/undercutspiky/SFL/
Layer-wise Feedback Propagation
Aug 23, 2023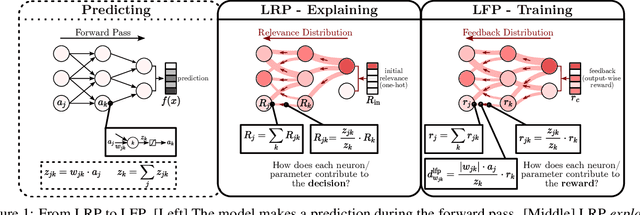
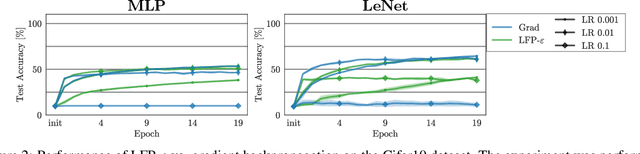
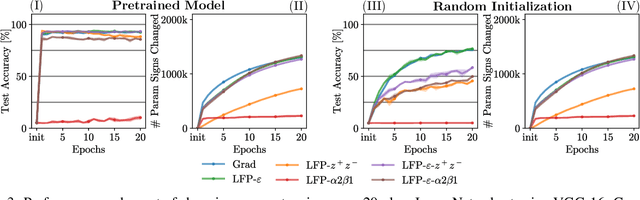
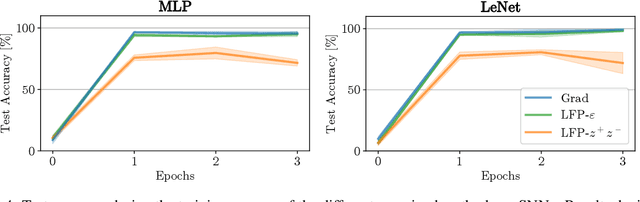
In this paper, we present Layer-wise Feedback Propagation (LFP), a novel training approach for neural-network-like predictors that utilizes explainability, specifically Layer-wise Relevance Propagation(LRP), to assign rewards to individual connections based on their respective contributions to solving a given task. This differs from traditional gradient descent, which updates parameters towards anestimated loss minimum. LFP distributes a reward signal throughout the model without the need for gradient computations. It then strengthens structures that receive positive feedback while reducingthe influence of structures that receive negative feedback. We establish the convergence of LFP theoretically and empirically, and demonstrate its effectiveness in achieving comparable performance to gradient descent on various models and datasets. Notably, LFP overcomes certain limitations associated with gradient-based methods, such as reliance on meaningful derivatives. We further investigate how the different LRP-rules can be extended to LFP, what their effects are on training, as well as potential applications, such as training models with no meaningful derivatives, e.g., step-function activated Spiking Neural Networks (SNNs), or for transfer learning, to efficiently utilize existing knowledge.
Optimizing Explanations by Network Canonization and Hyperparameter Search
Nov 30, 2022Explainable AI (XAI) is slowly becoming a key component for many AI applications. Rule-based and modified backpropagation XAI approaches however often face challenges when being applied to modern model architectures including innovative layer building blocks, which is caused by two reasons. Firstly, the high flexibility of rule-based XAI methods leads to numerous potential parameterizations. Secondly, many XAI methods break the implementation-invariance axiom because they struggle with certain model components, e.g., BatchNorm layers. The latter can be addressed with model canonization, which is the process of re-structuring the model to disregard problematic components without changing the underlying function. While model canonization is straightforward for simple architectures (e.g., VGG, ResNet), it can be challenging for more complex and highly interconnected models (e.g., DenseNet). Moreover, there is only little quantifiable evidence that model canonization is beneficial for XAI. In this work, we propose canonizations for currently relevant model blocks applicable to popular deep neural network architectures,including VGG, ResNet, EfficientNet, DenseNets, as well as Relation Networks. We further suggest a XAI evaluation framework with which we quantify and compare the effect sof model canonization for various XAI methods in image classification tasks on the Pascal-VOC and ILSVRC2017 datasets, as well as for Visual Question Answering using CLEVR-XAI. Moreover, addressing the former issue outlined above, we demonstrate how our evaluation framework can be applied to perform hyperparameter search for XAI methods to optimize the quality of explanations.
Shortcomings of Top-Down Randomization-Based Sanity Checks for Evaluations of Deep Neural Network Explanations
Nov 22, 2022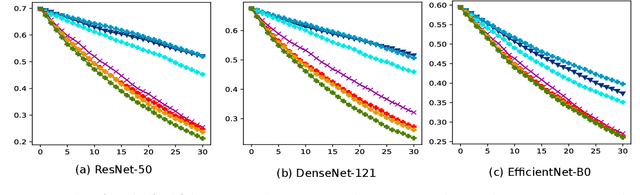
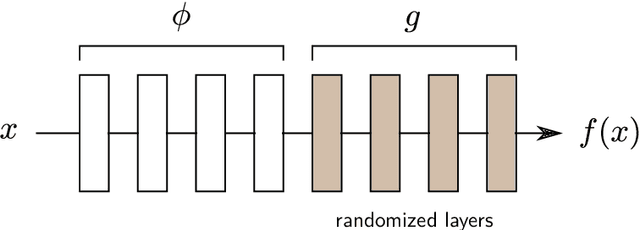
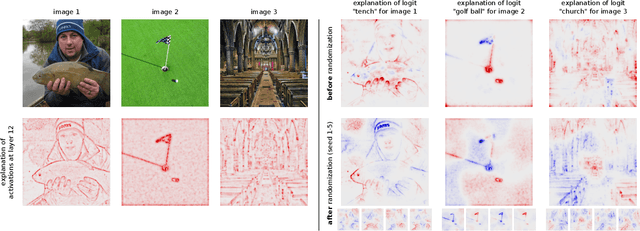
While the evaluation of explanations is an important step towards trustworthy models, it needs to be done carefully, and the employed metrics need to be well-understood. Specifically model randomization testing is often overestimated and regarded as a sole criterion for selecting or discarding certain explanation methods. To address shortcomings of this test, we start by observing an experimental gap in the ranking of explanation methods between randomization-based sanity checks [1] and model output faithfulness measures (e.g. [25]). We identify limitations of model-randomization-based sanity checks for the purpose of evaluating explanations. Firstly, we show that uninformative attribution maps created with zero pixel-wise covariance easily achieve high scores in this type of checks. Secondly, we show that top-down model randomization preserves scales of forward pass activations with high probability. That is, channels with large activations have a high probility to contribute strongly to the output, even after randomization of the network on top of them. Hence, explanations after randomization can only be expected to differ to a certain extent. This explains the observed experimental gap. In summary, these results demonstrate the inadequacy of model-randomization-based sanity checks as a criterion to rank attribution methods.
Discovering Transferable Forensic Features for CNN-generated Images Detection
Aug 24, 2022



Visual counterfeits are increasingly causing an existential conundrum in mainstream media with rapid evolution in neural image synthesis methods. Though detection of such counterfeits has been a taxing problem in the image forensics community, a recent class of forensic detectors -- universal detectors -- are able to surprisingly spot counterfeit images regardless of generator architectures, loss functions, training datasets, and resolutions. This intriguing property suggests the possible existence of transferable forensic features (T-FF) in universal detectors. In this work, we conduct the first analytical study to discover and understand T-FF in universal detectors. Our contributions are 2-fold: 1) We propose a novel forensic feature relevance statistic (FF-RS) to quantify and discover T-FF in universal detectors and, 2) Our qualitative and quantitative investigations uncover an unexpected finding: color is a critical T-FF in universal detectors. Code and models are available at https://keshik6.github.io/transferable-forensic-features/
Beyond Explaining: Opportunities and Challenges of XAI-Based Model Improvement
Mar 15, 2022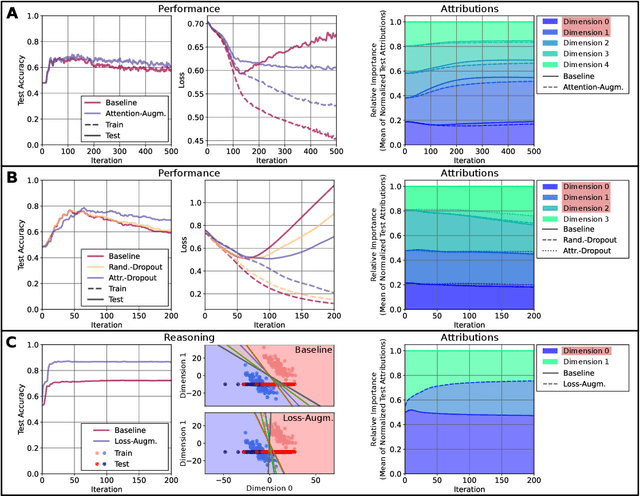

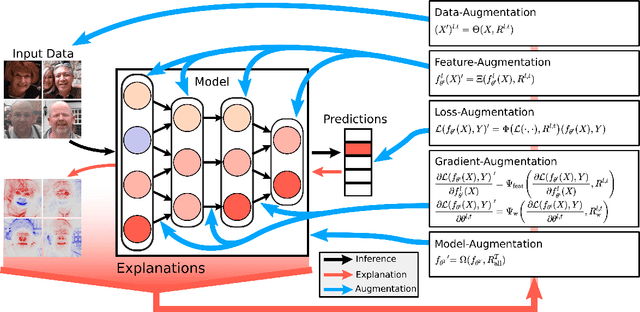

Explainable Artificial Intelligence (XAI) is an emerging research field bringing transparency to highly complex and opaque machine learning (ML) models. Despite the development of a multitude of methods to explain the decisions of black-box classifiers in recent years, these tools are seldomly used beyond visualization purposes. Only recently, researchers have started to employ explanations in practice to actually improve models. This paper offers a comprehensive overview over techniques that apply XAI practically for improving various properties of ML models, and systematically categorizes these approaches, comparing their respective strengths and weaknesses. We provide a theoretical perspective on these methods, and show empirically through experiments on toy and realistic settings how explanations can help improve properties such as model generalization ability or reasoning, among others. We further discuss potential caveats and drawbacks of these methods. We conclude that while model improvement based on XAI can have significant beneficial effects even on complex and not easily quantifyable model properties, these methods need to be applied carefully, since their success can vary depending on a multitude of factors, such as the model and dataset used, or the employed explanation method.
Towards A Conceptually Simple Defensive Approach for Few-shot classifiers Against Adversarial Support Samples
Oct 24, 2021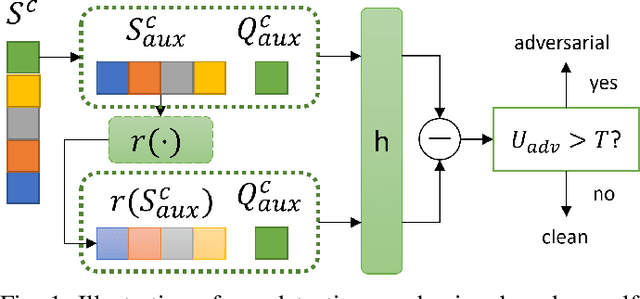
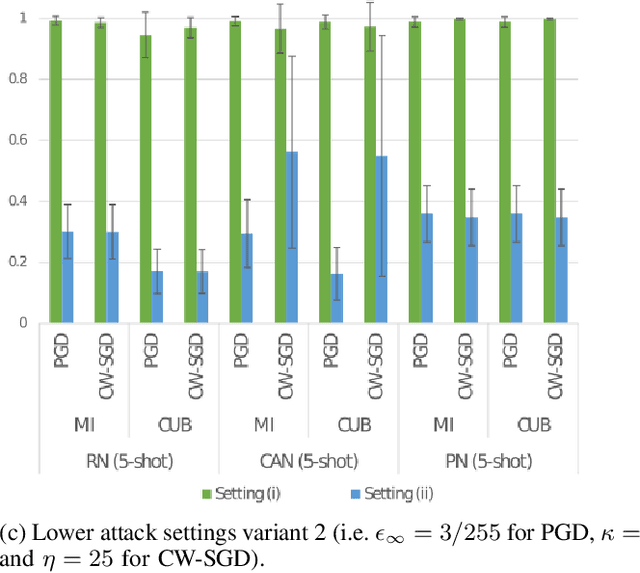
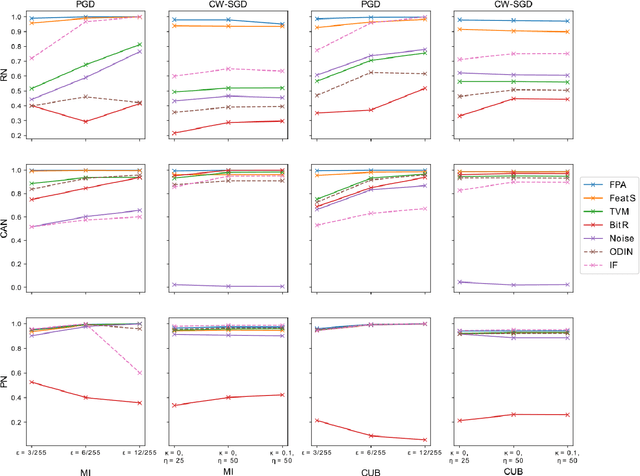
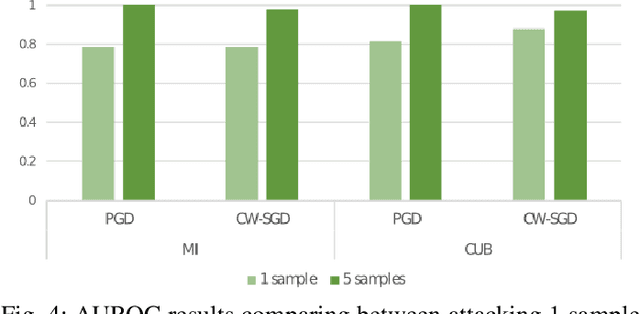
Few-shot classifiers have been shown to exhibit promising results in use cases where user-provided labels are scarce. These models are able to learn to predict novel classes simply by training on a non-overlapping set of classes. This can be largely attributed to the differences in their mechanisms as compared to conventional deep networks. However, this also offers new opportunities for novel attackers to induce integrity attacks against such models, which are not present in other machine learning setups. In this work, we aim to close this gap by studying a conceptually simple approach to defend few-shot classifiers against adversarial attacks. More specifically, we propose a simple attack-agnostic detection method, using the concept of self-similarity and filtering, to flag out adversarial support sets which destroy the understanding of a victim classifier for a certain class. Our extended evaluation on the miniImagenet (MI) and CUB datasets exhibit good attack detection performance, across three different few-shot classifiers and across different attack strengths, beating baselines. Our observed results allow our approach to establishing itself as a strong detection method for support set poisoning attacks. We also show that our approach constitutes a generalizable concept, as it can be paired with other filtering functions. Finally, we provide an analysis of our results when we vary two components found in our detection approach.
On the Robustness of Pretraining and Self-Supervision for a Deep Learning-based Analysis of Diabetic Retinopathy
Jun 25, 2021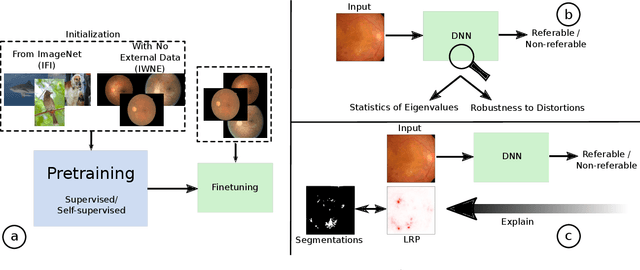

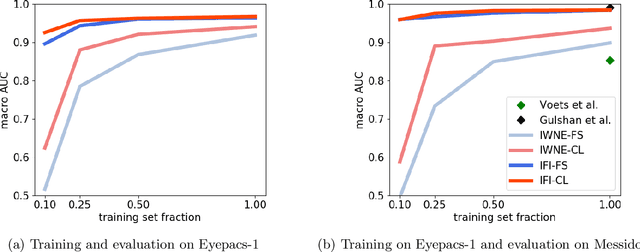
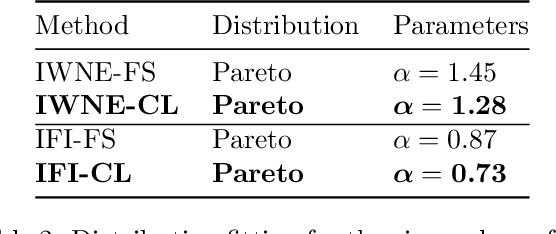
There is an increasing number of medical use-cases where classification algorithms based on deep neural networks reach performance levels that are competitive with human medical experts. To alleviate the challenges of small dataset sizes, these systems often rely on pretraining. In this work, we aim to assess the broader implications of these approaches. For diabetic retinopathy grading as exemplary use case, we compare the impact of different training procedures including recently established self-supervised pretraining methods based on contrastive learning. To this end, we investigate different aspects such as quantitative performance, statistics of the learned feature representations, interpretability and robustness to image distortions. Our results indicate that models initialized from ImageNet pretraining report a significant increase in performance, generalization and robustness to image distortions. In particular, self-supervised models show further benefits to supervised models. Self-supervised models with initialization from ImageNet pretraining not only report higher performance, they also reduce overfitting to large lesions along with improvements in taking into account minute lesions indicative of the progression of the disease. Understanding the effects of pretraining in a broader sense that goes beyond simple performance comparisons is of crucial importance for the broader medical imaging community beyond the use-case considered in this work.